
Рефераты по сексологии
Рефераты по информатике программированию
Рефераты по биологии
Рефераты по экономике
Рефераты по москвоведению
Рефераты по экологии
Краткое содержание произведений
Рефераты по физкультуре и спорту
Топики по английскому языку
Рефераты по математике
Рефераты по музыке
Остальные рефераты
Рефераты по авиации и космонавтике
Рефераты по административному праву
Рефераты по безопасности жизнедеятельности
Рефераты по арбитражному процессу
Рефераты по архитектуре
Рефераты по астрономии
Рефераты по банковскому делу
Рефераты по биржевому делу
Рефераты по ботанике и сельскому хозяйству
Рефераты по бухгалтерскому учету и аудиту
Рефераты по валютным отношениям
Рефераты по ветеринарии
Рефераты для военной кафедры
Рефераты по географии
Рефераты по геодезии
Рефераты по геологии
Рефераты по геополитике
Рефераты по государству и праву
Рефераты по гражданскому праву и процессу
Рефераты по делопроизводству
Рефераты по кредитованию
Рефераты по естествознанию
Рефераты по истории техники
Рефераты по журналистике
Рефераты по зоологии
Рефераты по инвестициям
Рефераты по информатике
Исторические личности
Рефераты по кибернетике
Рефераты по коммуникации и связи
Курсовая работа: Алгоритмы сортировки, поиска кратчайшего пути в графе и поиска покрытия, близкого к кратчайшему
Курсовая работа: Алгоритмы сортировки, поиска кратчайшего пути в графе и поиска покрытия, близкого к кратчайшему
Содержание
Введение
1 Выбор варианта задания
2 Алгоритм сортировки Шейкер
2.1 Математическое описание задачи
2.2 Словесное описание алгоритма и его работы
2.3 Описание схемы алгоритма
2.4 Контрольный пример
3 Алгоритм покрытия: построение одного кратчайшего покрытия
3.1 Математическое описание задачи
3.2 Словесное описание алгоритма и его работы
3.3 Описание схемы алгоритма
3.4 Контрольный пример
4 Алгоритм на графах: нахождение кратчайшего пути
4.1 Математическое описание задачи
4.2 Словесное описание алгоритма и его работы
4.3 Описание схемы алгоритма
4.4 Контрольный пример
Заключение
Перечень литературы
Введение
Алгоритм это точно определенная (однозначная) последовательность простых (элементарных) действий, обеспечивающих решение любой задачи из некоторого класса, т.е. такой набор инструкций, который можно реализовать чисто механически, вне зависимости от умственных способностей и возможностей исполнителя.
Как заметил Кнут: «Алгоритм должен быть определен настолько четко, чтобы его указаниям мог следовать даже компьютер».
Теория алгоритмов и практика их построения и анализа является концептуальной основой разнообразных процессов обработки информации. В настоящее время теория алгоритмов образует теоретический фундамент вычислительных наук. Применение теории алгоритмов осуществляется как в использовании самих результатов (особенно это касается использования разработанных алгоритмов), так и в обнаружении новых понятий и уточнении старых. С ее помощью проясняются такие понятия как доказуемость, эффективность, разрешимость, перечислимость и другие.
Эффективность алгоритма определяется анализом, который должен дать четкое представление, во-первых, о емкостной и, во-вторых, о временной сложности процесса.
Речь идет о размерах памяти, в которой предстоит размещать все данные, участвующие в вычислительном процессе (естественно, к ним относятся входные наборы, промежуточная и выходная информация), а также физических ресурсах, затраченных исполнителем.
В курсовой работе представлены различные подходы и методы использования алгоритмов, приведены оценки сложностей алгоритмов, реализации математических задач с помощью алгоритмов. Проведена краткая характеристика используемых структур данных, эффективность их применения в данной задаче
1 ВЫБОР ВАРИАНТА
Номер варианта определяется нахождением остатка от целочисленного деления числа У, которое является суммой числа Х и номера по списку в журнале. Номер по списку в журнале N=9. Таким образом:
X=Nгр*100=5*100=500;
Y=N+X=9+500=509.
По формулам нахожу соответствующие виды алгоритмов.
1) (Y mod 4) + 1 =(509 mod 4) + 1=1 + 1= 2; Алгоритм покрытия: построение одного кратчайшего покрытия.
2) (Y mod 6) + 1 =(509 mod 6) + 1 = 5 + 1=6; Алгоритм на графах: поиск кратчайшего пути.
