
Рефераты по сексологии
Рефераты по информатике программированию
Рефераты по биологии
Рефераты по экономике
Рефераты по москвоведению
Рефераты по экологии
Краткое содержание произведений
Рефераты по физкультуре и спорту
Топики по английскому языку
Рефераты по математике
Рефераты по музыке
Остальные рефераты
Рефераты по авиации и космонавтике
Рефераты по административному праву
Рефераты по безопасности жизнедеятельности
Рефераты по арбитражному процессу
Рефераты по архитектуре
Рефераты по астрономии
Рефераты по банковскому делу
Рефераты по биржевому делу
Рефераты по ботанике и сельскому хозяйству
Рефераты по бухгалтерскому учету и аудиту
Рефераты по валютным отношениям
Рефераты по ветеринарии
Рефераты для военной кафедры
Рефераты по географии
Рефераты по геодезии
Рефераты по геологии
Рефераты по геополитике
Рефераты по государству и праву
Рефераты по гражданскому праву и процессу
Рефераты по делопроизводству
Рефераты по кредитованию
Рефераты по естествознанию
Рефераты по истории техники
Рефераты по журналистике
Рефераты по зоологии
Рефераты по инвестициям
Рефераты по информатике
Исторические личности
Рефераты по кибернетике
Рефераты по коммуникации и связи
Дипломная работа: Корректирующие коды
Дипломная работа: Корректирующие коды
Курс: Теория информации и кодирования
Тема: КОРРЕКТИРУЮЩИЕ КОДЫ
Содержание
1. КОРРЕКТИРУЮЩИЕ КОДЫ. ОСНОВНЫЕ ПОНЯТИЯ
2. ЛИНЕЙНЫЕ ГРУППОВЫЕ КОДЫ
3. КОД ХЭММИНГА
Список Литературы
1. КОРРЕКТИРУЮЩИЕ КОДЫ. ОСНОВНЫЕ ПОНЯТИЯ
В соответствии с теоремой Шеннона для дискретного канала с помехами, вероятность ошибки при передаче данных по каналу связи может быть сколь угодно малой при выборе соответствующего метода кодирования сигнала, т. е. помеха не накладывает существенных ограничений на точность передачи информации (данных). Достоверность передаваемой информации может быть обеспечена применением корректирующих кодов.
Помехоустойчивыми или корректирующими кодами называются коды, позволяющие обнаружить и устранить ошибки при передаче информации из-за воздействия помех.
Наиболее распространенным является класс кодов с коррекцией одиночных и обнаружением двойных ошибок (КО-ОД). Самым известных среди этих кодов является код Хэмминга, имеющий простой и удобный для технической реализации алгоритм обнаружения и исправления одиночной ошибки.
В ЭВМ эти коды используются для повышения надежности оперативной памяти (ОП) и магнитных дисков. Число ошибок в ЭВМ зависит от типа неисправностей элементов схем (например, неисправность одного элемента интегральной схемы (ИС) вызывает одиночную ошибку, а всей ИС ОП - кратную). Для обнаружения кратных ошибок используется код КО-ОД-ООГ (коррекция одиночной, обнаружение двойной и обнаружение кратной ошибки в одноименной группе битов).
Среди корректирующих кодов широко используются циклические коды, в ЭВМ эти коды применяются при последовательной передаче данных между ЭВМ и внешними устройствами, а также при передаче данных по каналам связи. Для исправления двух и более ошибок (d0 ³ 5) используются циклические коды БЧХ (Боуза - Чоудхури - Хоквингема), а также Рида-Соломона, которые широко используются в устройствах цифровой записи звука на магнитную ленту или оптические компакт-диски и позволяющие осуществлять коррекцию групповых ошибок. Способность кода обнаруживать и исправлять ошибки достигается за счет введений избыточности в кодовые комбинации, т. е. кодовым комбинациям из к двоичных информационных символов, поступающих на вход кодирующего устройства, соответствует на выходе последовательность из n двоичных символов (такой код называется (n, k) - кодом).
Если N0 = 2n - общее число кодовых комбинаций, а N = 2k - число разрешенных, то число запрещенных кодовых комбинаций равно
N0-N = 2n -2k.
