
Рефераты по сексологии
Рефераты по информатике программированию
Рефераты по биологии
Рефераты по экономике
Рефераты по москвоведению
Рефераты по экологии
Краткое содержание произведений
Рефераты по физкультуре и спорту
Топики по английскому языку
Рефераты по математике
Рефераты по музыке
Остальные рефераты
Рефераты по авиации и космонавтике
Рефераты по административному праву
Рефераты по безопасности жизнедеятельности
Рефераты по арбитражному процессу
Рефераты по архитектуре
Рефераты по астрономии
Рефераты по банковскому делу
Рефераты по биржевому делу
Рефераты по ботанике и сельскому хозяйству
Рефераты по бухгалтерскому учету и аудиту
Рефераты по валютным отношениям
Рефераты по ветеринарии
Рефераты для военной кафедры
Рефераты по географии
Рефераты по геодезии
Рефераты по геологии
Рефераты по геополитике
Рефераты по государству и праву
Рефераты по гражданскому праву и процессу
Рефераты по делопроизводству
Рефераты по кредитованию
Рефераты по естествознанию
Рефераты по истории техники
Рефераты по журналистике
Рефераты по зоологии
Рефераты по инвестициям
Рефераты по информатике
Исторические личности
Рефераты по кибернетике
Рефераты по коммуникации и связи
Дипломная работа: Автоматизированная интеллектуальная система классификации информационных сообщений средств массовой информации
Дипломная работа: Автоматизированная интеллектуальная система классификации информационных сообщений средств массовой информации
ДИПЛОМНЫЙ ПРОЕКТ
Выпускная квалификационная работа дипломированного специалиста
Специальность 230102
Автоматизированные системы обработки информации и управления
АВТОМАТИЗИРОВАННАЯ ИНТЕЛЛЕКТУАЛЬНАЯ СИСТЕМА КЛАССИФИКАЦИИ ИНФОРМАЦИОННЫХ СООБЩЕНИЙ СРЕДСТВ МАССОВОЙ ИНФОРМАЦИИ
Содержание
Введение
1. Обзор и анализ существующих систем
2. Общесистемные решения
2.1 Пояснительная записка к техническому проекту
2.2 Описание схемы организационной структуры управления информационных и аналитических технологий аппарата администрации Тульской области
2.3 Описание автоматизируемых функций и схемы функциональной структуры АИС «Классификатор»
2.4 Описание постановки задачи
3 Информационное обеспечение
3.1 Перечень входных данных
3.2 Перечень выходных данных и документов
3.3 Описание информационного обеспечения АИС «Классификатор»
3.4 Описание организации информационной базы
4 Математическое обеспечение
4.1 Математическая постановка задачи классификации информационных сообщений СМИ
4.2 Описание метода нечеткого поиска
4.3 Описание запросов
4.4 Описание схемы работы системы
5. Техническое обеспечение
5.1 Описание комплекса технических средств
5.2 Инструкция по эксплуатации комплекса технических средств
6 Программное обеспечение
6.1 Описание программного обеспечения
6.2 Описание контрольного примера
7 Организационное обеспечение
7.1 Описание организационной структуры
7.2 Руководство пользователя
Библиографический список
Приложения
1. Структура входных и выходных документов
2. Текст программы.
ВВЕДЕНИЕ
При современном уровне развития информационных технологий использование компьютера для хранения любых видов информации становится единственным способом, предоставляющим широчайшие возможности по управлению информацией.
В настоящее время идет постоянный и быстрый рост объемов информации. Значительную часть этой информации составляют текстовые данные. В связи с этим встает проблема создания средств доступа к текстовой информации.
Технически существует возможность доступа к значительной части имеющихся текстов, но практически доступна лишь малая часть. Это связано с несовершенством средств доступа. Современные средства поиска, каталогизации, описания текстов не удовлетворяют нарастающим потребностям пользователей. Требуется их развитие в направлении повышения эффективности поиска информации и упрощения взаимодействия с пользователем.
Возможным путем решения проблемы является создание технико-информационных средств описания смысла имеющихся текстов с возможностью дальнейшего осмысленного поиска в массиве текстовой информации. Причем большие и постоянно увеличивающиеся объемы текстовой информации требуют, чтобы такие средства работали в автоматическом режиме.
Наиболее важным направлением автоматизации деятельности предприятий является использование современных информационных технологий для хранения, систематизации и эффективной обработки информации, поступающей из различных источников, а также использования этой информации в целях выработки рекомендаций для принятия управленческих решений.
Проблема использования большого объема накопленных данных является ключевой во многих организациях. Проблема работы с большим количеством информации имеет два аспекта:
- автоматический сбор информации;
- автоматический разбор поступившей информации по данной тематике, проведенный на основе анализа текста документа.
В связи с этим, во-первых, появляется задача загрузки информации в систему. Процесс загрузки заключается в занесении данных с носителя информации в хранилище данных. Поставляющие информацию оперативные системы далеко не всегда обладают достаточным уровнем качества данных, поэтому процесс загрузки этих данных в хранилище не ограничивается простым копированием, а включает в себя очистку, согласование и контроль качества. Хранилища данных загружают и постоянно обновляют огромные объемы данных из различных источников, поэтому вероятность попадания в них "грязных данных" весьма высока. Поэтому появляется проблема поиска и выборки необходимой информации из больших массивов текстовых данных.
Эффективность поиска в большом информационном массиве существенно повысится, если его разбить на части по некоторому критерию, связанному с целями поиска. Следовательно, во-вторых, появляется проблема классификации сообщений. Для решения задачи анализа текстовой информации и последующего автоматического распределения ее по требуемым тематикам необходимо в первую очередь сформировать рубрикатор, то есть задать список рубрик и словарь, наиболее точно характеризующие исследуемую область знаний. Классификация документов позволяет сузить область поиска и не только увеличить его скорость, но и значительно повысить точность результатов. Поэтому технологии автоматической классификации документов отводится важное место в системах управления электронным документооборотом.
Суть задачи классификации состоит в автоматическом распределении поступающих в систему документов в зависимости от их типа и содержания по рубрикам.
В настоящее время в структуре областной исполнительной власти ответственность за поддержание информационного тонуса в регионе возложена на управление информационных и аналитических технологий аппарата администрации Тульской области (УИАТ ТО), одной из задач которого является создание условий для удовлетворения информационных потребностей органов власти, населения.
В целях обеспечения информацией органов власти и населения все больше внимание уделяется совершенствованию профессионального мастерства рабочего персонала отдела технологий отображения информации (ОТОИ) УИАТ ТО, повышению оперативности и эффективности работы. ОТОИ осуществляет свою деятельность в сфере управления процессами создания и внедрения передовых информационных технологий и в сфере управления вопросами графической обработки и отображения информации.
Внедрение системы автоматизации в технологические процессы отделов по управлению информацией позволяет максимально использовать их возможности:
- автоматизация процесса загрузки информационных сообщений СМИ в информационную базу системы позволяет улучшить качество данных, выявить и удалить ошибки несоответствий в данных;
- автоматизация процесса поиска позволяет частично снять нагрузку с работника и сократить время по отслеживанию необходимой информации;
- автоматизация процесса классификации информационных сообщений СМИ позволяет автоматически распределить поступающие в систему информационные сообщения в зависимости от их типа и содержания по рубрикам.
Управление процессами в отделах по управлению информацией должно выполняться в режиме реального времени для более успешного развития предприятия. Также необходимы такие возможности, чтобы система быстро реагировала на возникающие изменения.
Одним из путей повышения эффективности деятельности отделов по управлению информацией является совершенствование работы процессов по формированию информации. Поэтому важное место занимает проблема автоматизации работы консультанта ОТОИ, связанной с обработкой информации и присвоение ей классифицирующих атрибутов.
1 ОБЗОР И АНАЛИЗ СУЩЕСТВУЮЩИХ СИСТЕМ КЛАССИФИКАЦИИ ИНФОРМАЦИИ
В настоящее время задача автоматического разнесения информационного потока по тематическим рубрикам является одной из важнейшей в области обработки информации в системах электронного документооборота. Главное внимание при организации работ по управлению информацией сосредоточено на проблему автоматизации процессов классификации информационных сообщений СМИ. Наиболее актуальными являются задачи загрузки информационных сообщений в информационную базу, обработки текстовой и цифровой информации, переход к структурированным сообщениям, оперативная корректировка структуры рубрикатора и словаря.
В настоящее время в отделах документооборота началось активное использование программных продуктов для автоматизации процесса классификации.
Наибольшее распространение в отделах документооборота получили программные продукты: поисково-аналитическая система «Галактика-Зум», система «Термин-5», информационно-аналитическая система «Астарта», информационно-аналитическая система INLINE Technologies.
Каждый из вариантов имеет свои преимущества и недостатки. Наиболее распространенные зарубежные системы хорошо отлажены, но имеют гораздо более высокую стоимость, недостаточно приспособлены к принятым в организациях технологиям, стандартам и форматам, что требует их серьезной и дорогостоящей адаптации.
Отставание отечественных систем объясняется в основном тем, что при отсутствии значительных финансовых инвестиций российские системы используют в качестве базового программного обеспечения бесплатные или дешевые пакеты программ, которые не предназначены для создания высокотехнологичных систем.
Учитывая сложившуюся ситуацию, целесообразно осуществить анализ отечественных систем с целью доработки их до уровня полной конкурентоспособности.
Рассмотрим ряд автоматизированных систем по процессу классификации информации.
Поисково-аналитическая система «Галактика-Зум» предназначена для компаний и организаций, которым необходимо автоматизировать процесс классификации.
Программа предоставляет следующие возможности:
- определение «информационного портрета» запрашиваемой темы, то есть набор упорядоченных по значимости ключевых слов и словосочетаний, характерный именно для данной выборки;
- решение задачи ранжирования документов выборки по значимости – по наибольшему соответствию инфопортрету выборки количества значимых тем и их ранга в рассматриваемом документе;
- корректирование полученных инфопортретов;
- сравнение инфопортрета документа с инфопортретами рубрик, с отсечение малохарактерных инфопортретов.
Информационно-аналитическая система «Астарта» предназначена для компаний и организаций, которым необходимо автоматизировать и кардинальным образом повысить эффективность сбора, обработки и анализа неструктурированной информации, получаемой из Интернета, печатных материалов, СМИ и т.д. Программное решение базируется на технологии «Евфрат» и предназначено для сбора, обработки и анализа неструктурированной информации, получаемой из Интернета, печатных материалов СМИ и других источников.
К недостаткам данных систем можно отнести следующее:
- неудобный для работы интерфейс;
- отсутствие достаточно полного словаря для процесса классификации информационных сообщений;
- отсутствие необходимых для эффективной работы функций формирования рекомендаций для принятия решений и отчетов.
Таким образом, учитывая возможности и недостатки существующих систем, необходимо разработать систему, которая предоставляла бы следующие возможности:
- создание информационной базы для автоматизированного процесса классификации статей по категориям рубрикатора;
- загрузка информационных сообщений СМИ в информационную базу;
- обработка текстовой и цифровой информации с использованием метода нечеткого поиска;
- классификация информационных сообщений с использованием метода ранжирования;
- возможность оперативной корректировки структуры рубрикатора и словаря;
- формирование рекомендаций для принятия решений;
- формирование отчетов.
2 ОБЩЕСИСТЕМНЫЕ РЕШЕНИЯ
2.1 Пояснительная записка к техническому проекту
Полное наименование системы: Автоматизированная интеллектуальная система классификации информационных сообщений средств массовой информации (СМИ). Условное обозначение: АИС «Классификатор».
Заказчик: Управление информационных и аналитических технологий аппарата администрации Тульской области (УИАТ ТО), отдел технологий отображения информации (ОТОИ).
