
Рефераты по сексологии
Рефераты по информатике программированию
Рефераты по биологии
Рефераты по экономике
Рефераты по москвоведению
Рефераты по экологии
Краткое содержание произведений
Рефераты по физкультуре и спорту
Топики по английскому языку
Рефераты по математике
Рефераты по музыке
Остальные рефераты
Рефераты по авиации и космонавтике
Рефераты по административному праву
Рефераты по безопасности жизнедеятельности
Рефераты по арбитражному процессу
Рефераты по архитектуре
Рефераты по астрономии
Рефераты по банковскому делу
Рефераты по биржевому делу
Рефераты по ботанике и сельскому хозяйству
Рефераты по бухгалтерскому учету и аудиту
Рефераты по валютным отношениям
Рефераты по ветеринарии
Рефераты для военной кафедры
Рефераты по географии
Рефераты по геодезии
Рефераты по геологии
Рефераты по геополитике
Рефераты по государству и праву
Рефераты по гражданскому праву и процессу
Рефераты по делопроизводству
Рефераты по кредитованию
Рефераты по естествознанию
Рефераты по истории техники
Рефераты по журналистике
Рефераты по зоологии
Рефераты по инвестициям
Рефераты по информатике
Исторические личности
Рефераты по кибернетике
Рефераты по коммуникации и связи
Контрольная работа: Паралельні обчислення з використанням MPI
Контрольная работа: Паралельні обчислення з використанням MPI
Контрольна робота
Паралельні обчислення з використанням MPI
Зміст
1. Введення в паралельні обчислення
2. Що таке MPI/MPICH?
3. MPI у прикладах
3.1 Найпростіша MPI-програма
3.2 Обмін повідомленнями
3.3 Колективний обмін даними
3.4 Паралельний введення-виведення
4. Додаток
Література/посилання
Завдання
1. Введення в паралельні обчислення


Основна ідея розпаралелювання обчислень – мінімізація часу виконання задачі за рахунок розподілу навантаження між декількома обчислювальними пристроями. Цими «обчислювальними пристроями» можуть бути як процесори одного суперкомп'ютера, так і кілька комп'ютерів рангом поменше, обєднаних за допомогою комунікаційної мережі в єдину обчислювальну структуру – кластер.
Паралельна модель програмування сильно відрізняється від звичайно послідовної. Існують дві моделі паралельного програмування: модель паралелізм даних і модель паралелізму задач. Модель паралелізми даних має на уваз незалежну обробку даних кожним процесом (наприклад, векторні операції з масивами). Модель паралелізами задач передбачає розбивка основної задачі на трохи щодо самостійних підзадач, кожна з яких виконується окремо й обмінюється даними з іншими. Це більш трудомісткий, у порівнянні з паралелізмом даних, підхід. Перевагою є велика гнучкість і велика воля, надана програмісту в розробці програми, що ефективно використовує ресурси паралельної системи. При цьому можуть застосовуватися спеціалізовані бібліотеки, що беруть на себе вс «організаційні» задачі. Приклади таких бібліотек: MPI (Message Passing Interface) і PVM (Parallel Virtual Machine).
При розробці паралельних програм виникають специфічні для дано моделі обчислень проблеми сугубо технічного характеру: забезпечення комунікацій між підзадачами, забезпечення надійності й ефективності цих комунікацій, дозвіл проблем зв'язаних із загальним доступом до поділюваних ресурсів та інше. Для рішення цих проблем можна реалізувати власні методи, а можна використовувати вже готові стандарти/специфікації/бібліотеки. MPI – «Інтерфейс передач повідомлень» - це специфікація, що була розроблена в 1993-1994 роках групою MPI Forum (http://www.mpi-forum.org),і забезпечує реалізацію моделі обміну повідомленнями між процесами. Остання версія даної специфікації MPI-2. У модел програмування MPI програма породжує кілька процесів, взаємодіючих між собою за допомогою звертання до підпрограм прийому і передачі повідомлень.
Звичайно, при ініціалізації MPI-програми створюється фіксований набір процесів, причому (що, утім, необов'язково) кожний з них виконується на своєму процесорі. У цих процесах можуть виконуватися різні програми, тому MPI-модель іноді називають MPMD-моделлю (Multiple Program, Multiple Data), на відміну від SPMD (Single Program…)моделі, де на кожному процесорі виконуються тільки однакові задачі. MPI підтримує двохточкові і глобальні, синхронні й асинхронні, блокуючі і типи комунікацій, що неблокують. Спеціальний механізм – комунікатор ховає від програміста внутрішні комунікаційні структури. Структура комунікацій може змінюватися протягом часу життя процесу, але кількість задач повинна залишатися постійним (MPI-2 уже підтримує динамічна зміна числа задач).
Специфікація MPI забезпечує переносимість програм на рівн вихідних кодів і велику функціональність. Підтримується робота на гетерогенних кластерах і симетричних мультипроцесорних системах. Не підтримується, як уже відзначалося, запуск процесів під час виконання MPI-програми. У специфікац відсутні опису паралельного введення-висновку і налагодження програм – ц можливості можуть бути включені до складу конкретної реалізації MPI у вид додаткових пакетів і утиліт. Сумісність різних реалізацій не гарантується.
Важливою властивістю паралельної програми є детермінізм – програма повинна завжди давати той самий результат для того самого набору вхідних даних. Модель передачі повідомлень, загалом даною властивістю не володіє, оскільки не визначений порядок одержання повідомлень від двох процесів третім. Якщо ж один процес послідовно посилає кілька повідомлень іншому процесу, MPI гарантує, що одержувач одержить їхній саме в тім порядку, у якому вони були відправлені. Відповідальність за забезпечення детермінованого виконання програми лягає на програміста (з цього приводу див. приклад 3).
MPICH – MPI Chameleon – одна з реалізацій MPICH яка підтриму роботу на великому числі платформ із різними комунікаційними інтерфейсами, у т.ч. і TCP/IP.
Основні особливості MPICH v 1.2.2:
повна сумісність зі специфікацією MPI-1;
наявність інтерфейсу в стилі MPI-2 з функціями для мови C++ з специфікації MPI-1;
наявність інтерфейсу з процедурами мови FORTRAN-77/90;
є реалізація для Windows NT (несумісна з UNIX-реалізацією);
підтримка великого числа архітектур, у т.ч. кластерів, SMP і т.д.;
часткова підтримка MPI-2;
часткова підтримка паралельного введення-висновку – ROMIO;
наявність засобів трасування і протоколювання (SLOG-based);
наявність засобів візуалізації продуктивності паралельних програм (upshot і jumpshot);
наявність у складі MPICH тестів продуктивності і перевірки функціонування системи.
Недоліки MPICH – неможливість запуску процесів під час роботи програми і відсутність засобів моніторингу за поточним станом системи.
До складу MPICH входять бібліотечні і заголовні файли, що реалізують біля сотні підпрограм. Ми будемо розглядати реалізацію MPICH.NT 1.2.4 для Windows NT.