При этом число ошибок, которое приводит к запрещенной кодовой комбинации равно:
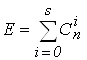 , (1)
, (1)
где S - кратность ошибки, т. е. количество искаженных символов в кодовой комбинации S = 0, 1, 2, ...
Cni - сочетания из n элементов по i, вычисляемое по формуле:
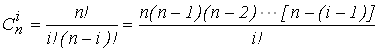 , (2)
, (2)
для S = 0 ; ![]()
S = 1 ; ![]()
S = 2 ; ![]()
S = 3 ; ![]() и т. д.
и т. д.
Для исправления S ошибок количество комбинаций кодового слова, составленного из m проверочных разрядов N = 2m, должно быть больше возможного числа ошибок (2), при этом количество обнаруживаемых ошибок в два раза больше, чем исправляемых
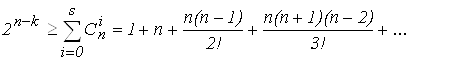 (3)
(3)
2m ³ 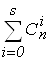 откуда
откуда 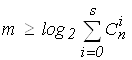 .
.
Для одиночной ошибки, как наиболее
вероятной ![]() .
.
В зависимости от исходных данных кода (n или k) можно использовать
формулы
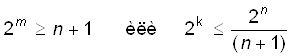 . (4)
. (4)
При этом, m = [log2(1+n)] или m = [log2 {(k+1)+ [log2(k+1)]}], где ква-дратные скобки обозначают округление до большего целого.
В таблице 1 приведены соотношения между длиной кодовой комбинации и количеством информационных и контрольных разрядов для кода исправляющего одиночную ошибку, а также эффективность использования канала связи.
Для исправления двукратной ошибки
![]() или
или ![]() . (5)
. (5)
Введение избыточности в кодовые комбинации при использовании корректирующих кодов существенно снижает скорость передачи информации и эффективность использования канала связи.
Например, для кода (31, 26) скорость передачи информации равна
![]() ,
,
т. е. скорость передачи уменьшается на 16%.
Таблица 1
n |
7 | 10 | 15 | 31 | 63 | 127 | 255 |
|
k |
4 | 6 | 11 | 26 | 57 | 120 | 247 |
|
m |
3 | 4 | 4 | 5 | 6 | 7 | 8 |
|
|
0,57 | 0,6 | 0,75 | 0,84 | 0,9 | 0,95 | 0,97 |
Как видно из таблицы 1, чем больше n, тем эффективнее используется канал.
Пример 1. Определить количество проверочных разрядов для систематического кода исправляющего одиночную ошибку и состоящего из 20 информационных разрядов.
Решение: Общая длина кодовой комбинации равна n = k+m, где k- количество информационных разрядов, а m- проверочных разрядов.
Для обнаружения двойной и исправления
одиночной ошибки зависимости для разрядов имеют вид 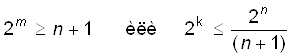 , при этом
, при этом
m = [log2 {(k+1)+ [log2(k+1)]}]=[log2 {(20+1)+ [log2(20+1)]}]=5,
т. е. получим (25, 20)-код.
2. ЛИНЕЙНЫЕ ГРУППОВЫЕ КОДЫ
Линейным называется код, в котором проверочные символы представляют собой линейные комбинации информационных. Групповым называется код, который образует алгебраическую группу по отношению операции сложения по модулю два.
Свойство линейного кода: сумма (разность) кодовых векторов линей-ного кода дает вектор, принадлежащий этому коду. Свойство группового кода: минимальное кодовое расстояние между кодовыми векторами равно минимальному весу ненулевых векторов. Вес кодового вектора равен числу единиц в кодовой комбинации.
Групповые коды удобно задавать при помощи матриц, размерность которых определяется параметрами k и n. Число строк равно k, а число столбцов равно n = k+m.
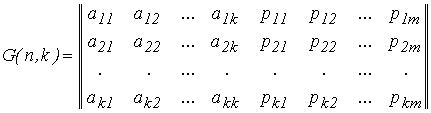 . (6)
. (6)
Коды, порождаемые этими матрицами, называются (n, k)-кодами, а соответствующие им матрицы порождающими (образующими, производящими). Порождающая матрица G состоит из информационной Ikk и проверочной Rkm матриц. Она является сжатым описанием линейного кода и может быть представлена в канонической (типовой) форме
![]() . (7)
. (7)
В качестве информационной матрицы удобно использовать единичную матрицу, ранг которой определяется количеством информационных разрядов
 . (8)
. (8)
Строки единичной матрицы представляют собой линейно-незави-симые комбинации (базисные вектора), т. е. их по парное суммирование по модулю два не приводит к нулевой строке.