3) (Y mod 5) + 1 =(509 mod 5) +1 =4 + 1 = 5; Алгоритм сортировки: сортировка-шейкер.
2 АЛГОРИТМ СОРТИРОВКИ: СОРТИРОВКА ШЕЙКЕР
2.1 Математическое описание задачи
Сортировка это перестановка элементов некоторого множества в заданном порядке при некоторой упорядочивающей функцию.
Сортировка используется для облегчения поиска элемента в таком отсортированном множестве.
Задача сортировки решается с помощью таких алгоритмов: сортировка с помощью прямого включения, прямого выбора, прямого обмена, включений с уменьшающимися расстояниями, дерева, разделения и другие.
2.2 Словесное описание алгоритма и его работы
Сортировка Шейкер является усовершенствованной сортировкой методом пузырька. Идея метода: шаг сортировки состоит в проходе снизу вверх по массиву. По пути просматриваются пары соседних элементов. Если элементы некоторой пары находятся в неправильном порядке, то меняем их местами.(см. Таб. 1)
Таблица 1
| i=1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 44 | 06 | 06 | 06 | 06 | 06 | 06 | 06 |
| 55 | 44 | 12 | 12 | 12 | 12 | 12 | 12 |
| 12 | 55 | 44 | 18 | 18 | 18 | 18 | 18 |
| 42 | 12 | 55 | 44 | 42 | 42 | 42 | 42 |
| 94 | 42 | 18 | 55 | 44 | 44 | 44 | 44 |
| 18 | 94 | 42 | 42 | 55 | 55 | 55 | 55 |
| 06 | 18 | 94 | 94 | 67 | 67 | 67 | 67 |
| 67 | 67 | 67 | 67 | 94 | 94 | 94 | 94 |
После нулевого прохода по массиву "вверху" оказывается самый "легкий" элемент - отсюда аналогия с пузырьком. Следующий проход делается до второго сверху элемента, таким образом второй по величине элемент поднимается на правильную позицию.
Делаем проходы по все уменьшающейся нижней части массива до тех пор, пока в ней не останется только один элемент. На этом сортировка заканчивается, так как последовательность упорядочена по возрастанию. Среднее число сравнений и обменов имеют квадратичный порядок роста: отсюда можно заключить, что алгоритм пузырька очень медленен и малоэффективен.
Тем не менее, у него есть громадный плюс: он прост и его можно по-всякому улучшать. Чем мы сейчас и займемся. Во-первых, рассмотрим ситуацию, когда на каком-либо из проходов не произошло ни одного обмена. Что это значит ? Это значит, что все пары расположены в правильном порядке, так что массив уже отсортирован. И продолжать процесс не имеет смысла(особенно, если массив был отсортирован с самого начала !). Итак, первое улучшение алгоритма заключается в запоминании, производился ли на данном проходе какой-либо обмен. Если нет - алгоритм заканчивает работу. Процесс улучшения можно продолжить, если запоминать не только сам факт обмена, но и индекс последнего обмена k. Действительно: все пары соседих элементов с индексами, меньшими k, уже расположены в нужном порядке. Дальнейшие проходы можно заканчивать на индексе k, вместо того чтобы двигаться до установленной заранее верхней границы i.
Качественно другое улучшение алгоритма можно получить из следующего наблюдения. Хотя легкий пузырек снизу поднимется наверх за один проход, тяжелые пузырьки опускаются со минимальной скоростью: один шаг за итерацию. Так что массив 2 3 4 5 6 1 будет отсортирован за 1 проход, а сортировка последовательности 6 1 2 3 4 5 потребует 5 проходов.
Чтобы избежать подобного эффекта, можно менять направление следующих один за другим проходов. Получившийся алгоритм называют "шейкер-сортировкой". Далее проведена программа на языке С++, реализующая сортировку Шейкер.
template<class T>
void shakerSort(T a[], long size) {
long j, k = size-1;
long lb=1, ub = size-1; // границы неотсортированной части массива
T x;
do {
// проход снизу вверх
for( j=ub; j>0; j-- ) {
if ( a[j-1] > a[j] ) {
x=a[j-1]; a[j-1]=a[j]; a[j]=x;
k=j;
}
}
lb = k+1;
// проход сверху вниз
for (j=1; j<=ub; j++) {
if ( a[j-1] > a[j] ) {
x=a[j-1]; a[j-1]=a[j]; a[j]=x;
k=j;
}
}
ub = k-1;
} while ( lb < ub );
}
Насколько описанные изменения повлияли на эффективность метода ? Среднее количество сравнений, хоть и уменьшилось, но остается O(n2), в то время как число обменов не поменялось вообще никак. Среднее(оно же худшее) количество операций остается квадратичным, количество излишних двойных проверок сократилось.