3.1 Найпростіша MPI-програма
Ми почнемо наше знайомство з MPI з вивчення найпростішої програми:
===== Example1.cpp =====
#include <mpi.h> // очевидно;)
#include <stdio.h>
int main(int argc, char* argv[])
{
int myrank, size;
MPI_Init(&argc,&argv); // Ініціалізація MPI
MPI_Comm_size(MPI_COMM_WORLD,&size); // Розмір комунікатора
MPI_Comm_rank(MPI_COMM_WORLD,&myrank); // Одержуємо наш номер
printf("Proc %d of %d\n",myrank,size);
MPI_Finalize(); // Фіналізація MPI
puts ("Done.");
return 0;
}
===== Example1.cpp =====
Перед викликом будь-якої процедури MPI, потрібно викликати ніціалізацію MPI_Init, перед цим викликом може знаходитися тільки виклик MPI_Initialized, призначення якого очевидно. MPI_Init крім усього іншого створює глобальний комунікатор MPI_COMM_WORLD, через которий буде проходити обмін повідомленнями. Область взаємодії комунікатора MPI_COMM_WORLD – усі процеси даної програми. Якщо є необхідність у розбивці області взаємодії на більш дрібні сегменти (частково-широкомовні розсилання), використовуються виклики MPI_Comm_dup/create/split/etc (тут не розглядаються). Розмір комунікатора, одержуваний викликом MPI_Comm_size – число процесів у ньому. Розмір комунікатора MPI_COMM_WORLD – загальне число процесів. Кожен процес має свій унікальний (у рамках комунікатора!) номер – ранг. Ранги процесів у контекстах різних комунікаторів можуть розрізнятися. Після виконання всіх обмінів повідомленнями в програмі повинний розташовуватися виклик MPI_Finalize() процедура видаляє всі структури даних MPI і робить інші необхідні дії. Програміст повинний сам подбати про те, щоб до моменту виклику MPI_Finalize ус пересилання даних були довершені. Після виконання MPI_Finalize виклик будь-яких, крім MPI_Initialized, процедур (навіть MPI_Init!) неможливий. MPI_Initialized у даному випадку буде показувати, визивал-ли процес MPI_Init. Отже, уже стало ясно, що наша програма виводить повідомлення від усіх породжених нею процесів. Приклад висновку (порядок повідомлень, що надходять від процесів, може і буде мінятися) приведений нижче (np - кількість процесів):
Example1 output (np = 3):
Proc 1 of 3
Done.
Proc 0 of 3
Done.
Proc 2 of 3
Done.
Зверніть увагу, що після виклику MPI_Finalize() паралелізм не закінчується – “Done” виводиться кожним процесом.
Вправа 1: У принципі, такого об’єму вже досить, щоб писати програми в моделі паралелізму даних – напишіть який-небудь приклад.
У MPI існує величезна множина процедур обміну повідомленнями. Вони можуть використовуватися, як для посилки керуючих сигналів, так і для передач даних (ці випадки будуть розглянуті в прикладах 3 і 4). Два основних види обміну: двухточений і глобальний. Останній буде описаний пізніше.
З погляду програміста, двохточковий обмін виконується в такий спосіб: для пересилання повідомлення процес-джерело викликає підпрограму передачі, при звертанні до якої вказується ранг процесу-одержувача (адресата) у відповідній області взаємодії. Остання задається своїм комунікатором, звичайно це MPI_COMM_WORLD. Процес-одержувач, для того, щоб одержати спрямоване йому повідомлення, викликає підпрограму прийому, указавши при цьому ранг джерела.


Нагадаємо, що MPI гарантує виконання деяких властивостей двохточкового обміну, таких як збереження порядку повідомлень, і гарантоване виконання обміну. Якщо один процес посилає повідомлення, а іншої - запит на його прийом, то або передача, або прийом будуть вважатися виконаними. При цьому можливі три сценарії обміну:
другий процес одержує від першого адресоване йому повідомлення;
відправлене повідомлення може бути отримано третім процесом, при цьому фактично виконана буде передача повідомлення, а не його прийом (повідомлення пройшло повз адресата);
другий процес одержує повідомлення від третього, тоді передача не може вважатися виконаної, тому що адресат одержав не те "лист".
У двохточковом обміні слід дотримуватися правила відповідност типів переданих і прийнятих даних. Це утрудняє обмін повідомленнями між програмами, написаними на різних мовах програмування.
Існують чотири різновиди крапкового обміну: синхронний, асинхронний, блокуючий і неблокуючий. У MPI маються також чотири режими обміну, що розрізняються умовами ініціалізації і завершення передачі повідомлення:
стандартна передача вважається виконаною і завершується, як тільки повідомлення відправлене, незалежно від того, дійшло воно до чи адресата ні. У стандартному режимі передача повідомлення може починатися, навіть якщо ще не початий його прийом;
синхронна передача відрізняється від стандартної тим, що вона не завершується доти, поки не буде довершений прийом повідомлення. Адресат, одержавши повідомлення, посилає процесу, що відправив його, повідомлення, що повинне бути отримане відправником для того, щоб обмін вважався виконаним. Операцію передачі повідомлення іноді називають "рукостисканням";
буферизована передача завершується відразу ж, повідомлення копіюється в системний буфер, де й очікує своєї черги на пересилання. Завершується буферизованна передача незалежно від того, виконаний прийом чи повідомлення ні;
передача "по готовності" починається тільки в тому випадку, коли адресат ініціалізував прийом повідомлення, а завершується відразу, незалежно від того, прийняте чи повідомлення ні.
Кожний з цих чотирьох режимів існує як у що блокуючий, так і в неблокуючій формах. При формі прийому, що блокуючий,/передачі виконання програми припиняється по завершення виконання операції.
У MPI прийняті наступні угоди про імена підпрограм двохточкового обміну: MPI_[I][R|S|B]Send. Префікс I (Immediate) позначає режим, неблокуючий, один із префіксів R|S|B позначає режим обміну по відповідно готовності, синхронний і буферизований, відсутність префікса позначає стандартний обмін. Разом – 8 різновидів передачі повідомлень. Для прийому ж існує всього 2 різновиди: MPI_[I]Recv. Приклади: MPI_Irsend - виконує передачу «по готовності» у режимі, неблокуючий, MPI_Bsend - буферизована передача з блокуванням, MPI_Recv - прийом, що блокуючий. Відзначимо, що підпрограма прийому будь-якого типу може прийняти повідомлення від будь-якої програми передачі. Перейдемо до приклада 2:
===== Example2.cpp =====
#include <mpi.h>
#include <stdio.h>
#define TAG_SEND_FWD 99
#define TAG_SEND_BACK 98
#define TAG_REPLY 97
int main(int argc, char* argv[])
{
int k,x;
int myrank, size;
MPI_Status status;
MPI_Init(&argc,&argv);
MPI_Comm_size(MPI_COMM_WORLD,&size);
MPI_Comm_rank(MPI_COMM_WORLD,&myrank);
if (myrank == 0) // призначимо один процес головним
{
puts("Running procs forwards"); fflush(stdout); // негайний вивід повідомлення
x=1;
while (x < size)
{
MPI_Ssend(&x, 1, MPI_INT, x, TAG_SEND_FWD, MPI_COMM_WORLD);
MPI_Recv (&k, 1, MPI_INT, x, TAG_REPLY, MPI_COMM_WORLD, &status);
printf("Reply from proc %d received %d\n",x,k); fflush(stdout);
x++;
}
puts("Running procs backwards"); fflush(stdout);
x=size-1;
while (x >0)
{
MPI_Send(&x,1, MPI_INT, x, TAG_SEND_BACK, MPI_COMM_WORLD);
x--;
}
else // інші процеси - підлеглі
{
MPI_Recv(&k, 1, MPI_INT, 0, TAG_SEND_FWD, MPI_COMM_WORLD, &status);
printf("Proc %d received %d\n",myrank,k); fflush(stdout);
MPI_Ssend(&k,1, MPI_INT, 0, TAG_REPLY, MPI_COMM_WORLD);
MPI_Recv(&k, 1, MPI_INT, 0, TAG_SEND_BACK, MPI_COMM_WORLD, &status);
printf("Proc %d Received %d\n",myrank,k); fflush(stdout);
}
MPI_Finalize();
return 0;
}
===== Example2.cpp =====
У цьому прикладі один із процесів (з рангом 0) розсила повідомлення іншому у прямому, а потім у зворотному порядку.