Строки порождающей матрицы представляют собой первые k комбинаций корректирующего кода, а остальные кодовые комбинации могут быть получены в результате суммирования по модулю два всевозможных сочетаний этих строк.
Столбцы добавочной матрицы Rkm определяют правила формирования проверок. Число единиц в каждой строке добавочной матрицы должно удовлетворять условию r1 ³ d0-1, но число единиц определяет число сумматоров по модулю 2 в шифраторе и дешифраторе, и чем их больше, тем сложнее аппаратура.
Производящая матрица кода G(7,4) может иметь вид
 и т.д.
и т.д.
Процесс кодирования состоит во взаимно - однозначном соответствии k-разрядных информационных слов - I и n-разрядных кодовых слов - с
c=IG. (9)
Например: информационному слову I =[1 0 1 0] соответствует следующее кодовое слово
 . (10)
. (10)
При этом, информационная часть остается без изменений, а корректирующие разряды определяются путем суммирования по модулю два тех строк проверочной матрицы, номера которых совпадают с номерами разрядов, содержащих единицу в информационной части кода.
Процесс декодирования состоит в определении соответствия принятого кодового слова, переданному информационному. Это осуществляется с помощью проверочной матрицы H(n, k).
![]() , (11)
, (11)
где RmkT -транспонированная проверочная матрица (поменять строки на столбцы); Imm - единичная матрица.
Для (7, 4)- кода проверочная матрица имеет вид
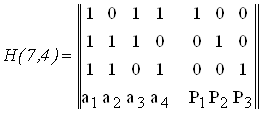 . (12)
. (12)
Между G(n ,k) и H(n, k) существует однозначная связь, т. к. они определяются в соответствии с правилами проверки, при этом для любого кодового слова должно выполняться равенство cHT = 0.
Строки проверочной матрицы определяют правила формирования проверок. Для (7, 4)-кода
p1Å+a1Å+a2Åa4 = S1 ;
p2Å+a1Å+a2Åa3 = S2 ; (13)
p3Å+a1Å+a3Åa4 = S3 .
Полученный синдром сравниваем со столбцами матрицы и определяем разряд, в котором произошла ошибка, номер столбца равен номеру ошибочного разряда. Для исправления ошибки ошибочный бит необходимо проинвертировать.
Пример 1. Построить групповой код способный передавать 16 символов первичного алфавита с исправлением одиночной ошибки. Показать процесс кодирования, декодирования и исправления ошибки для передаваемого информационного слова 1001.
Решение:
1. Построим производящую матрицу G(n, k).
Если объем кода N = 2k = 16, то количество информационных разрядов к = 4. Минимальное кодовое расстояние для исправления одиночной ошибки d0=2s+1=3. По заданной длине информационного слова, используя соотношения:
n = k+m, 2n ³ (n+1)2k и 2m ³ n+1
вычислим основные параметры кода n и m.
m=[log2 {(k+1)+ [log2(k+1)]}]=[log2 {(4+1)+ [log2(4+1)]}]=3.
Откуда n = 7, т. е. необходимо построить (7, 4)-код.
В качестве информационной матрицы Ik(7, 4) - выбираем единичную матрицу (4´4), а в качестве проверочной матрицы Rkm(7 ,4) - выбираем матрицу (4´3), каждая строка которой содержит число единиц больше или равно двум (r1 £ d0-1).
Таким образом, в качестве производящей можно принять матрицу
 .
.
2. Определим комбинации корректирующего кода.
Для заданного числа информационных разрядов k = 4,число кодовых комбинаций равно N = 2k = 24 = 16.
1) 0000 5) 0010 9) 0001 13) 0011
2) 1000 6) 1010 10) 1001 14) 1011
3) 0100 7) 0110 11) 0101 15) 0111
4) 1100 8) 1110 12) 1101 16) 1111
Старшинство разрядов принимаем слева на право, в соответствии с их поступлением на вход декодера.
Находим корректирующие разряды для каждого информационного слова, как результат суммирования по модулю два строк проверочной матрицы номера, которых совпадают с номерами единиц в информационных разрядах кода.