Дополнительная память, очевидно, не требуется. Поведение усовершенствованного (но не начального) метода довольно естественное, почти отсортированный массив будет отсортирован намного быстрее случайного. Сортировка пузырьком устойчива, однако шейкер-сортировка утрачивает это качество.
На практике метод пузырька, даже с улучшениями, работает, увы, слишком медленно. А потому - почти не применяется.
2.3 Описание схемы алгоритма
Алгоритмы сортировки очень сильно зависят от структуры данных.. В данной работе рассматривается сортировка массивов. Тип данных «массив» удобен тем, что хранится во внутренней памяти и имеет случайный доступ к элементам, то есть более быстрый, чем у последовательности. Поэтому массивы целесообразно использовать для хранения небольших, часто используемых множеств
Из выше сказанного следует, что в процессе работы потребуются следующие переменные:
n – количество элементов массива;
A – сортируемый массив;
j – переменная;
x – i-й ключ (переносимый элемент);
r – номер последнего обмена при просмотре входной последовательности слева-направо.
l - номер последнего обмена при просмотре входной последовательности справа -
налево.
Все переменные целого типа.
Описание схемы алгоритма. Блок-схема данного алгоритма изображена на рис. 1 в Приложении.
Алгоритм работает следующим образом. Сначала вводятся исходные данные: длина массива и его элементы (блок 1, 2) , затем организуется цикл по всей длине массива, во время которого (блоки 3 -7) и проводится сравнение элементов а[j-1]>a[j] и их обмен при проходе справа-налево . Номер последнего обмена l запоминается. Далее организуется цикл, в котором проводится проверка условия а[j-1]>a[j] при проходе массива слева-направо (блоки 8 - 12).
2.4 Контрольный пример
Рассмотрим пример работы алгоритма сортировки Шейкер.
Задан массив A, состоящий из 8 элементов: 44, 55, 12, 42, 94, 18, 6, 67.
Шаг 1. l = 2, r = 8
Таблица 2
| l | 2 | 3 | 3 | 4 | 4 |
| r | 8 | 8 | 7 | 7 | 4 |
| Направление | ↑ | ↓ | ↑ | ↓ | ↑ |
| j=1 | 44 | 6 | 6 | 6 | 6 |
| j = 2 | 55 | 44 | 44 | 12 | 12 |
| j= 3 | 12 | 55 | 12 | 44 | 18 |
| j = 4 | 42 | 12 | 42 | 18 | 42 |
| j = 5 | 94 | 42 | 55 | 42 | 44 |
| j = 6 | 18 | 94 | 18 | 55 | 55 |
| j = 7 | 6 | 18 | 67 | 67 | 67 |
| j = 8 | 67 | 67 | 94 | 94 | 94 |
1) j = r =8
2) A[7]<A[8] , j = j -1 =7
3) A[6]>A[7], x=18, A[6]=6, A[7]=x=18 ; j=6
4) A[5]>A[6], A[5] =6, A[6] = 94
5) A[4]>A[5], A[4] =6, A[5] =42
6) A[3]>A[4], A[3] =6, A[4] =12
7) A[2]>A[3], A[2] =6, A[3] = 55
8) A[1]>A[2], A[1] =6, A[2] = 44
9) l=3.
Шаг 2. A[7]<A[8] , j = j -1 =7
1) A[1]>A[2]; j=6
2) A[2]>A[3], A[1] =, A[2] = 44, j= 4
3) A[3]>A[4], A[2] =6, A[3] =12, j=5
4) A[4]>A[5], A[3] =6, A[4] =12, j=6
5) A[5]>A[6], j =7
6) A[6]>A[7], A[5] =6, A[6] = 18 , j=8
7) r =7.
Шаг 3.
1) A[7]>А[8] , j = j -1 =7
2) A[6]>A[7], x=18, A[6]=6, A[7]=x=18 ; j=6
3) A[5]>A[6], A[5] =6, A[6] = 94; j=5
4) A[4]>A[5], A[4] =6, A[5] =42; j=4
5) A[3]>A[4], A[3] =6, A[4] =12; j=3
6) A[2]>A[3], A[2] =6, A[3] = 55; j=2
7) A[1]>A[2], A[1] =6, A[2] = 44; j=1
8) l=3.