Прототип функції: int MPI_[..]Send(void* buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm).
Вхідні параметри (однакові для усіх функцій *send):
buf – адреса першого елемента в буфері передачі
count – кількість елементів у буфері передачі
| Тип даних MPI | Тип даних З |
| MPI_CHAR | signed char |
| MPI_SHORT | signed short int |
| MPI_INT | signed int |
| MPI_LONG | signed long int |
| MPI_UNSIGNED_CHAR | unsigned char |
| MPI_UNSIGNED_SHORT | unsigned short int |
| MPI_UNSIGNED | unsigned int |
| MPI_UNSIGNED_LONG | unsigned long int |
| MPI_FLOAT | float |
| MPI_DOUBLE | double |
| MPI_LONG_DOUBLE | long double |
| MPI_BYTE | Н відповідності |
| MPI_PACKED | Н відповідності |
datatype – тип MPI кожного переданого елемента. MPI визнача власні типи даних, схожі на типи даних C, однак, існують і унікальні для MPI типи (див. таблицю відповідності). У MPI повинні дотримуватися правила сумісності типів, з базових типів можуть бути сконструйовані більш складні.
dest – ранг процесу-одержувача повідомлення. Ранг тут – ціле число від 1 до n-1, де n – число процесів в області взаємодії
tag – тег – унікальний ідентифікатор повідомлення
comm – комунікатор.
Стандартна передача, що блокуючий, починається незалежно від того, чи був зареєстрований відповідний прийом, а завершується тільки після того, як повідомлення прийняте системою і процес-джерело може знову використовувати буфер передачі. Повідомлення може бути скопійоване прямо в буфер прийому, а може бути поміщене в тимчасовий системний буфер, де і буде чекати виклику адресатом підпрограми прийому. У цьому випадку говорять про буферизац повідомлення. Передача може завершитися ще до виклику відповідної операц прийому. З іншого боку, буфер може бути недоступний чи MPI може вирішити не буферизувати вихідні повідомлення з міркувань збереження високо продуктивності. У цьому випадку передача завершиться тільки після того, як буде зареєстровані відповідний прийом і дані будуть передані адресату.
Прийом виконується підпрограмою:
int MPI_Recv (void *buf, int count, MPI_Datatype datatype, int source, int tag, MPI_Comm comm, MPI_Status * status)
Її вхідні параметри (у MPI_Irecv – такі ж):
count – максимальна кількість елементів у буфері прийому. Фактична хня кількість можна визначити за допомогою підпрограми MPI_Get_count;
datatype – тип прийнятих даних. Нагадаємо про необхідність дотримання відповідності типів аргументів підпрограм прийому і передачі;
source – ранг джерела. Можна використовувати спеціальне значення mpi_any_source, що відповідає довільному значенню рангу. У програмуванн дентифікатор, що відповідає довільному значенню параметра, часто називають "джокером". Цей термін будемо використовувати і ми;
tag – тег чи повідомлення "джокер" mpi_any_tag, що відповідає довільному значенню тега;
comm — комунікатор. При вказівці комунікатора "джокери" використовувати не можна.
Варто мати на увазі, що при використанні значень mpi_any_source (будь-яке джерело) і mpi_any_tag (будь-який тег) є небезпеку прийому повідомлення, не призначеного даному процесу.
Вихідними параметрами є:
buf – початкова адреса буфера прийому. Його розмір повинний бути достатнім, щоб розмістити прийняте повідомлення, інакше при виконанні прийому відбудеться збій – виникне помилка переповнення;
status – статус обміну – спеціальна структура MPI.
Якщо повідомлення менше, ніж буфер прийому, змінюється вміст лише тих комірок пам'яті буфера, що відносяться до повідомлення. Інформація про довжину прийнятого повідомлення міститься в одному з полів статусу, але до ц нформації в програміста немає прямого доступу (як до поля рядка чи елементу масиву). Розмір отриманого повідомлення (count) можна визначити за допомогою виклику підпрограми MPI_Get_count:
int MPI_Get_count (MPI_Status *status, MPI_Datatype datatype, int *count)
Аргумент datatype повинний відповідати типу даних, зазначеному в операції обміну.
Висновок Example2 output(np = 6): Ssend & replies
Running procs forwards
Proc 1 received 1
Reply from proc 1 received 1
Proc 2 received 2
Reply from proc 2 received 2
Proc 3 received 3
Reply from proc 3 received 3
Proc 4 received 4
Reply from proc 4 received 4
Proc 5 received 5
Reply from proc 5 received 5
Running procs backwards
Proc 5 Received 5
Proc 4 Received 4
Proc 3 Received 3
Proc 2 Received 2
Proc 1 Received 1
Завдання 1: Проаналізуйте висновок приклада. Спробуйте забрати зворотні повідомлення (replies), що зміниться? Застосуєте різні сполучення *send (Send,Ssend,Rsend) і прокоментуйте відповідні висновки програм.
Завдання 2: Зміните топологію пересилання повідомлень у Прикладі 2 з «зірки» на «кільце» (див. мал.). Проробіть усі те ж, що й у Завданні 1.
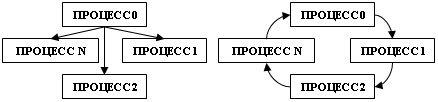

3.3 Колективний обмін даними.
У двохточковому обміні беруть участь два процеси – джерело повідомлення його адресат. При виконанні колективного обміну кількість "діючих облич" зростає. Повідомлення пересилається від одного процесу декільком чи, навпаки, один процес "збирає" дані від декількох процесів. MPI підтримує такі види колективного обміну, як широкомовну передачу, операції приведення і т.д. У MPI маються підпрограми, що виконують операц розподілу і збору даних, глобальні математичні операції, такі як підсумовування елементів чи масиву обчислення його максимального елемента і т.д.
У будь-якому колективному обміні бере участь кожен процес з деяко області взаємодії. Можна організувати обмін і в підмножині процесів, для цього маються засоби створення нових областей взаємодії і відповідних їм комунікаторів. Колективні обміни характеризуються наступним:
колективні обміни не можуть взаємодіяти з двохточковими. Колективна передача, наприклад, не може бути перехоплена двохточковой підпрограмою прийому;
колективні обміни можуть виконуватися як із синхронізацією, так без її;
усі колективні обміни є блокирующими для їхній обменаЭЪ, що ніціював;
теги повідомлень призначаються системою.