Например, для информационного слова I= [1001] кодовое слово имеет вид
 .
.
Передаваемые в канал кодовые комбинации имеют вид:
1) 0000 000 5) 0010 110 9) 0001 101 13) 0011 011
2) 1000 111 6) 1010 001 10) 1001 010 14) 1011 100
3) 0100 011 7) 0110 101 11) 0101 110 15) 0111 000
4) 1100 100 8) 1110 010 12) 1101 101 16) 1111 111
Процесс декодирования состоит в определении соответствия принятого кодового слова, переданному информационному и осуществляется с помощью проверочной матрицы H(7, 4).
Для построенного (7, 4)-кода проверочная матрица имеет вид
 .
.
Строки проверочной матрицы определяют правила формирования проверок, позволяющие определить синдром ошибки.
Пусть в процессе передачи произошла ошибка во 2-м информационном разряде 1 1 0 1 1 0 0 1
В соответствии с проверочной матрицей составляем проверочные векторы
p1Åa1Åa2Åa4 =S1 = 0Å1Å1Å0 = 0;
p2Åa1Åa2Åa3 =S2 = 0Å1Å1Å1 = 1 ;
p3Åa1Åa3Åa4 =S3 = 1Å1Å0Å1 = 1.
Синдром 011 показывает, что ошибка произошла во 2-м информационном разряде, который необходимо проинвертировать.
Пример 2. Построить образующую матрицу группового кода, для передачи 100 различных сообщений и способную исправлять возмож-но большее число ошибок.
Решение: Объем кода равен N = 2k. При 100 сообщениях: 100 £ N £ 2k , откуда k = 7. По заданной длине информационного слова, используя соотношения:
n = k+m, 2n ³ (n+1)2k и 2m ³ n+1
вычислим основные параметры кода n и m.
m=[log2 {(k+1)+ [log2(k+1)]}]=[log2 {(7+1)+ [log2(7+1)]}]=4.
Откуда n = 11, т. е. получили (11, 7)-код.
В качестве информационной матрицы выбираем единичную матрицу I(7x7).Проверочная матрица содержит 4 столбца и 7 строк, которые содержат r1 £ d0-1 единиц в четырехразрядном коде (2, 3, 4-единицы).
 .
.
3. КОД ХЭММИНГА
Код Хэмминга относится к классу линейных кодов и представляет собой систематический код – код, в котором информационные и контрольные биты расположены на строго определенных местах в кодовой комбинации.
Код Хэмминга, как и любой (n, k)- код, содержит к информационных и m = n-k избыточных (проверочных) бит.
Избыточная часть кода строится т. о. чтобы можно было при декодировании не только установить наличие ошибки но, и указать номер позиции в которой произошла ошибка , а значит и исправить ее, инвертировав значение соответствующего бита.
Существуют различные методы реализации кода Хэмминга и кодов которые являются модификацией кода Хэмминга. Рассмотрим алгоритм построения кода для исправления одиночной ошибки.
1. По заданному количеству информационных символов - k, либо информационных комбинаций N = 2k , используя соотношения:
n = k+m, 2n ³ (n+1)2k и 2m ³ n+1 (14)
m = [log2 {(k+1)+ [log2(k+1)]}]
вычисляют основные параметры кода n и m.
2. Определяем рабочие и контрольные позиции кодовой комбинации. Номера контрольных позиций определяются по закону 2i, где i=1, 2, 3,... т.е. они равны 1, 2, 4, 8, 16,… а остальные позиции являются рабочими.
3. Определяем значения контрольных разрядов (0 или 1 ) при помощи многократных проверок кодовой комбинации на четность. Количество проверок равно m = n-k. В каждую проверку включается один контро-льный и определенные проверочные биты. Если результат проверки дает четное число, то контрольному биту присваивается значение -0, в противном случае - 1. Номера информационных бит, включаемых в каждую проверку, определяются по двоичному коду натуральных n –чисел разрядностью – m (табл. 1, для m = 4) или при помощи проверочной матрицы H(m´n), столбцы которой представляют запись в двоичной системе всех целых чисел от 1 до 2k –1 перечисленных в возрастающем порядке. Для m = 3 проверочная матрица имеет вид
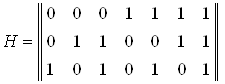 . (15 )
. (15 )
Количество разрядов m - определяет количество проверок.