Шаг 4.
1) A[1]>A[2], x=18, A[6]=6, A[7]=x=18 ; j=6
2) A[2]>A[3], A[1] =, A[2] = 94, j= 4
3) A[3]>A[4], A[2] =6, A[3] =42, j=5
4) A[4]>A[5], A[3] =6, A[4] =12, j=6
5) A[5]>A[6], j =7
6) A[6]>A[7], A[5] =6, A[6] = 44 , j=8 ,
7) r =7. → конец алгоритма.
Таким образом, мы получили исходный массив, отсортированный методом Шейкер:
6, 12, 18, 42, 44, 55, 67, 94.
3 АЛГОРИТМ ПОКРЫТИЯ: ПОСТРОЕНИЕ ОДНОГО КРАТЧАЙШЕГО ПОКРЫТИЯ
3.1 Математическое описание задачи и методов её решения
Пусть ![]() -опорное
множество. Имеется множество
-опорное
множество. Имеется множество
подмножеств![]() множества B (
множества B (![]() ). Каждому подмножеству
). Каждому подмножеству![]() сопоставлено
число
сопоставлено
число ![]() ,
называемой ценой. Множество
,
называемой ценой. Множество ![]() называется решением задачи о
покрытии, или просто покрытием, если выполняется условие
называется решением задачи о
покрытии, или просто покрытием, если выполняется условие ![]() , при этом цена
, при этом цена ![]() . Термин
«покрытие» означает, что совокупность множеств
. Термин
«покрытие» означает, что совокупность множеств ![]() содержит все элементы множества В,
т.е. «покрывает» множество B
содержит все элементы множества В,
т.е. «покрывает» множество B
Безизбыточным называется покрытие, если при удалении из него хотя бы одного элемента оно перестает быть покрытием. Иначе - покрытие избыточно.
Покрытие Р
называется минимальным, если его цене ![]() - наименьшая среди всех покрытий
данной задачи.
- наименьшая среди всех покрытий
данной задачи.
Покрытие Р называется кратчайшим, если l - наименьшее среди всех покрытий данной задачи.
Удобным и наглядным
представлением исходных данных и их преобразований в задаче о покрытии является
таблица покрытий. Таблица покрытий - это матрица Т отношения принадлежности
элементов множеств ![]() опорному множеству В. Столбцы
матрицы сопоставлены элементам множества В, строки - элементам множества
опорному множеству В. Столбцы
матрицы сопоставлены элементам множества В, строки - элементам множества
А: 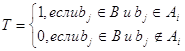
Нули в матрице T не проставляются.
Имеются следующие варианты формулировки задачи о покрытии:
1. Требуется найти все покрытия. Для решения задачи необходимо выполнить полный перебор всех подмножеств множества А.
2. Требуется найти только безызбыточные покрытия. Не существует простого и эффективного алгоритма, не требующего построения всех избыточных покрытий: хорошо, если уменьшается их количество. (Используется граничный перебор либо разложение по столбцу в ТП).
Требуется найти одно безизбыточное покрытие. Решение задачи основано на сокращении таблицы.
Задачи о покрытии могут быть решены точно (при небольшой размерности) либо приближенно (см. [2] ).
Для нахождения точного решения используются такие алгоритмы.
1) Алгоритм полного перебора. (Основан на методе упорядочения перебора подмножеств множества А).
2) Алгоритм граничного перебора по вогнутому множеству. (Основан на одноименном методе сокращения перебора).
3) Алгоритм разложения по столбцу таблицы покрытия. Основан на методе сокращения перебора, который состоит в рассмотрении только тех строк таблицы покрытия, в которых имеется "1" в выбранном для разложения столбце.
4) Алгоритм сокращения таблицы покрытия. Основан на методе построения циклического остатка таблицы покрытия, для которого далее покрытие строится методами граничного перебора либо разложения по столбцу.
Приближенное решение задачи о покрытии основано на следующем соображении. Если даже сокращенный перебор приводит к очень трудоемкому процессу решения, то для получения ответа приходится отказываться от гарантий построения оптимального решения (минимального либо кратчайшего); однако целесообразно получить не самый худший результат - хотя бы безызбыточное покрытие, удовлетворяющее необходимому условию. При этом в ущерб качеству можно значительно упростить процесс решения.