Широкомовне розсилання
Широкомовне розсилання виконується одним виділеним процесом, що називається головним (root), а всі інші процеси, що приймають участь в обміні, одержують по одній копії повідомлення від головного процесу:
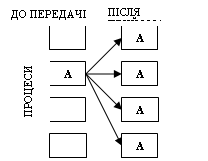


Виконується широкомовне розсилання за допомогою підпрограми
int MPI_Bcast(void *buffer, int count, MPI_Datatype datatype, int root, MPI_Comm comm)
Її параметри одночасно є вхідними і вихідними:
buffer — адреса буфера;
count — кількість елементів даних у повідомленні;
datatype — тип даних MPI;
root — ранг головного процесу, що виконує широкомовне розсилання;
comm — комунікатор.
Обмін із синхронізацією
Синхронізація за допомогою "бар'єра" є найпростішою формою синхронізації колективних обмінів. Вона не вимагає пересилання даних. Підпрограма MPI_Barrier блокуючий виконання кожного процесу з комунікатора comm доти, поки всі процеси не викликають цю підпрограму: int MPI_Barrier(MPI_Comm comm)
Розподіл і збір даних
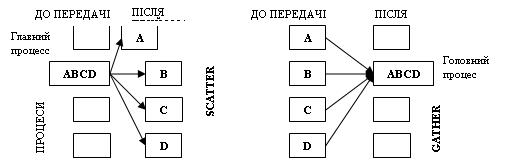
Розподіл і збір даних виконуються за допомогою підпрограм MPI_Scatter і MPI_Gather відповідно. Список аргументів в обох підпрограм однаковий, але діють вони по-різному.
Схеми передачі даних для операцій збору і розподілу даних приведені на малюнках.

Повний список підпрограм розподілу і збору даний приведений у таблиці:
| Підпрограма | Короткий опис |
| MPI_Allgather | Збирає дані від усіх процесів і пересилає їх усім процесам |
| MPI_Allgatherv |
Збирає дані від усіх процесів і пересилає їх усім процесам ("векторний" варіант підпрограми MPI_Allgather) |
| MPI_Allreduce | Збирає дані від усіх процесів, виконує операцію приведення, і результат розподіляє всім процесам |
| MPI_Alltoall | Пересилає дан від усіх процесів усім процесам |
| MPI_Alltoallv | Пересилає дан від усіх процесів усім процесам ("векторний" варіант підпрограми MPI_Alltoall) |
| MPI_Gather | Збирає дані від групи процесів |
| MPI_Gatherv | Збирає дані від групи процесів ("векторний" варіант підпрограми MPI Gather) |
| MPI_Reduce | Викону операцію приведення, тобто обчислення єдинного значення по масиву вихідних даних |
| MPI_Reduce_scatter | Збір значень з наступним розподілом результата операції приведення |
| MPI_Scan | Виконання операції сканування (часткова редукція) для даних від групи процесів |
| MPI_Scatter | Розподіляє дан від одного процесу всім іншим процесам у групі |
| MPI_Scatterv | Пересилає буфер вроздріб усім процесам у групі ("векторний" варіант підпрограми MPI_Scatter) |
При широкомовному розсиланні всім процесам передається той самий набір даних, а при розподілі передаються його частини. Виконує розподіл даних підпрограмою MPI_Scatter, що пересилає дані від одного процесу всім іншим процесам у групі так, як це показано на малюнку.
int MPI_Scatter(void *sendbuf, int sendcount, MPI_Datatype sendtype, void *rcvbuf, int rcvcount, MPI_Datatype rcvtype, int root, MPI_Comm comm)
Її вхідні параметри (параметри підрограми MPI_Gather такі ж):
sendbuf – адреса буфера передачі;
sendcount – кількість елементів, що пересилаються кожному процесу (але не сумарна кількість елементів, що пересилаються,);
sendtype – тип переданих даних;
rcvcount – кількість елементів у буфері прийому;
rcvtype – тип прийнятих даних;
root – ранг передавального процесу;
comm – комунікатор.
Вихідний параметр rcvbuf – адреса буфера прийому. Працює ця підпрограма в такий спосіб. Процес з рангом root ("головний процес") розподіляє вміст буфера передачі sendbuf серед усіх процесів. Уміст буфера передачі розбивається на кілька фрагментів, кожний з який містить sendcount елементів. Перший фрагмент передається процесу 0, другий процесу 1 і т.д. Аргументи send мають значення тільки на стороні процесу root.
При зборці (MPI_Gather) кожен процес у комунікаторі comm пересила вміст буфера передачі sendbuf процесу з рангом root. Процес root "склеює" отримані дані в буфері прийому. Порядок склейки визначається рангами процесів, тобто в результуючому наборі після даних від процесу 0 випливають дані від процесу 1, потім дані від процесу 2 і т.д. Аргументи rcvbuf, rcvcount і rcvtype відіграють роль тільки на стороні головного процесу. Аргумент rcvcount указує кількість елементів даних, отриманих від кожного процесу (але не їхня сумарна кількість). При виклику підпрограм MPI_scatter MPI_Gather з різних процесів варто використовувати загальний головний процес.
Операції приведення і сканування
Операції приведення і сканування відносяться до категор глобальних обчислень. У глобальній операції приведення до даних від усіх процесів із заданого комунікатора застосовується операція MPI_Reduce (див рис).
Аргументом операції приведення є масив даних — по одному елемент від кожного процесу. Результат такої операції — єдине значення (тому вона називається операцією приведення).
У підпрограмах глобальних обчислень функція, передана в підпрограму, може бути: визначеною функцією MPI, наприклад MPI_SUM, користувальницькою функцією, а також оброблювачем для користувальницько функції, що створюється підпрограмою MPI_Op_create.
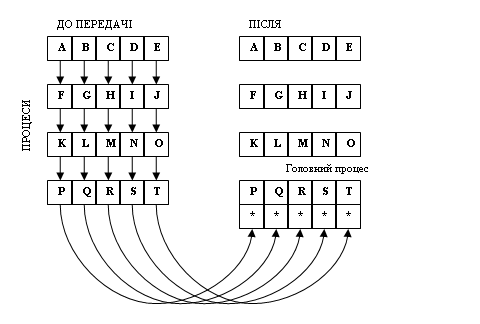

Три версії операції приведення повертають результат:
одному процесу;
усім процесам;
розподіляють вектор результатів між усіма процесами.
Операція приведення, результат якої передається одному процесу, виконується при виклику підпрограми MPI_Reduce:
int MPI_Reduce(void *buf, void *result, int count, MPI_Datatype datatype, MPI_Op op, int root, MPI_Comm comm)
Вхідні параметри підпрограми MPI_Reduce:
buf — адреса буфера передачі;
count — кількість елементів у буфері передачі;
datatype — тип даних у буфері передачі;
ор — операція приведення;
root — ранг головного процесу;
comm — комунікатор.
Підпрограма MPI_Reduce застосовує операцію приведення до операндам з buf, а результат кожної операції міститься в буфер результату result. MPI_Reduce повинна викликатися всіма процесами в комунікаторі comm, a аргументи count, datatype і op у цих викликах повинні збігатися. Функція приведення (ор) не повертає код помилки, тому при виникненні аварійної ситуації або завершується робота всієї програми, або помилка мовчазно ігнорується. І те й нше в однаковій мірі небажано.