В первую проверку включают коэффициенты, содержащие 1 в младшем (первом) разряде, т. е. b1, b3, b5 и т. д.
Во вторую проверку включают коэффициенты, содержащие 1 во втором разряде, т. е. b2, b3, b6 и т. д.
В третью проверку - коэффициенты которые содержат 1 в третьем разряде и т. д.
Таблица 1
|
Десятичные числа (номера разрядов кодовой комбинации) |
Двоичные числа и их разряды | ||
| 3 | 2 | 1 | |
|
1 2 3 4 5 6 7 |
0 0 0 1 1 1 1 |
0 1 1 0 0 1 1 |
1 0 1 0 1 0 1 |
Для обнаружения и исправления ошибки составляются аналогичные проверки на четность контрольных сумм, результатом которых является двоичное (n-k) -разрядное число, называемое синдромом и указывающим на положение ошибки, т. е. номер ошибочной позиции, который определяется по двоичной записи числа, либо по проверочной матрице.
Для исправления ошибки необходимо проинвертировать бит в ошибочной позиции. Для исправления одиночной ошибки и обнаружения двойной используют дополнительную проверку на четность. Если при исправлении ошибки контроль на четность фиксирует ошибку, то значит в кодовой комбинации две ошибки.
Схема кодера и декодера для кода Хэмминга приведена на рис. 1.
Пример 1. Построить код Хемминга для передачи сообщений в виде последовательности десятичных цифр, представленных в виде 4 –х разрярных двоичных слов. Показать процесс кодирования, декодирования и исправления одиночной ошибки на примере информационного слова 0101.
Решение:
1. По заданной длине информационного слова (k = 4), определим количество контрольных разрядов m, используя соотношение:
m = [log2 {(k+1)+ [log2(k+1)]}]=[log2 {(4+1)+ [log2(4+1)]}]=3,
при этом n = k+m = 7, т. е. получили (7, 4) -код.
2. Определяем номера рабочих и контрольных позиции кодовой комбинации. Номера контрольных позиций выбираем по закону 2i .
Для рассматриваемой задачи (при n = 7) номера контрольных позиций равны 1, 2, 4. При этом кодовая комбинация имеет вид:
b1 b2 b3 b4 b5 b6 b7
к1 к2 0 к3 1 0 1
3. Определяем значения контрольных разрядов (0 или 1), используя проверочную матрицу (5).
Первая проверка:
k1 Å b3Å b5Å b7 = k1Å0Å1Å1 будет четной при k1 = 0.
Вторая проверка:
k2 Å b3Å b6Å b7 = k2Å0Å0Å1 будет четной при k2 = 1.
Третья проверка:
k3 Å b5Å b6Å b7 = k3Å1Å0Å1 будет четной при k3 = 0.
1 2 3 4 5 6 7
Передаваемая кодовая комбинация: 0 1 0 0 1 0 1
Допустим принято: 0 1 1 0 1 0 1
Для обнаружения и исправления ошибки составим аналогичные про-верки на четность контрольных сумм, в соответствии с проверочной матрицей результатом которых является двоичное (n-k) -разрядное число, называемое синдромом и указывающим на положение ошибки, т. е, номер ошибочной позиции.
1) k1 Å b3Å b5Å b7 = 0Å1Å1Å1 = 1.
2) k2 Å b3Å b6Å b7 = 1Å1Å0Å1 = 1.
3) k3 Å b5Å b6Å b7 = 0Å1Å0Å1 = 0.
Сравнивая синдром ошибки со столбцами проверочной матрицы, определяем номер ошибочного бита. Синдрому 011 соответствует третий столбец, т. е. ошибка в третьем разряде кодовой комбинации. Символ в 3 -й позиции необходимо изменить на обратный.
Пример 2. Построить код Хэмминга для передачи кодовой комбинации 1 1 0 1 1 0 1 1. Показать процесс обнаружения и исправления ошибки в соответствующем разряде кодовой комбинации.
Решение: Рассмотрим алгоритм построения кода для исправления одиночной ошибки.
1. По заданной длине информационного слова (k = 8) , используя соотношения вычислим основные параметры кода n и m.
m = [log2 {(k+1)+ [log2(k+1)]}]=[log2 {(9+1)+ [log2(9+1)]}]=4,
при этом n = k+m = 12, т. е. получили (12, 8)-код.