Разработчик: студентка Тульского государственного университета факультета Экономики и права кафедры Автоматизированных информационных и управляющих систем группы 730211 Жиренкова Ирина Юрьевна.
Плановые сроки начала и окончания работы по созданию системы:
- начало работ: 1 сентября 2006 года;
- окончание работ: 1 декабря 2006 года.
Разрабатываемая АИС «Классификатор» предназначена для обеспечения более удобной, эффективной и качественной работы консультанта ОТОИ, связанной с обработкой информации и присвоение ей классифицирующих атрибутов.
Целью создания системы является автоматизация процесса классификации информационных сообщений СМИ. Система позволит освободить человека от необходимости рутинной работы по отслеживанию необходимой информации, принадлежащей к той или иной рубрике, а также сократить время на их обработку.
АИС «Классификатор» включает в себя следующие подсистемы:
1) подсистема ведения информационной базы;
2) подсистема обработки информационных сообщений СМИ;
3) подсистема настройки параметров;
4) подсистема классификации информационных сообщений СМИ.
Подсистема ведения информационной базы должна выполнять следующие функции:
1) формирование информационной базы;
2) добавление записи;
3) изменение записи;
4) удаление записи;
5) сохранение записи.
Подсистема обработки информационных сообщений СМИ должна выполнять следующие функции:
1) открытие списка текстовых файлов в каталоге;
2) открытие файла;
3) считывание строки из файла;
4) запись информационных сообщений СМИ в базу;
5) закрытие файла.
Подсистема настройки параметров должна выполнять следующие функции:
1) определение каталога с файлами;
2) настройка расширения файлов с исходными данными;
3) настройка параметров классификации.
Подсистема классификации информационных сообщений СМИ должна выполнять следующие функции:
1) поиск записей по различным ключам словаря с помощью метода нечеткого поиска;
2) классификация сообщений по результатам поиска;
3) формирование рекомендаций для принятия решений;
4) формирование отчетов.
Информационное обеспечение организовано в соответствии с принципами развития, совместимости, стандартизации и унификации.
Входными данными являются:
- информационные сообщения СМИ;
- параметры классификации;
- рубрикатор тем;
- словарь.
Выходными данными являются результаты классификации информационных сообщений СМИ.
Выходными документами являются:
- отчет по результатам классификации;
- отчет по обработанным сообщениям СМИ.
АИС «Классификатор» была разработана в среде программирования Borland Delphi 7.0, основным инструментом которого является Object Pascal. На магнитных носителях сведения о сообщениях хранятся в виде базы, которая разработана в системе MS Access. Сами информационные сообщения хранятся в файлах на жестком диске. Программное обеспечение реализовано с помощью модульного принципа и функционирует независимо от аппаратной части.
Для функционирования АИС «Классификатор» разработан комплекс технических средств, включающий в себя ПЭВМ на базе процессора Intel Celeron с тактовой частотой 2 ГГц, клавиатуру, мышь, монитор SVGA, 2 Гбайт на жестком диске, 512 Мбайт оперативной памяти (RAM), операционную систему Windows Me, 2000, XP.
Для ввода системы в эксплуатацию необходима персональная ЭВМ с набором периферийных устройств рабочего места. Также необходимо провести ознакомление консультанта ОТОИ с принципами работы данной системы.
2.2 Описание схемы организационной структуры управления информационных и аналитических технологий аппарата администрации Тульской области
Руководит управлением информационных и аналитических технологий аппарата администрации Тульской области начальник управления. В непосредственном подчинении у начальника находится заместитель начальника управления. У заместителя в подчинении определенное количество подразделений (отделов). Схема организационной структуры управления информационных и аналитических технологий приведена на рисунке 2.1.
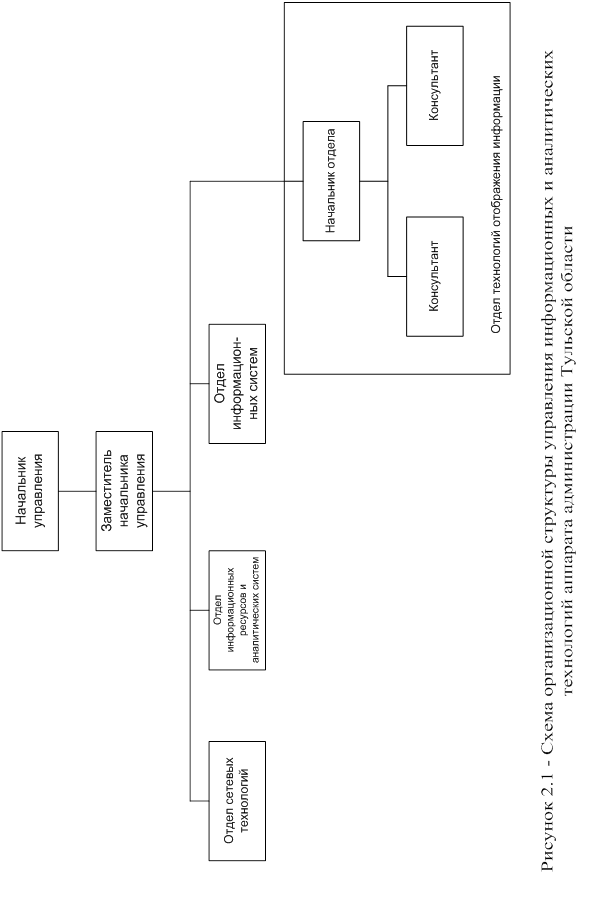
ОТОИ осуществляет свою деятельность в сфере управления процессами создания и внедрения передовых информационных технологий и в сфере управления вопросами графической обработки и отображения информации.
Основными задачами и функциями отдела являются:
- участие в подготовке управленческих решений (нормативно-правовых актов губернатора и администрации Тульской области) в сфере информатизации;
- участие в организации информационного взаимодействия федеральных и региональных органов власти, органов местного самоуправления путем отработки технологии изготовления и распространения информационных и информационно-правовых электронных и печатных бюллетеней и сборников;
- подготовка справочных, информационных и аналитических материалов в целях повышения информированности и компетентности представителей органов власти;
- сбор и обработка информации о деятельности органов исполнительной власти, аппарата администрации Тульской области, органов местного самоуправления региона в целях создания государственных информационных ресурсов;
- техническое, информационное, лингвистическое, организационное участие в наполнении сайта (портала) администрации Тульской области, включая разработку интернет-страниц;
- подготовка предложений по применению в органах исполнительной власти новых технических средств и компьютерных технологий ввода, обработки и отображения графической, текстовой, гипертекстовой, аудио- и видеоинформации;
- подготовка информационных материалов для публикации в федеральных изданиях.
В целях организации информационного обмена между структурными подразделениями областной администрации, муниципальными образованиями области и органами власти регионов экономического Центра России
осуществляется выпуск информационно-правового периодического издания «Вестник администрации Тульской области», периодических электронных бюллетеней «Опыт регионов» и «В Туле и области».
Подготовка этих материалов включает в себя разработку тематики и композиционной структуры каждого выпуска, стилистическое и техническое редактирование материалов.
Основополагающими принципами организации выпуска информационных материалов являются:
- соответствие задачам, решаемым местными органами власти;
- оперативность и достоверность предоставляемой информации;
- читабельность выпускаемых материалов (техническая грамотность, доходчивость изложения, лаконичность).
Необходимо автоматизировать работу консультанта, который от Центра правительственной связи (ЦПС) по Тульской области регулярно получает объемный массив информации, основанный на публикациях СМИ различных регионов. Перед специалистом департамента стоит задача переработать его до читабельного объема и удобной для пользователей формы.
Должностная инструкция консультанта отдела технологий отображения информации
1. Эффективно организует служебную деятельность во взаимосвязи с государственными органами и органами местного самоуправления Тульской области, государственными и муниципальными служащими Тульской области, организациями, гражданами.
2. Владеет современными средствами, методами и технологией работы с информацией и документами.
3. Владеет оргтехникой и средствами коммуникации.
4. Разрабатывает проекты законов и иных нормативных правовых актов по направлению деятельности.
5. Ведет служебный документооборот, исполняет служебные документы, подготавливает проекты ответов на обращения организаций, граждан.
6. Систематизирует и подготавливает аналитический, информационный материал, в том числе для средств массовой информации.
7. Осуществляет сбор, обработку и предоставление информации о деятельности региональных и муниципальных органов власти области в виде информационных (электронных и печатных) бюллетеней, сборников, буклетов и т.д.
8. Подготавливает материалы для сайта (портала) администрации Тульской области.
9. Определяет тематику, сроки предоставления и оформления аналитических и иных материалов, размещаемых в официальном информационно-правовом издании «Вестник администрации Тульской области», электронных информационных бюллетенях и на сайте администрации области.
2.3 Описание автоматизируемых функций и схемы функциональной структуры АИС «Классификатор»
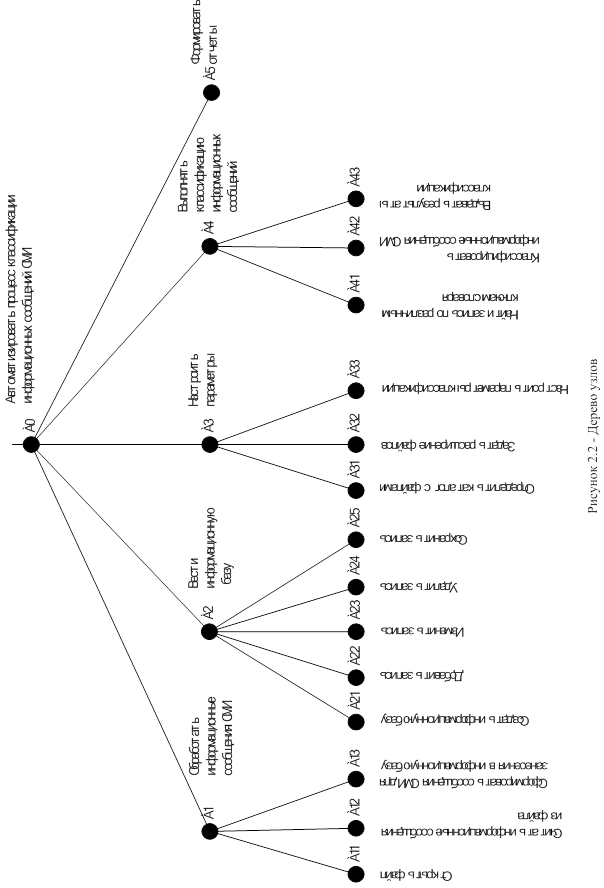
Используя методологию IDEF0 при проектировании АИС «Классификатор» была получена ее функциональная модель.
Главной функцией системы (А0) является автоматизация процесса классификации информационных сообщений СМИ. Для реализации данной функции необходимо реализовать следующие функции:
А0 Автоматизировать процесс классификации информационных сообщений СМИ
А1 Обработать информационные сообщения СМИ
А11 Открыть файл
А12 Считать информационные сообщения из файла
А13 Сформировать сообщения СМИ для занесения в информационную базу
А2 Вести информационную базу
А21 Создать информационную базу
А22 Добавить запись
А23 Изменить запись
А24 Удалить запись
А25 Сохранить запись
А3 Настроить параметры
А31 Определить каталог с файлами
А32 Задать расширение файлов
А33 Настроить параметры классификации
А4 Выполнять классификацию информационных сообщений СМИ
А41 Найти запись по различным ключам словаря
А42 Классифицировать информационных сообщений СМИ
А43 Выдавать результаты классификации
А5 Формировать отчеты
Дерево узлов, разработанной модели представлено на рисунке 2.2. Контекстная диаграмма А–0 и ее дочерние диаграммы представлены в приложении Б.