У MPI мається 12 визначених операцій приведення (див. табл.).
| Операція | Опис |
| MPI_MAX | Визначення максимальних значень елементів одномірних масивів цілого чи речовинного типу |
| MPI_MIN | Визначення мінімальних значень елементів одномірних масивів цілого чи речовинного типу |
| MPI_SUM | Обчислення суми елементів одномірних масивів цілого, речовинного чи комплексного типу |
| MPI_PROD | Обчислення заелементного добутку одномірних масивів цілого, речовинного чи комплексного типу |
| MPI_LAND | Логічне "И" |
| MPI_BAND | Бітове "И" |
| MPI_LOR | Логічне "ЧИ" |
| MPI_BOR | Бітове "ЧИ" |
| MPI_LXOR | Логічне "ЧИ", що виключає |
| MPI_BXOR | Бітове "ЧИ", що виключає |
| MPI_MAXLOC | Максимальн значення елементів одномірних масивів і їхні індекси |
| MPI_MINLOC | Мінімальн значення елементів одномірних масивів і їхні індекси |
Розглянемо приклад 3:
===== Example2.cpp =====
#include <mpi.h>
#include <stdio.h>
#include <math.h>
int main(int argc, char *argv[])
{
int n, myid, numprocs, i;
double PI25DT = 3.141592653589793238462643;
double mypi, pi, h, sum, x;
MPI_Init(&argc,&argv);
MPI_Comm_size(MPI_COMM_WORLD,&numprocs);
MPI_Comm_rank(MPI_COMM_WORLD,&myid);
while (1) {
if (myid == 0) {
printf("Enter the number of intervals: (0 quits) ");
scanf("%d",&n);
}
MPI_Bcast(&n, 1, MPI_INT, 0, MPI_COMM_WORLD);
if (n == 0)
break;
else {
h = 1.0 / (double) n;
sum = 0.0;
for (i = myid + 1; i <= n; i += numprocs) { //розподіл навантаження
x = h * ((double)i - 0.5);
sum += (4.0 / (1.0 + x*x));
}
mypi = h * sum;
MPI_Reduce(&mypi, &pi, 1, MPI_DOUBLE, MPI_SUM, 0, MPI_COMM_WORLD);
//зборка результату
if (myid == 0)
printf("pi is approximately %.16f, Error is %.16f\n",
pi, fabs(pi - PI25DT));
}
MPI_Finalize();
return 0;
}
===== Example2.cpp =====
Ця програма обчислює число π методом підсумовування ряду. Спочатку один із процесів (0) запитує число інтервалів, що потім поширює іншим процедурою MPI_Bcast. Помітьте, що процедура MPI_Bcast для процесу 0 передавальної, а для всіх інших – приймаючої. Кінцеві результати обчислень здаються процесу 0 для підсумовування: процедура
MPI_Reduce(&mypi,&pi,1,MPI_DOUBLE,MPI_SUM,0,MPI_COMM_WORLD)
збирає з усіх процесів перемінну mypi, підсумовує (MPI_SUM), зберігає результат у змінної pi процесу 0.
Вивід приклада: Example3 output (np = 6)
Process 5 on apc-pc.
Process 3 on apc-pc.
Process 0 on apc-pc.
Enter the number of intervals: (0 quits) Process 1 on apc-pc.
Process 2 on apc-pc.
Process 4 on apc-pc.
15
pi is approximately 3.1419630237914191, Error is 0.0003703702016260
wall clock time = 0.031237
Enter the number of intervals: (0 quits) 2
pi is approximately 3.1623529411764704, Error is 0.0207602875866773
wall clock time = 0.000943
Enter the number of intervals: (0 quits) 0
Завдання 1: поясніть вивід;)
Приклад 4 показує створення комплексної системи керування процесами на прикладі розподіленого дешифратора паролів. Використовується структура master-slave (головн-підлеглий).
===== Example4.cpp =====
#include <mpi.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define TAG_READY 99
#define TAG_RESULT 98
int do_decrypt_pass(char* incoming_pass_str, char * result_pass_str, int length)
{
if (length % 2 == 0) return 1;
else return 0;
}
int main(int argc, char* argv[])
{
int k,x;
char in_line[256],acc_name[256],acc_pass[256];
int myrank, size;
MPI_Status status;
MPI_Init(&argc,&argv);
MPI_Comm_size(MPI_COMM_WORLD,&size);
MPI_Comm_rank(MPI_COMM_WORLD,&myrank);
if (myrank == 0) // kind'a Master Process
{
puts("Initializing"); fflush(stdout);
FILE* in_file = fopen("pass.txt","r");
for (x=1;x<size;x++) MPI_Recv (&k, 1, MPI_INT, x, TAG_READY, MPI_COMM_WORLD, &status);
char* p;
puts ("Feeding"); fflush(stdout);
sprintf(in_line,"apc::1234");
if (p = strtok(in_line,"::")) sprintf(acc_name,"%s",p); else return 0;
if (p = strtok(NULL,"::")) sprintf(acc_pass,"%s",p); else return 0;
int acc_name_len = strlen(acc_name)+1, acc_pass_len = strlen(acc_pass)+1;
MPI_Bcast(&acc_name_len, 1, MPI_INT, 0, MPI_COMM_WORLD); MPI_Barrier(MPI_COMM_WORLD);
MPI_Bcast(&acc_pass_len, 1, MPI_INT, 0, MPI_COMM_WORLD); MPI_Barrier(MPI_COMM_WORLD);
MPI_Bcast(&acc_name, acc_name_len, MPI_CHAR, 0, MPI_COMM_WORLD); MPI_Barrier(MPI_COMM_WORLD);
MPI_Bcast(&acc_pass, acc_pass_len, MPI_CHAR, 0, MPI_COMM_WORLD); MPI_Barrier(MPI_COMM_WORLD);
for (x=1;x<size;x++)
{
MPI_Probe(MPI_ANY_SOURCE, TAG_RESULT, MPI_COMM_WORLD, &status);
int src = status.MPI_SOURCE; int res;
MPI_Recv(&res, 1, MPI_INT, src, TAG_RESULT, MPI_COMM_WORLD, &status);
printf("Proc %d returned %d\n",src,res);fflush(stdout);
}
}
else
{
MPI_Ssend(&myrank, 1, MPI_INT, 0, TAG_READY, MPI_COMM_WORLD);
int acc_name_len, acc_pass_len;
MPI_Bcast(&acc_name_len, 1, MPI_INT, 0, MPI_COMM_WORLD); MPI_Barrier(MPI_COMM_WORLD);
MPI_Bcast(&acc_pass_len, 1, MPI_INT, 0, MPI_COMM_WORLD); MPI_Barrier(MPI_COMM_WORLD);
MPI_Bcast(&acc_name, acc_name_len, MPI_CHAR, 0, MPI_COMM_WORLD); MPI_Barrier(MPI_COMM_WORLD);
MPI_Bcast(&acc_pass, acc_pass_len, MPI_CHAR, 0, MPI_COMM_WORLD); MPI_Barrier(MPI_COMM_WORLD);
printf("Proc %d: recv %s:: %s\n",myrank,acc_name,acc_pass);fflush(stdout);
char[256] ret_pass;
int result = do_decrypt_pass(&acc_pass, &ret_pass, myrank);
MPI_Ssend(&result, 1, MPI_INT, 0, TAG_RESULT, MPI_COMM_WORLD);
}
MPI_Finalize();
return 0;
}
===== Example4.cpp =====
У цьому прикладі головний процес (ранг 0) чекає підключення всіх підлеглих процесів (посилки ними повідомлення з тегом TAG_READY), розсилає рядок in_line усім підлеглим процесам, що намагаються підібрати пароль довжини myrank (тобто власний номер процесу). Власне зломом займається функція int do_decrypt_pass(char* incoming_pass_str, char * result_pass_str, int length)
Процеси повертають результат підбора c повідомленням TAG_RESULT. MPI_Barrier використовується для синхронізації. Висновок приклада:
Example4 output (np = 5)
Initializing
Feeding
Proc 1: recv apc:: 1234
Proc 2: recv apc:: 1234
Proc 3: recv apc:: 1234
Proc 1 returned 0
Proc 4: recv apc:: 1234
Proc 3 returned 0
Proc 2 returned 1
Proc 4 returned 1
У цьому прикладі всі процеси ламають той самий пароль, і новий цикл (не реалізований у прикладі) не почнеться, поки не завершать роботу вс процеси. Отже, час одного циклу визначається часом роботи процесу з максимальним рангом (тобто виконуючого підбор найбільшої довжини => перебір найбільшого числа комбінацій).