2. Определяем номера рабочих и контрольных позиции кодовой комбинации. Номера контрольных позиций выбираем по закону 2i .
Для рассматриваемой задачи (при n = 12) номера контрольных позиций равны 1, 4, 8.
При этом кодовая комбинация имеет вид:
b1 b2 b3 b4 b5 b6 b7 b8 b9 b10 b11 b12
к1 к2 1 к3 1 0 1 к4 1 0 1 1
3. Определяем значения контрольных разрядов (0 или 1) путем много-кратных проверок кодовой комбинации на четность. Количество проверок равно m = n-k. В каждую проверку включается один контрольный и определенные проверочные биты.
Номера информационных бит, включаемых в каждую проверку определяется по двоичному коду натуральных n-чисел разрядностью - m.
0001 b1 Количество разрядов m - определяет количество прове-
0010 b2 верок.
0011 b3 1) к1Å b3 Å b5Å b7Å b9Å а11 = к1Å1Å1Å1Å1Å1 =>
0100 b4 четная при к1=1
0101 b5 2) к2Å b3Å b6Å b7Å b10Å b11= к2Å1Å0Å1Å0Å1 =>
0110 b6 четная при к2=1
0111 b7 3) к3Å b5Å b6Å b7Å b12 = к3Å1Å0Å1Å1=>
1000 b8 четная при к3=1
1001 b9 4) к4Å b9Å b10Å b11Å b12 = к1Å1Å0Å1Å1 =>
1010 b10 четная при к4=1
1011 b11
1100 b12
Передаваемая кодовая комбинация: 1 2 3 4 5 6 7 8 9 10 11 12
1 1 1 1 1 0 1 1 1 0 1 1
Допустим, принято: 1 1 1 1 0 0 1 1 1 0 1 1
Для обнаружения и исправления ошибки составим аналогичные про-верки на четность контрольных сумм, результатом которых является двоичное (n-k) -разрядное число, называемое синдромом и указывающим на положение ошибки, т. е. номер ошибочной позиции.
1) к1Å b3Å b5Å b7Å b9Å b11 = 1Å1Å0Å1Å1Å1 =1
2) к2Å b3Å b6Å b7Å b10Å b11 = 1Å1Å0Å1Å0Å1 =0
3) к3Å b5Å b6Å b7Å b12 = 1Å0Å0Å1Å1 =1
4) к4Å b9Å b10Å b11Å b12 = 1Å1Å0Å1Å1 =0
Обнаружена ошибка в разряде кодовой комбинации с номером 0101, т. е. в 5 -м разряде. Для исправления ошибки необходимо проинвертировать 5 -й разряд в кодовой комбинации.
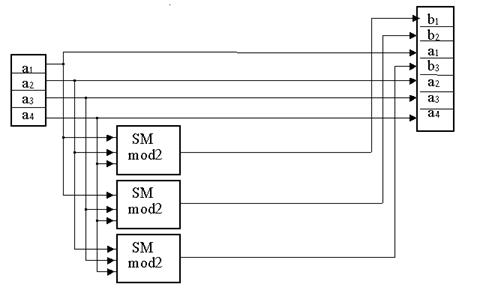
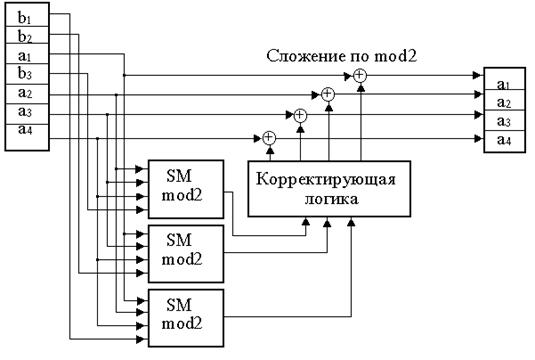
Рис. 1. Схема кодера -а и декодера б для простого (7, 4) кода Хэмминга
Рассмотрим применение кода Хэмминга. В ЭВМ код Хэмминга чаще всего используется для обнаружения и исправления ошибок в ОП, памяти с обнаружением и исправлением ошибок ECC Memory (Error Checking and Correcting). Код Хэмминга используется как при параллельной, так и при последовательной записи. В ЭВМ значительная часть интенсивности потока ошибок приходится на ОП. Причинами постоянных неисправностей являются отказы ИС, а случайных изменение содержимого ОП за счет флуктуации питающего напряжения, кратковременных помех и излучений. Неисправность может быть в одном бите, линии выборки разряда, слова либо всей ИС. Сбой может возникнуть при формировании кода (параллельного), адреса или данных, поэтому защищать необходимо и то и др. Обычно дешифратор адреса встроен в м/схему и недоступен для потребителя. Наиболее часто ошибки дают ячейки памяти ЗУ, поэтому главным образом защищают записываемые и считываемые данные.