2.4 Описание постановки задачи
Целью создания системы является автоматизация процесса классификации информационных сообщений СМИ. Комплекс задач, реализуемых разрабатываемой системой, должен обеспечивать удобную, быструю и качественную работу консультанта ОТОИ.
Основными задачами АИС «Классификатор» будут следующие:
- создание информационной базы для автоматизированного процесса классификации статей к той или иной категории;
- загрузка информационных сообщений СМИ в базу;
- обработка текстовой и цифровой информации с использованием метода нечеткого поиска;
- классификация информационных сообщений с использованием метода ранжирования;
- открытость структуры рубрикатора и словаря, то есть возможность оперативной их корректировки;
- формирование рекомендаций для принятия решений;
- формирование отчетов.
Входной информацией для реализации задач системы являются:
- информационные сообщения СМИ;
- параметры классификации;
- рубрикатор тем;
- словарь.
Выходными данными являются результаты классификации информационных сообщений СМИ.
Выходными документами являются:
- отчет по результатам классификации;
- отчет по обработанным сообщениям СМИ.
3 ИНФОРМАЦИОННОЕ ОБЕСПЕЧЕНИЕ
3.1 Перечень входных данных
Для разработки АИС «Классификатор» используются следующие входные данные:
- информационные сообщения СМИ;
- параметры классификации;
- рубрикатор тем;
- словарь.
3.2 Перечень выходных данных и документов
Выходными данными будут результаты классификации информационных сообщений СМИ.
Выходными документами будут:
- отчет по результатам классификации;
- отчет по обработанным сообщениям СМИ.
3.3 Описание информационного обеспечения АИС «Классификатор»
3.3.1 Описание структуры входных информационных сообщений и выходных данных и документов
Информационные сообщения СМИ подготавливаются в виде текстовых файлов.
Текстовые файлы формируются в формате MS DOS в кодировке ASCII.
Имя текстового файла состоит из собственного имени, занимающего 6 знакомест, и 3 символов расширения. Порядок образования имени текстового файла имеет следующую структуру:
ГГЧЧММ.smi,
где ГГ - наименование города, из которого пришло информационное сообщение (2 знакоместа);
ЧЧ - число месяца (2 знакоместа), за которое подготовлено информационное сообщение;
ММ - месяц, в котором подготовлено информационное сообщение;
smi – расширение информационного сообщения СМИ.
3.3.2 Описание структуры информационной части сообщения СМИ
Текстовый файл сформирован без разбиения на страницы с сохранением оригинальной структуры публикаций (абзацы, красные строки и др.).
В состав текстового файла может входить несколько информационных сообщений.
При формировании текстового файла с 1-ой позиции на отдельной строке без пропуска строк введена информационная часть сообщения.
Информационная часть сообщения имеет следующую структуру:
АО ХХХХХХХ
==/СМИ
01/ХХХХ
02/ДДММГГ
03/ХХХХХХХХ
04/ХХХХХХХХ
05/ХХ
06/ключевые слова и текст статьи
07/наименование статьи
08/автор статьи
===
где АО ХХХХХХХ – адрес отправителя;
АО - заглавные буквы русского алфавита;
ХХХХХХХ - семизначный код отправителя.
Между буквами (АО) и кодом допускается один пробел.
==/ - признак начала информационной части (два символа "равно" и слеш - справа налево);
СМИ - принадлежность сообщения СМИ.
Каждое информационное сообщение отделяется этим набором символов.
Далее заполняются атрибуты с 1-й позиции по 8-ю:
01/ - четырехзначный код источника информации (код или наименование газеты);
02/ - дата публикации в формате ДДММГГ;
03/ - шести- или восьмизначный код региона;
04/ - наименование населенного пункта (или его 8-разрядный код), о котором пишется в статье газеты.
Атрибут заполняется заглавными буквами без указаний г., п., пгт. Под населенным пунктом подразумевается город, село, но не район области, не район города.
05/ - двузначный код отрасли, о которой идет речь в соответствии с классификатором отраслей. Если в статье газеты затрагивается нескольких отраслей, то код каждой из них дается отдельной строкой с указателем - 05/;
06/ - ключевые слова и текст статьи.
Первая строка атрибута – ключевые слова по тематике, отраженной в статье. Ключевые слова отделяются друг от друга точкой. Например:
Бюджет. Задолженность.
Содержание статьи, отражающее существо затронутой проблемы. Оно имеет неограниченную длину, но с учетом ограничений объема сообщений в сетях. Продолжение статьи во второй и последующих строках начинается с 4-й позиции, длина строки должна быть не более 55 знаков.
07/ - наименование статьи. Заносится в атрибут полностью, как в оригинале статьи газеты;
08/ - автор статьи.
Все значения атрибутов заносятся сразу же после слеша без пропуска пустых знакомест.
=== - признак завершения информационного сообщения (три символа "равно").
Пример заполнения информационной части сообщения приведен в приложении В.
3.3.3 Основные требования, предъявляемые к подготовке сообщений СМИ в части орфографии
К подготовке информационных сообщений СМИ предъявляются следующие требования:
1. Текст сообщения подготавливается в виде текстового файла.
2. Информация в текстовом файле размещается в одну колонку и не форматируется.
3. Текстовый файл формируется без разбиения на страницы с сохранением оригинальной структуры публикаций (абзацы, красные строки и др.).
4. Информация в текстовый файл вводится прописными и строчными буквами как в статье газеты.
5. В текстовый файл вводятся наименование рубрики, подзаголовок (если они присутствуют) и текст статьи отдельными абзацами.
6. Абзацы, перечень пунктов и т.п. в тексте не отделяются "пустой" строкой.
7. Русские слова текста не должны содержать букв латинского алфавита; римские цифры - русских букв.
8. Текст не должен содержать незаконченных предложений и обрывов в словах.
9. В текстовый файл не заносятся:
- рекламные вставки, фотографии, таблицы, графики, диаграммы и другие графические материалы;
- название города, стоящее в начале или в конце текста статьи, так как оно заносится в атрибут 04/;
- спецсимволы, отсутствующие на клавиатуре ПЭВМ.
Если в конце текста статьи имеется ссылка на источник, из которого напечатан текст, то она заносится на первой строке перед текстом. Например:
По материалам российского радио.
10. Если к статье газеты дается аннотация или комментарий, выделенные
другим шрифтом, заключенные или не заключенные в рамку, то они вводятся после текста статьи в обычном шрифте без рамки, отделяя словами:
Комментарий (фамилия автора).
11. Фамилия от инициалов отделяется пробелом.
12. Слова текста, напечатанные в разрядку (через пробел) вводятся слитно. Ключевые слова в тексте должны быть полными без разрывов и сокращения.
13. Аббревиатуры вводятся без точек и разрядки.
14. Сокращения типа: т.д., т.п., с.г., т.г. вводятся без разрядки.
15. В числах между цифрами не должно быть пробелов.
16. Римские цифры вводить на латинском регистре большими буквами. Например: XXIV.
17. Спецсимволы, встречающиеся в математических формулах, должны быть заменены на буквы русского или латинского алфавита.
18. Химические элементы, единицы измерения, математические выражения и прочая информация вводится в текстовый файл в соответствии с таблицей значений (приложение Г).
19. Примечание (сноска) вводится в текстовый файл с красной строки после текста, отделяется чертой. Например:
_________________
(прим.2) - ...
*) ....
20. Если в газете под одним наименованием несколько сообщений из разных регионов, то каждое сообщение оформляется отдельным текстовым файлом.
21. Если статья газеты имеет продолжение в следующем номере газеты, то ее текстовый файл готовится обычным способом, а в конце текста с красной строки вводится: «Продолжение в N ». Если статья является продолжением предыдущего номера газеты, то в начале текста вводится: «Начало в N ».
22. Текст сообщения должен быть отредактирован. Все спецсимволы в
тексте должны быть заменены следующим образом:
- кавычки («») на кавычки (" ");
- номер (№) на номер (латинская буква N);
- длинное тире (¾) на тире (-);
- буква (ё) на букву (е);
- апостроф (') на твердый знак.
Характерными ошибками в текстовых файлах являются:
- орфографические ошибки в русских словах: пропуск букв(ы), лишняя(ие) буква(ы), замена букв(ы), латинская(ие) буква(ы);
- слова написаны слитно без пробела;
- в сложных словосочетаниях пропуск дефиса;
- после сокращения и знаков препинания отсутствует пробел;
- пропуск точки в сокращении и в единицах измерения;
- вместо запятой стоит точка и наоборот;
- вместо номера (латинской буквы N) стоит другой символ.
Параметры классификации включают в себя задание количества совпадений по названию статьи, по тексту статьи и по ключевым словам текста статьи. Здесь же задается порог нечеткого поиска в процентах от 40 до 100. Чем выше процент, тем четче поиск.
Рубрикатор тем представляет собой перечень рубрик на бумажных носителях и имеет следующую структуру:
- рубрики 1-го уровня;
- рубрики 2-го уровня, раскрывающие суть рубрик 1-го уровня;
- рубрики 3-го уровня, раскрывающие суть рубрик 2-го уровня;
- рубрики 4-го уровня, раскрывающие суть рубрик 3-го уровня.
Рубрикам 3-го и 4-го уровней соответствуют свои словари, представляющие собой перечень ключевых слов. Рубрикатор тем и словарь приведены в приложении Д.
Результаты классификации информационных сообщений СМИ содержат код рубрики, наименование рубрики, количество совпадений по названию, тексту, ключевым словам статьи, и окончательный результат
классификации.
Отчет по результатам классификации содержит данные по каждой статье: дату, выбранный файл, название статьи, ключевые слова статьи, автора, текст статьи, количество совпадений по названию, тексту и ключевым словам статьи.
Отчет по обработанным сообщениям СМИ содержит результаты классификации по каждому файлу и включает: дату, название статьи, ключевые слова статьи, автора, текст статьи и сопоставленные рубрики.
Структура выходных данных и документов представлена в приложении Е.
3.4 Описание организации информационной базы
3.4.1 Описание организации внутримашинной базы
Все сведения о сообщениях СМИ хранятся в базе данных, которая состоит из следующих таблиц:
- статьи;
- газета;
- регион;
- отрасль;
- справочник отраслей;
- рубрики;
- классификация;
- рубрикатор 1;
- рубрикатор 2;
- рубрикатор 3;
- рубрикатор 4;
- словарь рубрикатора 3;
- словарь рубрикатора 4.
Их описание представлено в таблицах 3.1 3.13 соответственно.