Приклад 5 показує більш зроблену систему, що читає з необхідну нформацію з файлу, і роздає кожному процесу по паролі. Процеси працюють в асинхронному режимі, зв'язуючи з головним процесом, що відіграє роль «роздавального-прийомного центра», організовуючи систему дуже схожу на «клієнта-сервер».
Завдання 2: Після вивчення коду поясніть, чому це не є системою клієнт-сервер.
===== Example5.cpp =====
#include <mpi.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
//типи повідомлень
#define TAG_MSG 98 // службове повідомлення – зміст перемінної – код (див. нижче)
#define TAG_SEND_NAMELEN 97 // пересилається довжина рядка мені
#define TAG_SEND_PASSLEN 96 // пересилається довжина рядка пароля
#define TAG_SEND_NAME 95 // пересилається рядок імені
#define TAG_SEND_PASS 94 // пересилається рядок імені
#define MSG_FAILURE 0 // невдача при розшифровці
#define MSG_SUCCESS 1 // успіх при розшифровці
#define MSG_READY 2 // клієнт готовий до прийому наступного пароля
#define MSG_GO_ON 3 // сигнал клієнту продовжувати роботу
#define MSG_BREAK 5 // сигнал клієнту завершити роботу
int do_decrypt_pass(int param);
int main(int argc, char* argv[])
{
int x,result;
char in_line[256],acc_name[256],acc_pass[256],racc_name[256],racc_pass[256];
int myrank, size;
MPI_Status status;
MPI_Init(&argc,&argv);
MPI_Comm_size(MPI_COMM_WORLD,&size);
MPI_Comm_rank(MPI_COMM_WORLD,&myrank);
if (myrank == 0) // kind'a Master Process
{
puts("Initializing"); fflush(stdout);
FILE* in_file = fopen("pass.txt","r");
char* p;
int allok=1,numclients=size-1;
int acc_name_len,acc_pass_len,racc_name_len,racc_pass_len;
while (allok || numclients)
{
MPI_Probe(MPI_ANY_SOURCE, TAG_MSG, MPI_COMM_WORLD, &status); // модель подій!
int src = status.MPI_SOURCE;
MPI_Recv(&result, 1, MPI_INT, src, TAG_MSG, MPI_COMM_WORLD, &status); // Чекаємо повідомлень від клієнтів
printf("<<< Proc %d returned %d\n",src,result);fflush(stdout);
switch(result)
{
case MSG_SUCCESS:
MPI_Recv(&racc_name_len, 1, MPI_INT, src,TAG_SEND_NAMELEN, MPI_COMM_WORLD, &status);
MPI_Recv(&racc_pass_len, 1, MPI_INT, src,TAG_SEND_PASSLEN, MPI_COMM_WORLD, &status);
MPI_Recv(&racc_name, racc_name_len, MPI_CHAR, src, TAG_SEND_NAME, MPI_COMM_WORLD, &status);
MPI_Recv(&racc_pass, racc_pass_len, MPI_CHAR, src, TAG_SEND_PASS, MPI_COMM_WORLD, &status);
printf ("[+] Proc %d got: %s:: %s\n",src,racc_name,racc_pass);fflush(stdout);
break;
case MSG_FAILURE:
MPI_Recv(&racc_name_len, 1, MPI_INT, src, TAG_SEND_NAMELEN, MPI_COMM_WORLD, &status);
MPI_Recv(&racc_name, racc_name_len, MPI_CHAR, src, TAG_SEND_NAME, MPI_COMM_WORLD, &status);
printf ("[-] Proc %d couldn't break: %s in set limits\n",src,racc_name);fflush(stdout);
break;
case MSG_READY: // вільний робітник
if (!fgets(in_line,256,in_file)) allok =0; // готуємо account info
if (p = strtok(in_line,"::")) sprintf(acc_name,"%s",p); else allok= 0; //
if (p = strtok(NULL,"::")) sprintf(acc_pass,"%s",p); else allok= 0; //
if (allok) x = MSG_GO_ON; else { x = MSG_BREAK; numclients--;}// якщо є рядок – «згодовуємо»
MPI_Ssend(&x, 1, MPI_INT, src, TAG_MSG, MPI_COMM_WORLD);// клієнту. Інакше (файл
// закінчився) – гасимо клієнта.
if (allok)
{
acc_name_len = strlen(acc_name)+1, acc_pass_len = strlen(acc_pass)+1;
printf (">>> Feeding %s:: %s to proc %d\n",acc_name,acc_pass, src);fflush(stdout);
MPI_Ssend(&acc_name_len, 1, MPI_INT, src,TAG_SEND_NAMELEN, MPI_COMM_WORLD);
MPI_Ssend(&acc_pass_len, 1, MPI_INT, src,TAG_SEND_PASSLEN, MPI_COMM_WORLD);
MPI_Ssend(&acc_name, acc_name_len, MPI_CHAR, src, TAG_SEND_NAME, MPI_COMM_WORLD);
MPI_Ssend(&acc_pass, acc_pass_len, MPI_CHAR, src, TAG_SEND_PASS, MPI_COMM_WORLD);
}
break;
}
}
printf ("[%d] Process exits\n",myrank);fflush(stdout);
}
else
{
int acc_name_len, acc_pass_len;
while (1)
{
x = MSG_READY;
MPI_Ssend(&x, 1, MPI_INT, 0, TAG_MSG, MPI_COMM_WORLD);// Посилаємо сигнал готовності
printf("[%d] Waiting\n",myrank);fflush(stdout);
MPI_Recv(&x, 1, MPI_INT, 0, TAG_MSG, MPI_COMM_WORLD, &status);
if (x == MSG_BREAK) // Вирішуємо, що робити далі
{
printf("[%d] BREAK received \n",myrank);fflush(stdout);
break;
}
MPI_Recv(&acc_name_len, 1, MPI_INT, 0,TAG_SEND_NAMELEN, MPI_COMM_WORLD, &status);
MPI_Recv(&acc_pass_len, 1, MPI_INT, 0,TAG_SEND_PASSLEN, MPI_COMM_WORLD, &status);
MPI_Recv(&acc_name, acc_name_len, MPI_CHAR, 0, TAG_SEND_NAME, MPI_COMM_WORLD, &status);
MPI_Recv(&acc_pass, acc_pass_len, MPI_CHAR, 0, TAG_SEND_PASS, MPI_COMM_WORLD, &status);
printf("[%d] Proc recv %s:: %s\n",myrank,acc_name,acc_pass);fflush(stdout);
int result = do_decrypt_pass(myrank);// Розшифровуємо пароль
switch (result) // Відсилаємо результат
{
case MSG_SUCCESS:
MPI_Ssend(&result, 1, MPI_INT, 0, TAG_MSG, MPI_COMM_WORLD);