Наибольшее применение в ЗУ нашли коды Хэмминга с dmin=4, исправляющие одиночные ошибки и обнаруживающие двойные.
Проверочные символы записываются либо в основное, либо специальное ЗУ. Для каждого записываемого информационного слова (а не байта, как при контроле по паритету) по определенным правилам вычисляется функция свертки, результат которой разрядностью в несколько бит также записывается в память. Для 16 -ти разрядного информационного слова используется 6 дополнительных бит (32- 7 бит, 64 –8 бит). При считывании информации схема контроля, используя избыточные биты, позволяет обнаружить ошибки различной кратности или исправить одиночную ошибку. Возможны различные варианты поведения системы:
- автоматическое исправление ошибки без уведомления системы;
- исправление однократной ошибки и уведомление системы только о многократных ошибках;
- не исправление ошибки, а только уведомление системы об ошибках;
Модуль памяти со встроенной схемой исправления ошибок –EOS 72/64 (ECC on Simm). Аналог микросхема к 555 вж 1 -это 16 разрядная схема с обнаружением и исправлением ошибок (ОИО) по коду Хэмминга (22, 16), использование которой позволяет исправить однократные ошибки и обнаружить все двух кратные ошибки в ЗУ.
Избыточные (контрольные) разряды позволяют обнаружить и исправить ошибки в ЗУ в процессе записи и хранения информации.
В составе ВЖ-1 используются 16 информационных и 6 контрольных разрядов. (DB - информационное слово, CB - контрольное слово).
При записи осуществляется формирование кода, состоящего из 16 информационных и 6 контрольных разрядов, представляющих результат суммирование по модулю 2 восьми информационных разрядов в соответствии с кодом Хэмминга. Сформированные контрольные разряды вместе с информационными поступают на схему и записываются в ЗУ.
|
|
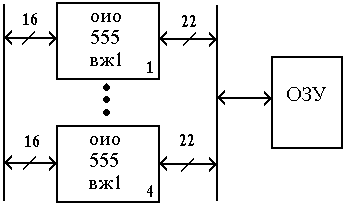
Рис.2. Схема контроля
При считывании шестнадцатиразрядное слово декодируется, восстанавливаясь вместе с 6 разрядным словом контрольным, поступают на схему сравнения и контроля. Если достигнуто равенство всех контрольных разрядов и двоичных слов, то ошибки нет.
Любая однократная ошибка в 16 разрядном слове данных изменяет 3 байта в 6 разрядном контрольном слове. Обнаруженный ошибочный бит инвертируется.
Список Литературы
1. Гриценко В.М, Недвоичные арифметические корректирующие коды, Пробл. передачи информ., 5:4 (1969), 19–27
2. Злотник Б.М. Помехоустойчивые коды в системах связи.—M.: Радио и связь, 1989.—232 c.
3. Кловский Д.Д. Теория передачи сигналов. –М.: Связь, 1984.
4. Ковалгин Ю.А., Вологдин Э. И. Цифровое кодирование звуковых сигналов. Издательство: Корона-Принт, 2004. 240с.
5. Колесник В.Д., Полтырев Г.Ш. Курс теории информации. М.: Наука, 2006.
6. Микропроцессорные кодеры и декодеры/В.М. Муттер, Г.А. Петров и др.—М.: Радио и связь, 1991.—184 с.
7. Питерсон У., Коды, исправляющие ошибки, пер. с англ., М., 1964.
8. Семенюк В.В. Экономное кодирование дискретной информации. – СПб.: СПбГИТМО (ТУ), 2001
© 2010 Интернет База Рефератов