Таблица 3.1 – Таблица «Статьи»
| Первичный ключ | Атрибуты | Тип данных | Описание |
| Код газеты | Числовой | Длина 2 символа | |
| Код региона | Числовой | Длина 8 символов | |
| Код статьи | Счетчик | Последовательное значение | |
| Уникальный ключ | Наименование | Текстовый | Длина 150 символов |
| Ключевые слова | Текстовый | Длина 255 символов | |
| Текст | Поле MEMO | ||
| Дата | Дата/время | Краткий формат даты | |
| Автор | Текстовый | Длина 150 символов | |
| Файл | Текстовый | Длина 255 символов | |
| Классифицировано | Логический | Истина/ложь |
Таблица 3.2 – Таблица «Газета»
| Первичный ключ | Атрибуты | Тип данных | Описание |
| Уникальный ключ | Код газеты | Числовой | Длина 2 символа |
| Наименование | Текстовый | Длина 150 символов |
Таблица 3.3 – Таблица «Регион»
| Первичный ключ | Атрибуты | Тип данных | Описание |
| Уникальный ключ | Код региона | Числовой | Длина 8 символов |
| Наименование региона | Текстовый | Длина 150 символов |
Таблица 3.4 – Таблица «Отрасль»
| Первичный ключ | Атрибуты | Тип данных | Описание |
| Составной ключ | Код статьи | Числовой | Длинное целое |
| Код отрасли | Числовой | Длинное целое |
Таблица 3.5 – Таблица «Справочник отраслей»
| Первичный ключ | Атрибуты | Тип данных | Описание |
| Уникальный ключ | Код отрасли | Числовой | Длинное целое |
| Наименование | Текстовый | Длина 150 символов |
Таблица 3.6 – Таблица «Рубрики»
| Первичный ключ | Атрибуты | Тип данных | Описание |
| Составной ключ | Код рубрики | Числовой | Длинное целое |
| Код статьи | Числовой | Длинное целое | |
| Уровень рубрики | Числовой | Длинное целое |
Таблица 3.7 – Таблица «Классификация»
| Первичный ключ | Атрибуты | Тип данных | Описание |
| Уникальный ключ | Код статьи | Числовой | Длинное целое |
| Код рубрики | Числовой | Длинное целое | |
| Уровень рубрики | Числовой | Длинное целое | |
| По названию статьи | Числовой | Длинное целое | |
| По ключевым словам | Числовой | Длинное целое | |
| По тексту статьи | Числовой | Длинное целое | |
| Результат | Текстовый | Длина 50 символов |
Таблица 3.8 – Таблица «Рубрикатор 1»
| Первичный ключ | Атрибуты | Тип данных | Описание |
| Уникальный ключ | Код_1 | Счетчик | Последовательное значение |
| Индекс_1 | Числовой | Длинное целое | |
| Наименование_1 | Текстовый | Длина 150 символов |
Таблица 3.9 – Таблица «Рубрикатор 2»
| Первичный ключ | Атрибуты | Тип данных | Описание |
| Уникальный ключ | Код_2 | Счетчик | Последовательное значение |
| Индекс_2 | Числовой | Длинное целое | |
| Наименование_2 | Текстовый | Длина 150 символов | |
| Код_1 | Числовой | Длинное целое |
Таблица 3.10 – Таблица «Рубрикатор 3»
| Первичный ключ | Атрибуты | Тип данных | Описание |
| Уникальный ключ | Код_3 | Счетчик | Последовательное значение |
| Индекс_3 | Числовой | Длинное целое | |
| Наименование_3 | Текстовый | Длина 150 символов | |
| Код_2 | Числовой | Длинное целое |
Таблица 3.11 – Таблица «Рубрикатор 4»
| Первичный ключ | Атрибуты | Тип данных | Описание |
| Уникальный ключ | Код_4 | Счетчик | Последовательное значение |
| Индекс_4 | Числовой | Длинное целое | |
| Наименование_4 | Текстовый | Длина 150 символов | |
| Код_3 | Числовой | Длинное целое |
Таблица 3.12 – Таблица «Словарь рубрикатора 3»
| Первичный ключ | Атрибуты | Тип данных | Описание |
| Уникальный ключ | Код_3 | Числовой | Длинное целое |
| Слова | Текстовый | Длина 255 символов |
Таблица 3.13 – Таблица «Словарь рубрикатора 4»
| Первичный ключ | Атрибуты | Тип данных | Описание |
| Уникальный ключ | Код_4 | Числовой | Длинное целое |
| Слова | Текстовый | Длина 255 символов |
Данные таблицы объединены в инфологическую модель, схема которой представлена на рисунке 3.4.1.
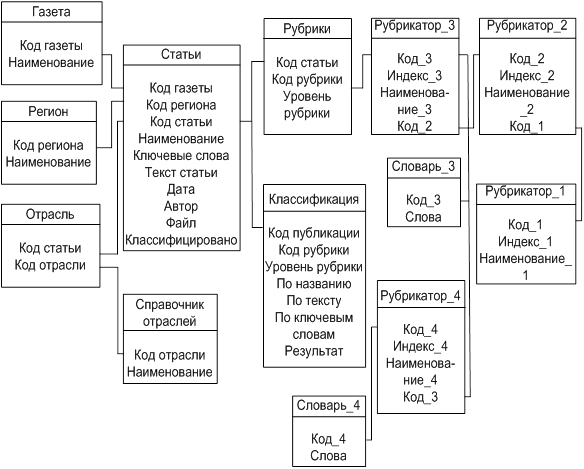
Рисунок 3.4.1 – Инфологическая модель базы
Иерархия заполнения таблиц базы представлена на рисунке 3.4.2.
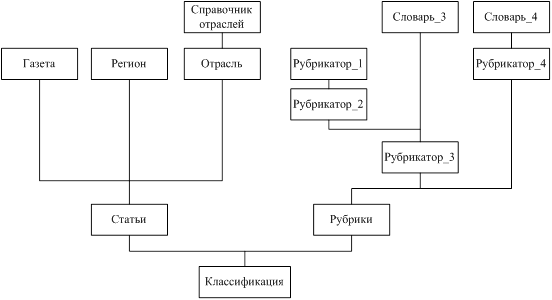
Рисунок 3.4.2 – Иерархия заполнения таблиц базы
4 МАТЕМАТИЧЕСКОЕ ОБЕСПЕЧЕНИЕ
4.1 Математическая постановка задачи классификации информационных сообщений СМИ
Пусть дано множество статей Х, множество ключевых слов статьи W и множество названий статей A. Каждое множество описывается своим набором элементов:
X = {x1, x2, …, xc},
где xi – i- я статья;
c – количество статей;
W = {w1, w2, …, wc},
где wi – строка ключевых слов i-ой статьи, ![]() ;
;
A = {a1, a2, … ac},
где ai – название i-ой статьи, ![]() .
.
Имеется рубрикатор, состоящий из четырех уровней:
R1 = {r11, r12, … r1k},
где k – количество элементов рубрикатора 1;
R2 = {r21, r22, … r2l},
где l – количество элементов рубрикатора 2;
R3 = {r31, r32, … r3m},
где m – количество элементов рубрикатора 3;
R4 = {r41, r42, … r4n},
где n – количество элементов рубрикатора 4.
К каждому элементу рубрикаторов 3-го и 4-го уровней привязаны словари со своими множествами:
D3j = {d31j, d32j, … d3yj}, ![]() ;
;
D4j = {d41j, d42j, … d4zj}, ![]() ,
,
где j – индекс элемента рубрики;
y, z – количество элементов в словаре для конкретной рубрики.
Функция нечеткого поиска задается следующим образом:
![]()
здесь U = {{X},{W},{A}};
dpqj – ключевое слово,
где j – индекс элемента
рубрики, ![]() или
или ![]() ;
;
p – уровень рубрикатора 3-й или 4-й;
q – индекс элементов в словарях D3j и D4j;
![]() или
или ![]() ;
;
pн.п порог нечеткого поиска.
Далее для каждой статьи применяем функцию нечеткого поиска:
![]()
где ![]() - общее количество
совпадений по i-ой статье из словаря 3-го и 4-го уровней;
- общее количество
совпадений по i-ой статье из словаря 3-го и 4-го уровней;
![]()
![]() ;
;
![]() .
.
Затем для ключевых слов статьи также применяем функцию нечеткого поиска:
![]()
где ![]() общее количество
совпадений по строке ключевых слов i-ой статьи из словаря 3-го и 4-го уровней;
общее количество
совпадений по строке ключевых слов i-ой статьи из словаря 3-го и 4-го уровней;
![]()
![]() ;
;
![]() .
.
Для названий статей тоже применяем функцию нечеткого поиска:
![]()
где ![]() - общее количество
совпадений по названию i-ой статьи из словаря 3-го и 4-го уровней;
- общее количество
совпадений по названию i-ой статьи из словаря 3-го и 4-го уровней;
![]()
![]() ;
;
![]() .
.
Далее для отнесения каждой статьи к той или иной рубрике используется метод ранжирования. Для этого определяются границы трех интервалов:
1) статью однозначно нельзя отнести к рубрике;
2) консультант ОТОИ принимает решение о принадлежности статьи к данной рубрике;
3) статья с заданной вероятностью относится к данной рубрике.
Границей является количество слов, которые должны встретиться в тексте, названии статьи или в списке ключевых слов, относящихся к этой статье.
Метод ранжирования заключается в следующем:
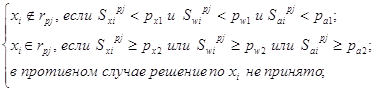
где ![]() границы интервалов по
тексту i-ой статьи;
границы интервалов по
тексту i-ой статьи;
![]() границы интервалов по строке ключевых слов i-ой статьи;
границы интервалов по строке ключевых слов i-ой статьи;
![]() границы интервалов по названию i-ой статьи.
границы интервалов по названию i-ой статьи.
4.2 Описание метода нечеткого поиска
Для нечеткого поиска информации используется алгоритм, основанный на процентном отношении совпадения двух строк. Процесс поиска начинается со сравнения каждого элемента одной строки с каждым элементом другой и заканчивается сравнением строк целиком. Эта процедура повторяется дважды для одной и той же пары строк. В первом случае первая строка принимается за эталон, во втором – вторая. В процессе сравнения подсчитывается число совпадений и общее число рассматриваемых случаев, после чего вычисляется их процентное соотношение. На основе этого соотношения принимается решение считать найденную информацию удовлетворяющей условиям поиска или нет. Описанная процедура применяется ко всем записям информационной базы, в результате пользователь получает всю информацию, удовлетворяющую запросу.
Изменяя минимальный процент совпадения можно уменьшать или увеличивать точность соответствия найденной информации искомой. В данной системе используется 50% совпадения, так как (из практики) этого достаточно для нахождения информации. Схема программы поиска данных по алгоритму нечеткого поиска приведена на рисунке 4.2.1, схема программы сравнения строк приведена на рисунке 4.2.2.
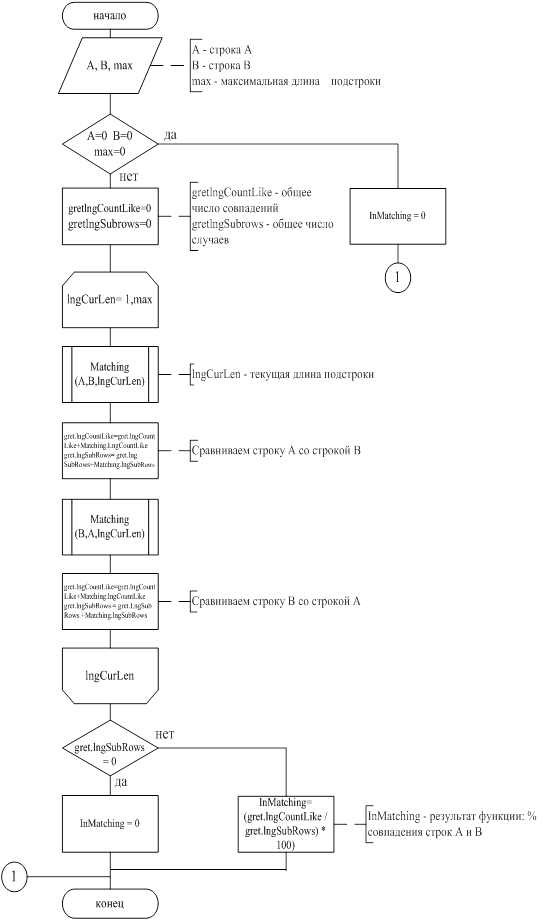
Рисунок 4.2.1 - Схема программы поиска данных по алгоритму нечеткого поиска
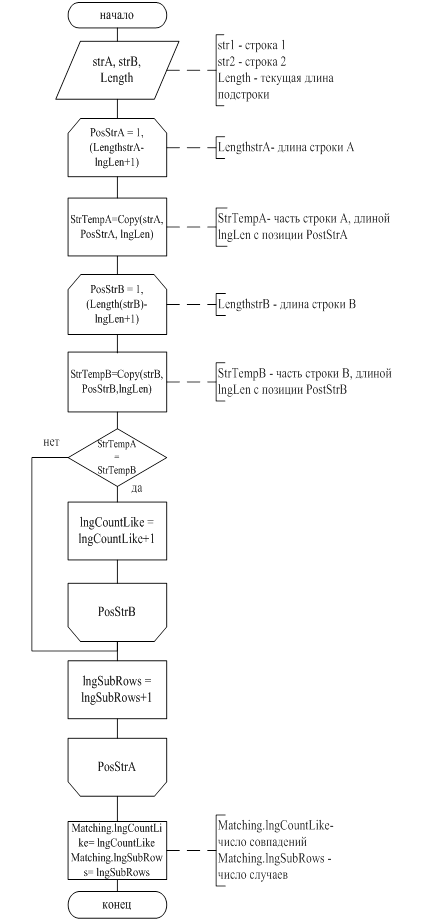
Рисунок 4.2.2 - Схема программы сравнения строк «Matching»
4.3 Описание запросов
Для данной работы необходимо создать следующие запросы: «Рубрикатор», «Классификация 3-го уровня», «Классификация 4-го уровня», «Классифицированные сообщения», «Обработанные сообщения 3-го уровня», «Обработанные сообщения 4-го уровня».