MPI_Ssend(&acc_name_len, 1, MPI_INT, 0,TAG_SEND_NAMELEN, MPI_COMM_WORLD);
MPI_Ssend(&acc_pass_len, 1, MPI_INT, 0,TAG_SEND_PASSLEN, MPI_COMM_WORLD);
MPI_Ssend(&acc_name, acc_name_len, MPI_CHAR, 0, TAG_SEND_NAME, MPI_COMM_WORLD);
MPI_Ssend(&acc_pass, acc_pass_len, MPI_CHAR, 0, TAG_SEND_PASS, MPI_COMM_WORLD);
break;
case MSG_FAILURE:
MPI_Ssend(&result, 1, MPI_INT, 0, TAG_MSG, MPI_COMM_WORLD);
MPI_Ssend(&acc_name_len, 1, MPI_INT, 0,TAG_SEND_NAMELEN, MPI_COMM_WORLD);
MPI_Ssend(&acc_name, acc_name_len, MPI_CHAR, 0, TAG_SEND_NAME, MPI_COMM_WORLD);
break;
}
}
printf ("[%d] Process exits\n",myrank);fflush(stdout);
}
MPI_Finalize();
return 0;
}
int do_decrypt_pass(int param)
{
if (param % 2 == 0) return 1;
else return 0;
}
===== Example5.cpp =====
У цьому прикладі головний процес (master) займається керуванням ншими «робітниками» процесами (slave), а також відає постачанням і збором нформації. Підпрограма
MPI_Probe (int source, int tag, MPI_Comm comm, MPI_Status *status)
перевіряє наявність повідомлень, готових до прийому. Її варіант, неблокуючий - MPI_Iprobe(int source, int tag, MPI_Comm comm, int *flag, MPI_Status *status) - якщо повідомлення вже надійшло і може бути прийнято, повертається значення прапора «істина». Інакше (повідомлення надійшло нецілком) «неправду». Виклик процедури, що блокуючий, MPI_Probe з параметрами MPI_ANY_SOURCE і MPI_ANY_TAG зупиняє виконання майстра-процесу до надходження якого-небудь повідомлення, реалізуючи в рамках процесу модель подій. Далі в залежності від повідомлення, що надійшло, майстер-процес або приймає результати (успіх/невдача) з висновком відповідного повідомлення, або видає робочому процесу черговий набір інформації інформації (логін-пароль). Якщо всі парол вже роздані – робочому процесу посилається сигнал BREAK. Висновок приклада 5: Example5 output (np = 5)
Initializing
[2] Waiting
<<< Proc 2 returned 2
>>> Feeding apc:: 12345 to proc 2
[3] Waiting
<<< Proc 3 returned 2
>>> Feeding admin:: aa5632 to proc 3
[2] Proc recv apc:: 12345
[1] Waiting
<<< Proc 1 returned 2
>>> Feeding bionicman:: 3995d to proc 1
[3] Proc recv admin:: aa5632
[4] Waiting
<<< Proc 4 returned 2
>>> Feeding root:: *** to proc 4
[1] Proc recv bionicman:: 3995d
<<< Proc 2 returned 1
[4] Proc recv root:: ***
[+] Proc 2 got: apc:: 12345
<<< Proc 3 returned 0
[-] Proc 3 couldn't break: admin in set limits
<<< Proc 1 returned 0
[-] Proc 1 couldn't break: bionicman in set limits
<<< Proc 4 returned 1
[+] Proc 4 got: root:: ***
[2] Waiting
<<< Proc 2 returned 2
>>> Feeding vasya:: 1234nasja to proc 2
[3] Waiting
<<< Proc 3 returned 2
>>> Feeding jmanderley:: 1a2_+3 to proc 3
[2] Proc recv vasya:: 1234nasja
[1] Waiting
<<< Proc 1 returned 2
>>> Feeding man:: aa6321 to proc 1
[3] Proc recv jmanderley:: 1a2_+3
[4] Waiting
<<< Proc 4 returned 2
>>> Feeding demeter:: 3ss9951 to proc 4
[1] Proc recv man:: aa6321
<<< Proc 2 returned 1
[4] Proc recv demeter:: 3ss9951
[+] Proc 2 got: vasya:: 1234nasja
<<< Proc 3 returned 0
[-] Proc 3 couldn't break: jmanderley in set limits
<<< Proc 1 returned 0
[-] Proc 1 couldn't break: man in set limits
<<< Proc 4 returned 1
[+] Proc 4 got: demeter:: 3ss9951
[2] Waiting
<<< Proc 2 returned 2
>>> Feeding wheeljack:: *3472364%s to proc 2
[3] Waiting
<<< Proc 3 returned 2
[2] Proc recv wheeljack:: *3472364%s
>>> Feeding dalain:: 4nas5t to proc 3
[1] Waiting
<<< Proc 1 returned 2
[3] Proc recv dalain:: 4nas5t
>>> Feeding nobode:: * to proc 1
[4] Waiting
<<< Proc 4 returned 2
[1] Proc recv nobode:: *
>>> Feeding lamer:: password to proc 4
<<< Proc 2 returned 1
[4] Proc recv lamer:: password
[+] Proc 2 got: wheeljack:: *3472364%s
<<< Proc 3 returned 0
[-] Proc 3 couldn't break: dalain in set limits
<<< Proc 1 returned 0
[-] Proc 1 couldn't break: nobode in set limits
<<< Proc 4 returned 1
[+] Proc 4 got: lamer:: password
[2] Waiting
<<< Proc 2 returned 2
>>> Feeding cewl:: asfuh$Kjsfhdf&34kd to proc 2
[3] Waiting
<<< Proc 3 returned 2
>>> Feeding hacker:: to proc 3
[2] Proc recv cewl:: asfuh$Kjsfhdf&34kd
[1] Waiting
<<< Proc 1 returned 2
>>> Feeding LASTONE:: LASTPASS to proc 1
[3] Proc recv hacker::
[4] Waiting
<<< Proc 4 returned 2
<<< Proc 2 returned 1
[1] Proc recv LASTONE:: LASTPASS
[4] BREAK received
[4] Process exits
[+] Proc 2 got: cewl:: asfuh$Kjsfhdf&34kd
<<< Proc 3 returned 0
[-] Proc 3 couldn't break: hacker in set limits
<<< Proc 1 returned 0
[-] Proc 1 couldn't break: LASTONE in set limits
[2] Waiting
<<< Proc 2 returned 2
[3] Waiting
[2] BREAK received
[2] Process exits
<<< Proc 3 returned 2
[1] Waiting
[3] BREAK received
[3] Process exits
<<< Proc 1 returned 2
[0] Process exits
[1] BREAK received
[1] Process exits
3.4 Паралельне введення-виведення.