Для случая построения одного кратчайшего покрытия используется алгоритм построения циклического остатка таблицы покрытий и множества ядерных строк.
3.2 Словесное описание алгоритма и его работы
0) Считаем исходную таблицу покрытий текущей, а множество ядерных строк – пустым.
1) Находим ядерные строки, запоминаем множество ядерных строк. Текущую таблицу покрытий сокращаем, вычеркивая ядерные строки и все столбцы, покрытые ими.
2) Вычеркиваем антиядерные строки.
3) Вычеркиваем поглощающие столбцы.
4) Вычеркиваем поглощаемые строки.
5) Если в результате выполнения пунктов с 1 по 4 текущая таблица покрытий изменилась, снова выполняем пункт 1, иначе преобразование заканчиваем.
Поэтому алгоритм работы следующий:
1) ввод числа строк и столбцов таблицы покрытия;
2) ввод таблицы покрытия ;
3) поиск ядерных строк. Если их нет, то п.4. Иначе, запоминаем эти ядерные строки. Ищем столбцы, покрытые ядерными строками. Вычеркиваем все ядерные строки и столбцы, покрытые ими.
4) вычеркивание антиядерных строк. Переход в п.5.
6) вычеркивание поглощающих столбцов.
7) вычеркивание поглощаемых строк.
8) если в результате преобразований таблица покрытий изменилась, выполняем пункт 3. Иначе - вывод множества покрытия, конец алгоритма.
3.3 Выбор структур данных
Из анализа задачи и ее данных видно, что алгоритм должен работать с таблицей покрытия и с некоторыми переменными, которые представлены ниже (все переменные целого типа):
m – количество строк таблицы покрытия;
n – количество столбцов таблицы покрытия;
i, j – переменные цикла по строкам и столбцам соответственно;
Sprev – предыдущая сумма столбца либо строки;
Scurr – текущая сумма столбца либо строки.
Таблица покрытия — это двумерная матрица. Ее целесообразно представить в виде двумерного массива A(m, n).
P - одномерный массив для хранения номеров строк, покрывающих матрицу. Для хранения номеров выбран массив, поскольку количество строк, хотя и неизвестно заранее, ограничено количеством строк матрицы покрытия (m).
3.4 Описание схемы алгоритма
Блок-схема данного алгоритма изображена на рис. 3 в Приложении.
Сначала вводятся исходные данные: размерность таблицы m и n и сама таблица покрытия (блок 1). Далее происходит поиск пустого столбца (блок 2): это целесообразно, поскольку, если хотя бы один столбец не покрыт, то и не существует покрытия данной таблицы, и, следовательно, конец алгоритма. Далее, если не найдено пустого столбца (проверка в блоке 3), - поиск ядерных строк (блок 4), после столбцов, покрытых ими (блок 5). После этого вычеркиваются все столбцы и строки, найденные в блоках 4,5 (блок 6).Вычеркиваются антиядерные строки (блок 7). Вычеркиваются поглощающие столбцы (блок 8) . Вычеркиваются поглощаемые строки (блок 9). Если в результате выполнения блоков 6-9 текущая таблица покрытий изменилась, то выполняется блок 4; иначе следует вывод найденного кратчайшего покрытия в виде номеров строк, покрывающих таблицу. Затем конец алгоритма.
3.5 Подпрограммы основного алгоритма
Функция MOJNO_LI(A) ведет поиск пустых столбцов, то есть не покрываемых ни одной строкой. Блок-схема этой функции представлена на рис. 3.1 Приложения. Организуется цикл по всем столбцам (блоки 1-6). В каждом столбце идет счет нулей (счетчик l инициализируется в каждом проходе - блок 2; счет ведется в блоке 5), то есть если встречается хотя бы одна единица (проверка в блоке 3), то происходит переход в следующий столбец. Алгоритм работает до тех пор, пока не будет достигнут конец таблицы (то есть конец цикла по j, блок6) либо пока не будет сосчитано m нулей в одном столбце (проверка условия в блоке 4), то есть l=m. Функция возвращает 0, если найдено m нулей, и 1, если достигнут конец таблицы.