Запрос «Рубрикатор» необходим для вывода всей информации по всем уровням рубрикатора и словарям 3-го и 4-го уровней. Структура запроса «Рубрикатор» в режиме SQL:
SELECTРубрикатор_1.Индекс_1,Рубрикатор_2.Индекс_2,Рубрикатор_3.Индекс_3, IIf(IsNull([Индекс_4]),0,[Индекс_4])ASИндекс_4,Trim(Str([Рубрикатор_1].[Индекс_1]))+"."+Trim(Str([Рубрикатор_2]
[Индекс_2]))+"."+Trim(Str([Рубрикатор_3].[Индекс_3]))+"."+Trim(Str(IIf(IsNull([Индекс_4]),0,[Индекс_4])))+"."AS Индекс, Рубрикатор_1.Наименование_1,Рубрикатор_2.Наименование_2,Рубрикатор_3.Наименование_3, Рубрикатор_4. Наименование_4, Рубрикатор_1.Код_1, Рубрикатор_2.Код_2, Рубрикатор_3.Код_3, Рубрикатор
_4.Код_4
FROM ((Рубрикатор_1 LEFT JOIN Рубрикатор_2 ON Рубрикатор_1.Код_1= Рубрикатор_2.Код_1) LEFT JOIN Рубрикатор_3 ON Рубрикатор_2.Код_2 = Рубрикатор_3.Код_2) LEFT JOIN Рубрикатор_4 ON Рубрикатор_3.
Код_3 = Рубрикатор_4.Код_3
ORDER BY Рубрикатор_1.Индекс_1,Рубрикатор_2.Индекс_2,Рубрикатор_3.Индекс_3, IIf(IsNull ([Индекс_4]), 0,[Индекс_4]);
Запрос «Классификация 3-го уровня» необходим для вывода информации по результатам классификации по 3-му уровню рубрикатора. Структура запроса «Классификация 3-го уровня» в режиме SQL:
SELECT Trim(Str([Рубрикатор_1].[Индекс_1]))+"."+Trim(Str([Рубрикатор_2].[Индекс_2]))+"."+Trim(Str([Рубрикатор_
3].[Индекс_3]))+"."ASИндекс,[Рубрикатор_1].[Наименование_1]+"."+[Рубрикатор_2].[Наименование_2]+"."+[Рубрикатор_3].[Наименование_3]ASНаименованиерубрики,[Классификация].[Уровеньрубрики], [Классификация].
[Наименование статьи], [Классификация].[Текст статьи], [Классификация].[Ключевые слова], [Классификация]. [Результат], [Классификация].[Код статьи], [Рубрикатор_3].[Код_3] AS Код статьи
FROM (Рубрикатор_1 INNER JOIN Рубрикатор_2 ON [Рубрикатор_1].[Код_1]=[Рубрикатор_2].[Код_1]) INNER JOIN (Рубрикатор_3 INNER JOIN Классификация ON [Рубрикатор_3].[Код_3]=[Классификация].[Код рубрики]) ON [Рубрикатор_2].[Код_2]=[Рубрикатор_3].[Код_2]
WHERE ((([Классификация].[Уровень рубрики])=3));
Запрос «Классификация 4-го уровня» необходим для вывода информации по результатам классификации по 4-му уровню рубрикатора. Структура запроса «Классификация 4-го уровня» в режиме SQL:
SELECT Trim(Str(Рубрикатор_1.Индекс_1))+"."+Trim(Str(Рубрикатор_2.Индекс_2))+"."+Trim(Str(Рубрикатор_3.
Индекс_3))+"."+Trim(Str(Рубрикатор_4.Индекс_4))+"."ASИндекс,Рубрикатор_1.Наименование_1+". "+Рубрикатор
_2.Наименование_2+". "+Рубрикатор_3.Наименование_3+"."+Рубрикатор_4.Наименование_4 AS Наименование рубрики, Классификация.Уровень рубрики, Классификация.Наименование статьи, Классификация.Текст статьи, Классификация.Ключевые слова, Классификация.Результат, Классификация.Код рубрики, Рубрикатор_4.Код_4 AS Код статьи FROM ((Рубрикатор_1 INNER JOIN Рубрикатор_2 ON Рубрикатор_1.Код_1=Рубрикатор_2.Код_1) INNER JOIN Рубрикатор_3 ON Рубрикатор_2.Код_2=Рубрикатор_3.Код_2) INNER JOIN (Рубрикатор_4 INNER JOIN Классификация ON Рубрикатор_4.Код_4=Классификация.Код рубрики) ON Рубрикатор_3.Код_3=
Рубрикатор_4.Код_3 WHERE (((Классификация.Уровень рубрики)=4));
Запрос «Классифицированные сообщения» необходим для создания отчета по результатам классификации. Структура запроса «Обработанные сообщения» в режиме SQL:
SELECT DISTINCT Статьи.Код статьи
FROM Статьи INNER JOIN Рубрики ON Статьи.Код статьи = Рубрики.Код рубрики;
Запрос «Обработанные сообщения 3-го уровня» необходим для вывода информации по обработанным сообщениям СМИ, отнесенным к 3-му уровню рубрикатора. Структура запроса «Обработанные сообщения 3-го уровня» в режиме SQL:
SELECT Trim(Str(Рубрикатор_1.Индекс_1))+"."+Trim(Str(Рубрикатор_2.Индекс_2))+"."+Trim(Str(Рубрикатор_3
.Индекс_3))+"." AS Индекс, Статьи.Файл, Статьи.Код газеты, Статьи.Код региона, Статьи.Код статьи, Статьи.Наименование статьи, Статьи.Ключевые слова, Статьи.Текст статьи, Статьи.Дата, Статьи.автор, Статьи.Код рубрики, Статьи.Уровень рубрики, Рубрикатор_1.Наименование_1+"."+Рубрикатор_2.Наименование
_2+". "+Рубрикатор_3. Наименование_3 AS Наименование рубрики
FROM (Рубрикатор_1 INNER JOIN Рубрикатор_2 ON Рубрикатор_1.Код_1 = Рубрикатор_2.Код_1) INNER JOIN (Рубрикатор_3 INNER JOIN Стать ON Рубрикатор_3.Код_3 = Статьи.Код рубрики) ON Рубрикатор_2.Код_2 = Рубрикатор_3.Код_2
WHERE (((Статьи.Уровень рубрики)=3));
Запрос «Обработанные сообщения 4-го уровня» необходим для вывода информации по обработанным сообщениям СМИ, отнесенным к 4-му уровню рубрикатора. Структура запроса «Обработанные сообщения 4-го уровня» в режиме SQL:
SELECT Trim(Str(Рубрикатор_1.Индекс_1))+"."+Trim(Str(Рубрикатор_2.Индекс_2))+"."+Trim(Str(Рубрикатор_3.
Индекс_3))+"."+Trim(Str(Рубрикатор_4.Индекс_4))+"." AS Индекс, Статьи.Файл, Статьи.Код газеты, Статьи.Код региона, Статьи.Код рубрики, Статьи.Наименование статьи, Статьи.Ключевые слова, Статьи.Текст статьи, Статьи.Дата, Статьи.автор, Статьи.Код рубрики, Статьи.Уровень рубрики, Рубрикатор_1.Наименование_1+". "+Рубрикатор_2.Наименование_2+". "+Рубрикатор_3.Наименование_3+"."+Рубрикатор_4.Наименование_4 AS Наименование рубрики
FROM ((Рубрикатор_1 INNER JOIN Рубрикатор_2 ON Рубрикатор_1.Код_1=Рубрикатор_2.Код_1) INNER JOIN Рубрикатор_3 ON Рубрикатор_2.Код_2=Рубрикатор_3.Код_2) INNER JOIN (Рубрикатор_4 INNER JOIN Статьи ON Рубрикатор_4.Код_4=Статьи.Код рубрики) ON Рубрикатор_3.Код_3=Рубрикатор_4.Код_3
WHERE (((Статьи.Уровень рубрики)=4));
4.4 Описание схемы работы системы
Схема работы системы представляет собой последовательность этапов, которую необходимо выполнить для классификации информационных сообщений СМИ.
Работу необходимо начать с загрузки информационных сообщений СМИ
в базу системы, на основе которых будет проводиться классификация. Для загрузки сообщений определяется местоположение каталога с файлами с заданием расширения с исходными информационными сообщениями.
При переходе ко второму этапу необходимо настроить параметры классификации, которые заключаются в определении количества совпадений по названию статьи, по тексту статьи, по ключевым словам статьи. Также необходимо задать порог нечеткого поиска.
На этапе классификации в первую очередь выполняется поиск записей по различным ключам словаря с помощью алгоритма нечеткого поиска. Далее выполняется классификация информационных сообщений СМИ с помощью метода ранжирования, заключающегося в автоматическом распределении поступающих в систему информационных сообщений СМИ в зависимости от их типа и содержания по рубрикам. Результаты классификации выводятся на экран.
По результатам классификации формируются рекомендации для принятия решений и отчеты. Отчеты сохраняются в текстовом файле формата doc.
При выборе завершающего режима работы системы произойдет выход из нее.
Схема работы системы представлена на рисунке 4.4.1.
Текст программы представлен в приложении Е.
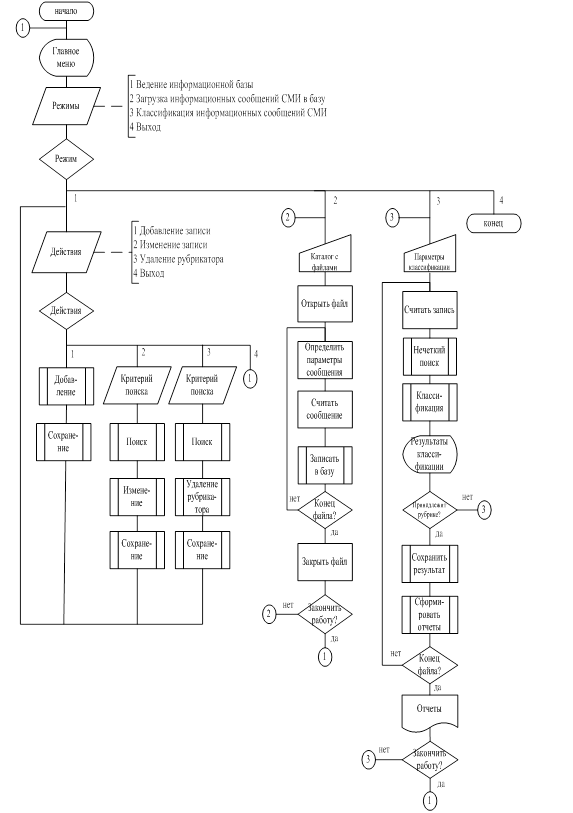
Рисунок 4.4.1 – Схема работы системы
5 ТЕХНИЧЕСКОЕ ОБЕСПЕЧЕНИЕ АИС «КЛАССИФИКАТОР»
5.1 Описание комплекса технических средств
АИС «Классификатор» реализована на базе ПЭВМ. ПЭВМ позволяет существенно повысить эффективность работы пользователя архитектурными и техническими возможностями. Решено использовать базовый комплект ПЭВМ типа IBM PC, технические характеристики которого позволяют решать все поставленные задачи.