Останній приклад 6 показує, можна було вирішити ту ж задачу простіше:
===== Example6.cpp =====
#include <mpi.h>
#include <stdio.h>
#include <string.h>
int do_decrypt_pass(int param)
{
if (param % 2 == 0) return 1;
else return 0;
}
int main(int argc, char* argv[])
{
char in_line[256],acc_name[256],acc_pass[256];
FILE * file_in;
int myrank, size;
MPI_Init(&argc,&argv);
MPI_Comm_size(MPI_COMM_WORLD,&size);
MPI_Comm_rank(MPI_COMM_WORLD,&myrank);
file_in = fopen("pass.txt","r");
printf("[%d]: file open\n",myrank); fflush(stdout);
char* p;
for (int i=0; i<= myrank;i++) fgets(in_line,256,file_in);
while (!feof(file_in))
{
if (p = strtok(in_line,"::")) sprintf(acc_name,"%s",p);
if (p = strtok(NULL,"::")) sprintf(acc_pass,"%s",p);
printf("[%d] Read: %s:: %s\n",myrank,acc_name,acc_pass); fflush(stdout);
int result = do_decrypt_pass(myrank);
if (result ==1) {printf ("[+] Proc %d got: %s:: %s\n",myrank,acc_name,acc_pass);fflush(stdout);}
else {printf ("[-] Proc %d couldn't break: %s in set limits\n",myrank,acc_name);fflush(stdout);}
for (int i=0; i< size;i++) fgets(in_line,256,file_in);
}
printf ("[%d]: Process exits\n",myrank);fflush(stdout);
MPI_Finalize();
return 0;
}
===== Example6.cpp =====
У коді немає нічого нового, тому розбір його залишаємо на самостійне проробку.
Example6 output (np =)
[0]: file open
[0] Read: apc:: 12345
[1]: file open
[1] Read: admin:: aa5632
[-] Proc 1 couldn't break: admin in set limits
[1] Read: vasya:: 1234nasja
[+] Proc 0 got: apc:: 12345
[0] Read: root:: ***
[+] Proc 0 got: root:: ***
[0] Read: man:: aa6321
[-] Proc 1 couldn't break: vasya in set limits
[1] Read: demeter:: 3ss9951
[2]: file open
[2] Read: bionicman:: 3995d
[+] Proc 2 got: bionicman:: 3995d
[2] Read: jmanderley:: 1a2_+3
[+] Proc 2 got: jmanderley:: 1a2_+3
[2] Read: wheeljack:: *3472364%s
[+] Proc 0 got: man:: aa6321
[0] Read: dalain:: 4nas5t
[+] Proc 0 got: dalain:: 4nas5t
[0] Read: cewl:: asfuh$Kjsfhdf&34kd
[-] Proc 1 couldn't break: demeter in set limits
[1] Read: nobode:: *
[-] Proc 1 couldn't break: nobode in set limits
[1] Read: hacker::
[+] Proc 2 got: wheeljack:: *3472364%s
[2] Read: lamer:: password
[+] Proc 2 got: lamer:: password
[2] Read: LASTONE:: LASTPASS
[+] Proc 2 got: LASTONE:: LASTPASS
[2]: Process exits
[+] Proc 0 got: cewl:: asfuh$Kjsfhdf&34kd
[0]: Process exits
[-] Proc 1 couldn't break: hacker in set limits
[1]: Process exits
Хоча в MPICH існує власна бібліотека вводу-виводу ROMIO, ми не користаємося нею, а просто відкриваємо файл у режимі read-only.
Завдання 1: довести, що даний метод не суперечить тем лабораторної роботи (у відповідь на питання: «А чому не з ROMIO?»);)
4. Додаток
Як корисний додаток рекомендується почитати MPICH User Guide (поставляється разом з пакетом) – у ньому міститься інформація про установку настроювання MPICH а також інформація з настроювання MSDEV для написання MPICH-програм. У каталозі з лабораторною роботою є файли з прикладами, а також кілька текстів інших MPI-програм для ознайомлення.
1. MPI Forum: http://www.mpi-forum.org
2. MPICH: http://www-unix.mcs.anl.gov/mpi/mpich
3. http://parallel.ru
4. http://www.csa.ru, http://www.ptc.spbu.ru, http://www.hpc.nw.ru, http://www.hi-hpc.nw.ru
5. Книга «Параллельное программирование для многопроцессорних вичислительних систем» (С. Немнюгин, О. Стесик, Изд БХВ-Петербург, 2002).
6. www.google.com і www.yandex.ru для пошуку всього інші.
Крім виконання всіх завдань, викладених вище, потрібно реалізувати одну з нижчеперелічених алгоритмів у моделі MPI.
Зломщик паролів
Довести зломщик паролів до прийнятного виду і реалізувати його в схемі клієнт-сервер з використанням TCP/IP (БЕЗ MPI). Порівняти продуктивність трудовитрати.
Напишіть сортування перерахуванням.
Напишіть сортування методом пухирця.
Напишіть сортування методом quick sort.
Напишіть програму множення матриць методом Фокса (Fox).
Над полем P задані матриці:
![]() ,
,![]()
Потрібно знайти матрицю
![]() , де
, де ![]() .
.
Опис алгоритму:
Нехай маємо топологію типу ґрати
![]() ,
,![]() .
.
Нехай також ![]() .
.
Матриця A розбивається на блоки
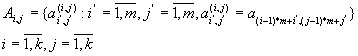
Аналогічно розбиваються матриці B і C.
Програма для процесора ![]() :
:

У результаті на процесорі ![]() :
: ![]()
Напишіть програму множення матриць методом Кэннона (Cannon)
Матриця A розбивається на блоки
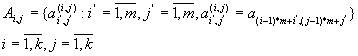
Аналогічно розбиваються матриці B і C.
Програма для процесора ![]() :
:

У результаті на процесорі ![]() :
:![]()
Напишіть програму розвязок систем лінійних рівнянь (методи Зейделя/Якобі).
Кінцево-різницевий алгоритм рішення диференціальний рівнянь
Запрограмуйте двовимірний кінцево-різницевий алгоритм рішення диференціальний рівнянь і проведіть вимір продуктивності для різної кількост процесорів.
Напишіть програму транспонування матриці Nx на M процесорах.
Кожному процесу передається N/M рядків, а він повертає N/M колонок. Спробуйте використовувати різні види обміну і порівняєте результати. Проведіть вимір продуктивності.
Напишіть паралельну програму в який створюються N груп процесів обмін між цими групами виконується по кільцю.
Необхідно буде розібратися з групами процесів і комунікаторами (MPI_Group_create, MPI_Comm_create, etc)
Проведіть дослідження швидкодії глобальний операцій MPI для різно кількості процесів і різних розмірів повідомлень.
Напишіть програми, у яких колективні операції обміну реалізован за допомогою підпрограм двохточкового обміну. Оцініть трудовитрати продуктивність.
Для даного масиву напишіть програму обчислення мінімального/максимального елемента масиву, не використовуючи операц приведення MPI. Зробіть те ж з використанням операцій приведення. Порівняєте.
Напишіть програму обчислення скалярного добутку векторів a і b.
Напишіть програму обчислення матричного добутку.
Дано матриці A і B. Напишіть програму обчислення матриці AB-BA.
Дано матрицю A і вектори a,b. Напишіть обчислення p = (a,Ab)
Дано матрицю A і вектори a,b. Напишіть обчислення c = a - Ab
Маємо файл, що містить записи для кожного працівника. Кожна запис включає прізвище, ім'я, рік народження і рік прийому на роботу. Напишіть програму, у якій один із процесів розподіляє всім іншим приблизно однаково порції інформації, а ці процеси формують список співробітників, стаж яких складає більш 5 років.
Результати пересилаються головному процесу, що їх виводить у файл. Використовувати ідею, але не код(!) приклада 5.
© 2010 Интернет База Рефератов