При проектировании и функционировании системы используется базовый комплект ПЭВМ IBM PC, включающий следующие устройства:
- процессор Intel Seleron с тактовой частотой 2 ГГц;
- 256 Мбайт оперативной памяти;
- жесткий диск не менее 2 Гбайт;
- операционная система – Windows Me, 2000, XP;
- монитор SVGA;
- клавиатура стандартная русифицированная;
- мышь.
При эксплуатации оборудования пользователи должны руководствоваться следующими документами:
- инструкция по технике безопасности;
- руководство пользователя.
Необходимо соблюдать требования техники безопасности и следующие меры предосторожности:
1) не подключать и не отключать соединители электропитания при поданном напряжении в сеть;
2) не оставлять ЭВМ включенной без наблюдателя;
3) по окончанию работ отключать ПЭВМ от сети.
5.2 Инструкция по эксплуатации комплекса технических средств
Данная инструкция дает пользователю необходимое указание по использованию базового комплекта ПЭВМ IBM PC. К работе с ЭВМ допускаются лица, прошедшие инструктаж по технике безопасности при работе с электроустановками напряжением до 1000 В.
При эксплуатации ПЭВМ запрещается:
1) применять комплектующие изделия, носители данных и материалы, не указанные в эксплуатационной документации;
2) подключать устройства, использование которых не согласовано с изготовителем ПЭВМ;
3) извлекать электронные модули, отсоединять кабель интерфейса при подключенном электропитании любой из составных частей ПЭВМ;
4) снимать кожухи устройства, проводить какие-либо ремонтные работы.
Категорически запрещается работать на ПЭВМ при снятом кожухе любого из устройств. До включения электропитания ПЭВМ необходимо проверить визуально целостность соединительных кабелей.
К эксплуатации оборудования допускаются лица, работающие с АИС «Классификатор», которые могут не являться специалистами в области компьютерных технологий и программирования, а обладают лишь навыками работы с компьютером.
Решение задач осуществляется ПЭВМ под управлением операционной системы (ОС) Windows Me, 2000, XP. Подготовка к работе заключается в начальной загрузке в ОЗУ ПЭВМ ОС Windows. Начальная загрузка OC Windows выполняется автоматически в следующих случаях:
1) при включении электропитания компьютера;
2) при нажатии на клавишу RESET, которая находится на передней панели корпуса ПЭВМ;
3) при перезагрузке компьютера.
Чтобы выполнить загрузку системы, необходимы следующие действия:
1) включить стабилизатор напряжения (если необходимо);
2) включить (если необходимо) принтер;
3) включить монитор компьютера;
4) включить выключатель на корпусе системного блока.
После этого на экране появится сообщение о ходе работы программ проверки и начальной загрузки компьютера. Когда начальная загрузка будет закончена, на экране монитора появится изображение рабочего стола.
После успешного окончания начальной загрузки можно перейти к решению задач пользователя.
При окончании работы программы необходимо:
1) закончить работу программ;
2) выключить принтер, если он включен;
3) выключить монитор компьютера, если необходимо;
4) выключить компьютер;
5) выключить стабилизатор напряжения.
ЗАКЛЮЧЕНИЕ
Во время выполнения дипломной работы был сделан обзор и проведен анализ некоторых существующих разработок в сфере электронного документооборота, направленных на автоматизацию процесса классификации информационных сообщений, указаны их возможности и недостатки. С учетом необходимых требований были определены возможности, которыми должна обладать АИС «Классификатор»:
- создание информационной базы для автоматизированного процесса классификации статей к той или иной категории;
- загрузка информационных сообщений СМИ в базу;
- обработка текстовой и цифровой информации с использованием метода нечеткого поиска;
- классификация информационных сообщений с использованием метода ранжирования;
- открытость структуры рубрикатора и словаря, то есть возможность оперативной их корректировки;
- формирование рекомендаций для принятия решений;
- формирование отчетов.
Были сформулированы назначение и цели системы, поставлены задачи и определены функции.
Была разработана форма и представлено подробное описание структуры входных информационных сообщений СМИ и результатов классификации, используемых и получаемых в результате функционирования АИС «Классификатор». Была разработана структура организации базы для хранения информационных сообщений СМИ.
Была разработана математическая постановка задачи классификации информационных сообщений СМИ, а также описаны метод нечеткого поиска и метод ранжирования, применяемые при реализации требуемых функциональных характеристик АИС «Классификатор», была разработана схема работы системы.
Была рассчитана надежность системы на всех этапах ее развития.
Результатом проделанной работы является программа, выполняющая следующие функции:
- ведение информационной базы: формирование, добавление записи, изменение записи, удаление записи, сохранение записи, согласованное с работой всего объекта автоматизации;
- обработка информационных сообщений СМИ: открытие списка текстовых файлов в каталоге, открытие файла, считывание строки из файла, запись информационных сообщений СМИ в базу, закрытие файла;
- настройка параметров: определение каталога с файлами, задание расширения файлов с исходными данными, настройка расширения файлов, настройка параметров классификации;
- открытость структуры рубрикатора и словаря, то есть возможность оперативной их корректировки;
- классификация информационных сообщений СМИ: поиск записей по различным ключам словаря с помощью метода нечеткого поиска, классификация сообщений по результатам поиска, формирование рекомендаций для принятия решений, формирование отчетов.
При выполнении дипломного проекта особое внимание было уделено информационным характеристикам решаемой задачи, проведен анализ информации, поступающей в систему для обработки, учтены все требования, предъявляемые к решению поставленной задачи. Также был рассчитан экономический эффект от внедрения разработки, рассмотрены вопросы охраны труда.
БИБЛИОГРАФИЧЕСКИЙ СПИСОК
1. ГОСТ 2.105-95. ЕСКД. Общие требования к текстовым документам.
2. ГОСТ Р50.1.028-2001. Методология функционального моделирования.
3. ГОСТ 28195-89. Оценка качества программных средств.
4. ГОСТ 19.102-77.ЕСПД. Стадии разработки.
5. ГОСТ 19.402-78.ЕСПД. Описание программы.
6. ГОСТ 12.1.005-88 Общие санитарно-гигиенические требования к воздуху в рабочей зоне.
7. ГОСТ 19.701-90 Схемы алгоритмов, программ, данных и систем.
8. ГОСТ 34.201-89 Информационная технология. Виды, комплектность и обозначение документов при создании автоматизированных систем.
9. ГОСТ 34.602-89 Информационная технология. Техническое задание на создание автоматизированной системы.
10. СанПиН 2.2.2/2.4.1340-03 Гигиенические требования к персональным электронно-вычислительным машинам и организации работы.
11. Р.2.2.2006-05 Гигиенические критерии оценки условий труда по показателям вредности и опасности окружающей среды, тяжести и напряженности трудового процесса.
12. СанПиН 2.2.548-96 Общие санитарно-гигиенические требования к воздуху в рабочей зоне.
13. Андрейчиков А.В., Андрейчикова О.Н. Интеллектуальные информационные системы: Учебник. – М.: Финансы и статистика, 2004. – 424 с.: ил.
14. Базы данных в Delphi 7. Самоучитель/ В. Понамарев. – СПб.: Питер, 2003. – 224 с.: ил.
15. Башмаков А.И., Башмаков И.А. Интеллектуальные информационные технологии: Учеб. пособие. М.: Изд-во МГТУ им. Н.Э. Баумана, 2005. – 304 с.: ил.
16. Бобровский С.И. Delphi 7. Учебный курс.– СПб.: Питер, 2003. – 736с.
17. Глушаков С.В., Клевцов А.Л. Программирование в среде Delphi 7. – Харьков: Фолио, 2003. – 528с.
18. Гофман В.Э., Хомоненко А.Д. Работа с базами данных в Delphi / В. - 2-е изд. СПб.: БХВ – Петербург, 2002. – 624с.: ил.
19. Девятков В.В. Системы искусственного интеллекта: Учеб. пособие для вузов. – М.: Изд-во МГТУ им. Н.Э. Баумана, 2001. – 352 с.: ил.
20. Диго С.М. Проектирование баз данных: Учебник. – М.: Финансы и статистика, 1988. 216с.
21. Дубнов П.Ю. Access 2000: Программирование баз данных. – М.: ДМК, 2000. – 272с.: ил.
22. Пономарев В. Базы данных в Delphi 7: Самоучитель. – М. и др.: Питер, 2003. 224с.: ил.
23. Средства защиты в машиностроении: Расчет и проектирование: Справочник/С.В. Белов, А.Ф. Козьяков, О.Ф. Партолин и др.; Под ред. С.В. Белова. – М.: Машиностроение, 1989. – 368 с.: ил.
24. Типовые нормы времени на программирование задач для ЭВМ. – М.: Экономика, 1989.
25. http://google.ru/com/str.zip
26. http://google.ru//narod.ru/Hem/infon.zip
Приложение 1. Структура входных и выходных документов
Результаты классификации информационных сообщений СМИ
| Код | Наименование рубрики | Название | Текст | Ключевые слова | Результат |
Отчет по результатам классификации статьи
Дата публикации:_________________
Файл публикации:________________
Название публикации:_____________
Ключевые слова:__________________
Автор публикации: ________________
Текст публикации: _______________
| Код | Наименование | По названию | По тексту | По ключевым словам | Результат |
Отчет по обработанным статьям файла
Дата публикации: ____________________
Название публикации: ________________
Ключевые слова: _____________________
Автор публикации: ___________________
Текст публикации: ___________________
Сопоставленные рубрики: _______________
Приложение 2. Текст программы
unit uMain;
interface
uses
Windows, Messages, SysUtils, Variants, Classes, Graphics, Controls, Forms,
Dialogs, Menus, OleServer, WordXP;
type
TfrmMain = class(TForm)
mnMain: TMainMenu;
N1: TMenuItem;
N2: TMenuItem;
N3: TMenuItem;
N4: TMenuItem;
N5: TMenuItem;
N6: TMenuItem;
N7: TMenuItem;
N8: TMenuItem;
N9: TMenuItem;
N10: TMenuItem;
N11: TMenuItem;
wa: TWordApplication;
wd: TWordDocument;
wf: TWordFont;
N12: TMenuItem;
procedure N2Click(Sender: TObject);
procedure N3Click(Sender: TObject);
procedure N5Click(Sender: TObject);
procedure N7Click(Sender: TObject);
procedure N9Click(Sender: TObject);
procedure N11Click(Sender: TObject);
procedure N12Click(Sender: TObject);
private
{ Private declarations }
public
{ Public declarations }
end;
var
frmMain: TfrmMain;
implementation
uses uInputModule, uClassify, uEditDictModule, uClassifySettings,
uDataModule, uGetFileName, uEditPubl;
{$R *.dfm}
procedure TfrmMain.N2Click(Sender: TObject);
begin
frmInputForm.ShowModal;
end;
procedure TfrmMain.N3Click(Sender: TObject);
begin
frmClassify.ShowModal;
end;
procedure TfrmMain.N5Click(Sender: TObject);
begin
frmEditDict.ShowModal;
end;
procedure TfrmMain.N7Click(Sender: TObject);
begin
frmClassifySettings.ShowModal;
end;
procedure TfrmMain.N9Click(Sender: TObject);
begin
Close;
end;
procedure TfrmMain.N11Click(Sender: TObject);
var tmpl, Template, NewTemplate, ItemIndex: olevariant;
ARange: Range;
pars: Paragraphs;
par: Paragraph;
st: string;
vcol: OleVariant;
iStat: integer;
begin
dmIAS.aqFiles.Close;
dmIAS.aqFiles.Open;
frmGetFileName.cbFiles.Items.Clear;
frmGetFileName.cbFiles.Text:= dmIAS.aqFiles.FieldByName('file').AsString;
while not dmIAS.aqFiles.Eof do
begin
frmGetFileName.cbFiles.Items.Add(dmIAS.aqFiles.FieldByName('file').AsString);
dmIAS.aqFiles.Next;
end;
frmGetFileName.iMD:= 0;
frmGetFileName.ShowModal;
if (frmGetFileName.iMD = 0) or (frmGetFileName.cbFiles.Text = '')
then exit;
dmIAS.aqExe.Close;
dmIAS.aqExe.SQL.Text:= 'Select * from qObrPubl where file = :file';
dmIAS.aqExe.Parameters.ParamByName('file').Value:= frmGetFileName.cbFiles.Text;
dmIAS.aqExe.Open;
try
wa.Connect;
wa.Visible := True;
except
MessageDlg('А у Вас Word не установлен :(', mtError, [mbOk], 0);
Abort;
end;
ItemIndex:= 1;
Template:= EmptyParam;
NewTemplate := False;
// Создание документа
wa.Documents.Add(Template, NewTemplate, EmptyParam, EmptyParam) ;
wd.ConnectTo(wa.Documents.Item(ItemIndex));
wd.PageSetup.Set_Orientation(wdOrientLandscape);
wa.Options.CheckSpellingAsYouType := False;
wa.Options.CheckGrammarAsYouType := False;
ARange:= wd.Range(EmptyParam, EmptyParam);
pars:= wd.Paragraphs;
tmpl:= ARange;
par:= pars.Add(tmpl);
wf.ConnectTo(wd.Sentences.Get_Last.Font);
wd.Range.Paragraphs.Set_Alignment(wdAlignParagraphLeft);
wa.Selection.Font.Bold:= 1;
wa.Selection.Font.Size:= 16;
st:= 'Отчет по обработанным статьям файла ' + frmGetFileName.cbFiles.Text;
wa.Selection.InsertAfter(st+#13);
wa.Selection.InsertAfter(' '+#13);
vcol := wdCollapseEnd;
wa.Selection.Collapse(vcol);
iStat:= -1;
while not dmIAS.aqExe.Eof do
begin
if iStat <> dmIAS.aqExe.FieldByName('id_publ').AsInteger
then
begin
vcol := wdCollapseEnd;
wa.Selection.Collapse(vcol);
wa.Selection.Font.Bold:= 0;
wa.Selection.Font.Size:= 14;
wa.Selection.InsertAfter(' '+#13);
wa.Selection.InsertAfter(' '+#13);
st:= 'Дата публикации: ';
wa.Selection.InsertAfter(st);
vcol := wdCollapseEnd;
wa.Selection.Collapse(vcol);
if (dmIAS.aqExe.FieldByName('data').AsString = '30.12.1899')
then st:= ' '
else st:= dmIAS.aqExe.FieldByName('data').AsString;
wa.Selection.InsertAfter(st+#13);
vcol := wdCollapseEnd;
wa.Selection.Collapse(vcol);
st:= 'Название публикации: ';
wa.Selection.InsertAfter(st);
vcol := wdCollapseEnd;
wa.Selection.Collapse(vcol);
st:= dmIAS.aqExe.FieldByName('name_publ').AsString;
wa.Selection.InsertAfter(st+#13);
vcol := wdCollapseEnd;
wa.Selection.Collapse(vcol);
st:= 'Ключевые слова: ';
wa.Selection.InsertAfter(st);
vcol := wdCollapseEnd;
wa.Selection.Collapse(vcol);
st:= dmIAS.aqExe.FieldByName('keywords').AsString;
wa.Selection.InsertAfter(st+#13);
vcol := wdCollapseEnd;
wa.Selection.Collapse(vcol);
st:= 'Автор публикации: ';
wa.Selection.InsertAfter(st);
vcol := wdCollapseEnd;
wa.Selection.Collapse(vcol);
st:= dmIAS.aqExe.FieldByName('author').AsString;
wa.Selection.InsertAfter(st+#13);
vcol := wdCollapseEnd;
wa.Selection.Collapse(vcol);
st:= 'Текст публикации: ';
wa.Selection.InsertAfter(st);
vcol := wdCollapseEnd;
wa.Selection.Collapse(vcol);
st:= dmIAS.aqExe.FieldByName('text_publ').AsString;
wa.Selection.InsertAfter(st+#13);
vcol := wdCollapseEnd;
wa.Selection.Collapse(vcol);
st:= 'Сопоставленные рубрики:';
wa.Selection.InsertAfter(st+#13);
vcol := wdCollapseEnd;
wa.Selection.Collapse(vcol);
st:= dmIAS.aqExe.FieldByName('indx').AsString
+ ' '
+ dmIAS.aqExe.FieldByName('name_r').AsString;
wa.Selection.InsertAfter(st);
vcol := wdCollapseEnd;
wa.Selection.Collapse(vcol);
iStat:= dmIAS.aqExe.FieldByName('id_publ').AsInteger;
end
else
begin
wa.Selection.InsertAfter(' '+#13);
st:= dmIAS.aqExe.FieldByName('indx').AsString
+ ' '
+ dmIAS.aqExe.FieldByName('name_r').AsString;
wa.Selection.InsertAfter(st);
vcol := wdCollapseEnd;
wa.Selection.Collapse(vcol);
end;
dmIAS.aqExe.Next;
end;
wa.Disconnect;
end;
procedure TfrmMain.N12Click(Sender: TObject);
begin
frmEditPubl.ShowModal;
end;
end.
unit uFuzzySearch;
interface
function IndistinctMatching(MaxMatching:Integer; strInputMatching:WideString; strInputStandart:WideString):Integer;
implementation
uses SysUtils;
type
TRetCount = packed record
lngSubRows : Word;
lngCountLike : Word;
end;
function Matching(StrInputA:WideString; StrInputB:WideString; lngLen:Integer):TRetCount;
Var
TempRet : TRetCount;
PosStrB : Integer;
PosStrA : Integer;
StrA : WideString;
StrB : WideString;
StrTempA : WideString;
StrTempB : WideString;
begin
StrA := String(StrInputA);
StrB := String(StrInputB);
For PosStrA:= 1 To Length(strA) - lngLen + 1 do
begin
StrTempA:= System.Copy(strA, PosStrA, lngLen);
For PosStrB:= 1 To Length(strB) - lngLen + 1 do
begin
StrTempB:= System.Copy(strB, PosStrB, lngLen);
If SysUtils.AnsiCompareText(StrTempA,StrTempB) = 0 Then
begin
Inc(TempRet.lngCountLike);
break;
end;
end;
Inc(TempRet.lngSubRows);
end; // PosStrA
Matching.lngCountLike:= TempRet.lngCountLike;
Matching.lngSubRows := TempRet.lngSubRows;
end; { function }
//------------------------------------------------------------------------------
function IndistinctMatching(MaxMatching:Integer; strInputMatching:WideString; strInputStandart:WideString):Integer;
Var
gret : TRetCount;
tret : TRetCount;
lngCurLen: Integer ; //текущая длина подстроки
begin
//если не передан какой-либо параметр, то выход
If (MaxMatching = 0) Or (Length(strInputMatching) = 0) Or
(Length(strInputStandart) = 0) Then
begin
IndistinctMatching:= 0;
exit;
end;
gret.lngCountLike:= 0;
gret.lngSubRows := 0;
// Цикл прохода по длине сравниваемой фразы
For lngCurLen:= 1 To MaxMatching do
begin
//Сравниваем строку A со строкой B
tret:= Matching(strInputMatching, strInputStandart, lngCurLen);
gret.lngCountLike := gret.lngCountLike + tret.lngCountLike;
gret.lngSubRows := gret.lngSubRows + tret.lngSubRows;
//Сравниваем строку B со строкой A
//tret:= Matching(strInputStandart, strInputMatching, lngCurLen);
//gret.lngCountLike := gret.lngCountLike + tret.lngCountLike;
//gret.lngSubRows := gret.lngSubRows + tret.lngSubRows;
end;
If gret.lngSubRows = 0 Then
begin
IndistinctMatching:= 0;
exit;
end;
IndistinctMatching:= Trunc((gret.lngCountLike / gret.lngSubRows) * 100);
end;
end.
unit uClassify;
interface
uses
Windows, Messages, SysUtils, Variants, Classes, Graphics, Controls, Forms,
Dialogs, StdCtrls, ExtCtrls, Mask, DBCtrls, Grids, DBGridEh, ComCtrls,
WordXP, OleServer;
type
TfrmClassify = class(TForm)
Panel1: TPanel;
Panel2: TPanel;
Label1: TLabel;
DBNavigator1: TDBNavigator;
dbmText: TDBMemo;
Panel3: TPanel;
Label7: TLabel;
Button2: TButton;
Panel4: TPanel;
Label6: TLabel;
Label3: TLabel;
dbAuthor: TDBEdit;
Label2: TLabel;
dbDate: TDBEdit;
Label4: TLabel;
dbName: TDBEdit;
Label5: TLabel;
dbKeywords: TDBEdit;
pbClassify: TProgressBar;
dbgClassify: TDBGridEh;
Button1: TButton;
Label8: TLabel;
dbFile: TDBEdit;
lblCountArticles: TLabel;
Button3: TButton;
wd: TWordDocument;
wa: TWordApplication;
wf: TWordFont;
procedure SetDBElemColor(flColor: boolean);
procedure Button1Click(Sender: TObject);
procedure Button2Click(Sender: TObject);
procedure FormCreate(Sender: TObject);
procedure FormShow(Sender: TObject);
procedure Button3Click(Sender: TObject);
private
{ Private declarations }
public
{ Public declarations }
end;
var
frmClassify: TfrmClassify;
implementation
uses uDataModule, uFuzzySearch, uClassifySettings, uStructs;
{$R *.dfm}
procedure TfrmClassify.SetDBElemColor(flColor: boolean);
begin
if frmClassify = nil
then exit;
if flColor
then
begin
dbName.Color:= clMoneyGreen;
dbKeywords.Color:= clMoneyGreen;
dbmText.Color:= clMoneyGreen;
end
else
begin
dbName.Color:= clWindow;
dbKeywords.Color:= clWindow;
dbmText.Color:= clWindow;
end;
end;
procedure TfrmClassify.Button1Click(Sender: TObject);
var id_publ, id_rubr, level,
Name_cnt, Text_cnt, Key_cnt, im,
iNamePorog12, iTextPorog12, iKeyPorog12,
iNamePorog23, iTextPorog23, iKeyPorog23,
iFuzzyPorog: integer;
stWord, res: string;
function GetRes(NameCnt, TextCnt, KeyCnt: integer): String;
begin
if (NameCnt < iNamePorog12)
and (TextCnt < iTextPorog12)
and (KeyCnt < iKeyPorog12)
then result:= '-'
else
if (NameCnt >= iNamePorog23)
or (TextCnt >= iTextPorog23)
or (KeyCnt >= iKeyPorog23)
then result:= '+'
else result:= '?';
end;
begin
// Устанавливаем пороги срабатывания
iNamePorog12:= frmClassifySettings.GetNamePorog(12);
iTextPorog12:= frmClassifySettings.GetTextPorog(12);
iKeyPorog12:= frmClassifySettings.GetKeyPorog(12);
iNamePorog23:= frmClassifySettings.GetNamePorog(23);
iTextPorog23:= frmClassifySettings.GetTextPorog(23);
iKeyPorog23:= frmClassifySettings.GetKeyPorog(23);
iFuzzyPorog:= frmClassifySettings.GetFuzzyPorog;
// Начинаем классификацию
dmIAS.aqDict.Close;
dmIAS.aqDict.Open;
dmIAS.TruncClassify;
pbClassify.Position:= 0;
pbClassify.Max:= dmIAS.atPublikatsii.RecordCount * (dmIAS.aqDict.RecordCount+1);
with dmIAS.atPublikatsii do
begin
First;
while not Eof do
begin
id_publ:= FieldByName('id_publ').AsInteger;
Name_cnt:= 0;
Text_cnt:= 0;
Key_cnt:= 0;
dmIAS.aqDict.First;
id_rubr:= dmIAS.aqDict.FieldByName('id').AsInteger;
level:= dmIAS.aqDict.FieldByName('level').AsInteger;
while not dmIAS.aqDict.Eof do
begin
// Классифицируем по словарю для каждой рубрики
if id_rubr <> dmIAS.aqDict.FieldByName('id').AsInteger
then
begin
res:= GetRes(Name_cnt, Text_cnt, Key_cnt);
dmIAS.InsertClassify(id_publ, id_rubr, level, Name_cnt,
Text_cnt, Key_cnt, res);
id_rubr:= dmIAS.aqDict.FieldByName('id').AsInteger;
level:= dmIAS.aqDict.FieldByName('level').AsInteger;
Name_cnt:= 0;
Text_cnt:= 0;
Key_cnt:= 0;
end;
stWord:= AnsiUpperCase(dmIAS.aqDict.FieldByName('Word').AsString);
// Классификация по наименованию
im:= IndistinctMatching(length(stWord),
stWord,
AnsiUpperCase(FieldByName('name_publ').AsString));
if im > iFuzzyPorog
then Inc(Name_cnt);
// Классификация по тексту
im:= IndistinctMatching(length(stWord),
stWord,
AnsiUpperCase(FieldByName('text_publ').AsString));
if im > iFuzzyPorog
then Inc(Text_cnt);
// Классификация по ключевым словам
im:= IndistinctMatching(length(stWord),
stWord,
AnsiUpperCase(FieldByName('keywords').AsString));
if im > iFuzzyPorog
then Inc(Key_cnt);
dmIAS.aqDict.Next;
pbClassify.StepIt;
Application.ProcessMessages;
end;
res:= GetRes(Name_cnt, Text_cnt, Key_cnt);
dmIAS.InsertClassify(id_publ, id_rubr, level, Name_cnt,
Text_cnt, Key_cnt, res);
Next;
pbClassify.StepIt;
Application.ProcessMessages;
end;
end;
dmIAS.aqClassify.Close;
dmIAS.atPublikatsii.First;
dmIAS.aqClassify.Open;
Application.ProcessMessages;
ShowMessage('Классификация успешно завершена.');
end;
procedure TfrmClassify.Button2Click(Sender: TObject);
var i, i_rubr, level: integer;
begin
if dbgClassify.SelectedRows.Count = 0
then
begin
ShowMessage('Не выбрано ни одной записи!');
exit;
end;
// Удалить все записи из Publ_Rubr для данной статьи
dmIAS.DeleteFromPublRubr(dmIAS.atPublikatsii.FieldByName('id_publ').AsInteger);
// Записать в Publ_Rubr все выбранные рубрики для данной статьи
for i:= 0 to dbgClassify.SelectedRows.Count-1 do
begin
dbgClassify.DataSource.DataSet.GotoBookmark(Pointer(dbgClassify.SelectedRows.Items[i]));
i_rubr:= dbgClassify.DataSource.DataSet.FieldByName('id').AsInteger;
level:= dbgClassify.DataSource.DataSet.FieldByName('level_r').AsInteger;
dmIAS.InsertIntoPublRubr(dmIAS.atPublikatsii.FieldByName('id_publ').AsInteger,
i_rubr,
level);
end;
dbgClassify.DataSource.DataSet.GotoBookmark(Pointer(dbgClassify.SelectedRows.Items[0]));
ShowMessage('Соответствующие статье рубрики сохранены.');
dmIAS.atObrPublikatsii.Close;
dmIAS.atObrPublikatsii.Open;
dmIAS.atCountObrPublikatsii.Close;
dmIAS.atCountObrPublikatsii.Open;
lblCountArticles.Caption:= 'Всего в базе: '
+ IntToStr(dmIAS.atPublikatsii.RecordCount)
+ ' статей. '
+ ' Классифицировано '
+ IntToStr(dmIAS.atCountObrPublikatsii.RecordCount)
+ ' статей.';
end;
procedure TfrmClassify.FormCreate(Sender: TObject);
begin
frmClassifySettings.SetNamePorog(2, 12);
frmClassifySettings.SetTextPorog(3, 12);
frmClassifySettings.SetKeyPorog(2, 12);
frmClassifySettings.SetNamePorog(4, 23);
frmClassifySettings.SetTextPorog(6, 23);
frmClassifySettings.SetKeyPorog(4, 23);
frmClassifySettings.SetFuzzyPorog(50);
frmClassifySettings.SetflShowAll(true);
end;
procedure TfrmClassify.FormShow(Sender: TObject);
begin
{ if frmClassifySettings.GetflShowAll
then // Показывать все статьи
with dmIAS.atPublikatsii do
begin
Close;
SQL.Text:= stSelectAllPubl;
Open;
end
else // Показывать необработанные статьи
with dmIAS.atPublikatsii do
begin
Close;
SQL.Text:= stSelectNeobrPubl;
Open;
end;}
lblCountArticles.Caption:= 'Всего в базе: '
+ IntToStr(dmIAS.atPublikatsii.RecordCount)
+ ' статей. '
+ ' Классифицировано '
+ IntToStr(dmIAS.atCountObrPublikatsii.RecordCount)
+ ' статей.';
end;
procedure TfrmClassify.Button3Click(Sender: TObject);
var tmpl, Template, NewTemplate, ItemIndex: olevariant;
ARange: Range;
pars: Paragraphs;
par: Paragraph;
tbls: Tables;
tbl1: Table;
st: string;
vcol: OleVariant;
i: integer;
begin
try
wa.Connect;
wa.Visible := True;
except
MessageDlg('А у Вас Word не установлен :(', mtError, [mbOk], 0);
Abort;
end;
ItemIndex:= 1;
Template:= EmptyParam;
NewTemplate := False;
// Создание документа
wa.Documents.Add(Template, NewTemplate, EmptyParam, EmptyParam) ;
wd.ConnectTo(wa.Documents.Item(ItemIndex));
wd.PageSetup.Set_Orientation(wdOrientLandscape);
wa.Options.CheckSpellingAsYouType := False;
wa.Options.CheckGrammarAsYouType := False;
ARange:= wd.Range(EmptyParam, EmptyParam);
pars:= wd.Paragraphs;
tmpl:= ARange;
par:= pars.Add(tmpl);
wf.ConnectTo(wd.Sentences.Get_Last.Font);
wd.Range.Paragraphs.Set_Alignment(wdAlignParagraphLeft);
wa.Selection.Font.Bold:= 1;
wa.Selection.Font.Size:= 16;
st:= 'Отчет по результатам классификации статьи ';
wa.Selection.InsertAfter(st+#13);
wa.Selection.InsertAfter(' '+#13);
vcol := wdCollapseEnd;
wa.Selection.Collapse(vcol);
wa.Selection.Font.Bold:= 0;
wa.Selection.Font.Size:= 14;
st:= 'Дата публикации: ';
wa.Selection.InsertAfter(st);
vcol := wdCollapseEnd;
wa.Selection.Collapse(vcol);
if (dmIAS.atPublikatsii.FieldByName('data').AsString = '30.12.1899')
then st:= ' '
else st:= dmIAS.atPublikatsii.FieldByName('data').AsString;
wa.Selection.InsertAfter(st+#13);
vcol := wdCollapseEnd;
wa.Selection.Collapse(vcol);
st:= 'Файл публикации: ';
wa.Selection.InsertAfter(st);
vcol := wdCollapseEnd;
wa.Selection.Collapse(vcol);
st:= dmIAS.atPublikatsii.FieldByName('file').AsString;
wa.Selection.InsertAfter(st+#13);
vcol := wdCollapseEnd;
wa.Selection.Collapse(vcol);
st:= 'Название публикации: ';
wa.Selection.InsertAfter(st);
vcol := wdCollapseEnd;
wa.Selection.Collapse(vcol);
st:= dmIAS.atPublikatsii.FieldByName('name_publ').AsString;
wa.Selection.InsertAfter(st+#13);
vcol := wdCollapseEnd;
wa.Selection.Collapse(vcol);
st:= 'Ключевые слова: ';
wa.Selection.InsertAfter(st);
vcol := wdCollapseEnd;
wa.Selection.Collapse(vcol);
st:= dmIAS.atPublikatsii.FieldByName('keywords').AsString;
wa.Selection.InsertAfter(st+#13);
vcol := wdCollapseEnd;
wa.Selection.Collapse(vcol);
st:= 'Автор публикации: ';
wa.Selection.InsertAfter(st);
vcol := wdCollapseEnd;
wa.Selection.Collapse(vcol);
st:= dmIAS.atPublikatsii.FieldByName('author').AsString;
wa.Selection.InsertAfter(st+#13);
vcol := wdCollapseEnd;
wa.Selection.Collapse(vcol);
st:= 'Текст публикации: ';
wa.Selection.InsertAfter(st);
vcol := wdCollapseEnd;
wa.Selection.Collapse(vcol);
st:= dmIAS.atPublikatsii.FieldByName('text_publ').AsString;
wa.Selection.InsertAfter(st+#13);
vcol := wdCollapseEnd;
wa.Selection.Collapse(vcol);
wa.Selection.InsertAfter(' '+#13);
st:= 'Результаты классификации:';
wa.Selection.InsertAfter(st);
vcol := wdCollapseEnd;
wa.Selection.Collapse(vcol);
ARange:= wd.Sentences.Last;
tbls:= ARange.Tables;
tbl1:= tbls.Add(ARange,
dmIAS.aqClassify.RecordCount+1, // число строк
6, // число столбцов
EmptyParam,
EmptyParam);
tbl1.Cell(1, 1).Range.Text:= 'Код';
tbl1.Cell(1, 2).Range.Text:= 'Наименование';
tbl1.Cell(1, 3).Range.Text:= 'По назв.';
tbl1.Cell(1, 4).Range.Text:= 'По тексту';
tbl1.Cell(1, 5).Range.Text:= 'По кл.сл.';
tbl1.Cell(1, 6).Range.Text:= 'Результат';
i:= 2;
dmIAS.aqClassify.First;
while not dmIAS.aqClassify.Eof do
begin
tbl1.Cell(i, 1).Range.Text:= dmIAS.aqClassify.FieldByName('indx').AsString;
tbl1.Cell(i, 2).Range.Text:= dmIAS.aqClassify.FieldByName('name_r').AsString;
tbl1.Cell(i, 3).Range.Text:= dmIAS.aqClassify.FieldByName('name_cnt').AsString;
tbl1.Cell(i, 4).Range.Text:= dmIAS.aqClassify.FieldByName('text_cnt').AsString;
tbl1.Cell(i, 5).Range.Text:= dmIAS.aqClassify.FieldByName('key_cnt').AsString;
tbl1.Cell(i, 6).Range.Text:= dmIAS.aqClassify.FieldByName('res').AsString;
dmIAS.aqClassify.Next;
Inc(i);
end;
vcol := wdCollapseEnd;
wa.Selection.Collapse(vcol);
wa.Disconnect;
dmIAS.aqClassify.First;
end;
end.
© 2010 Интернет База Рефератов