Функция YAD-LINE(A) ведет поиск ядерных строк.. В блоке 1 S инициализируется значением 0. Далее организуется цикл по всем столбцам (блок 2). Обнуляем текущую сумму (блок 4) и считаем сумму в j-м столбце (цикл в блоках 5-7 и собственно суммирование элементов в блоке 6). Далее сравниваем полученную сумму S с 1 (блок 8). Если текущая сумма равна 1, запоминаем её и номеру этого столбца присваиваем 0 (блок 9 . Таким образом, по окончании цикла по j в переменной yad_line(A) будет хранится массив ядерных строк. Блок-схема данного алгоритма изображена на рис. 3.2 в Приложении.
Функция ANTI_LINE ведет поиск антиядерных строк. Переменной S2 присваивается значение 0. Организовывается цикл по строкам. Ищется сумма каждой строки и если она равна 0, то строка вычеркивается. Если нет, то переходим к следующей строке. Блок-схема данного алгоритма изображена на рис. 3.3 в Приложении.
Процедура ERASE(A) реализует вычеркивание столбцов, покрытых ядерными строками. Аналогично данная процедура работает и для самих ядерных строк, и для антиядерных строк, поглощающих столбцов, поглощаемых строк. Чтобы данный столбец (строку) «вычеркнуть», обходимо поставить 1 на его (ее) пересечении с нулевой строкой (столбцом). Блок-схема данного алгоритма изображена на рис. 3.4 в Приложении.
Процедура VIVOD(P) реализует вывод полученного множества строк из массива P. Для этого организуется цикл по элементам массива Р (блоки 1-4), в котором проверяется отмечен ли номер строки i единицей (блок 2). Если да, то выводится номер строки i (блок 3). Блок-схема данного алгоритма изображена на рис. 3.5 в Приложении.
3.6 Пример работы алгоритма
Пусть задана таблица покрытий (см. Таб. 3). Рассмотрим пример работы алгоритма.
|
| B | B1 | B2 | B3 | B4 | B5 | B6 |
| А1 | 1 | 1 | 1 | |||
| А2 | 1 | 1 | 1 | |||
| A3 | 1 | 1 | 1 | |||
| А4 | 1 | 1 | 1 |
2. Множество антиядерных строк пустое .
3. Вычеркиваем столбцы В1, В3, В5, В6 как поглощающие
4. Вычеркиваем строку А2 как поглощенную.
Теперь таблица покрытий будет иметь вид
(см. Таб .4)
Таб. 4.
| В2 | В4 | |
| А1 | ||
| А3 | 1 | |
| А4 | 1 |
1. Множество ядерных строк Р={A3, A4}.
2. Множество антиядерных строк А={А1}.
3. Множество поглощающих столбцов пустое.
4. Множество поглощаемых строк пустое.
Теперь таблица покрытий примет вид (см. Таб 5)
| В2 | В4 | |
| А3 | 1 | |
| А4 | 1 |
Таким образом кратчайшее покрытие {A3, A4} Таб. 5.
4 АЛГОРИТМ НАХОЖДЕНИЯ КРАТЧАЙШЕГО ПУТИ В ГРАФЕ
4.1 Математическое описание задачи и методов её решения
Графом (G, X) называется совокупность двух конечных множеств: множества точек, которые называются вершинами (X = {Х1,...,Хn}), и множества связей в парах вершин, которые называются дугами, или ребрами ( (Хi, Хj) Î G ) в зависимости от наличия или отсутствия направленности связи.
Ребром называются две встречные дуги (Хi, Хj) и (Хj, Хi). На графе они изображаются одной линией без стрелки. Ребро, или дуга, конечные вершины которого совпадают, называется петлей.
Если на каждом ребре задается направление, то граф (G, Х) называется ориентированным. В противном случае граф называется неориентированным.
Две вершины, являющиеся конечными для некоторого ребра или некоторой дуги, называются смежными. Соответственно этот граф может быть представлен матрицей смежности либо матрицей инцидентности.
Матрицей инцидентности называется прямоугольная матрица с числом строк, равным числу вершин графа, и с числом столбцов, равным количеству ребер (дуг) графа. Элементы матрицы а задаются следующим образом: “1” ставится в случае если вершина vi, инцидентна ребру uj; “0” - в противном случае.
Вершина и ребро (дуга) называются инцидентными друг другу, если вершина является для этого ребра (дуги) концевой точкой.
Путь из начальной вершины хн к конечной вершине хк - последовательность дуг, начинающаяся в вершине хн Î Х, заканчивающаяся в вершине хк Î Х, и такая, что конец очередной дуги является началом следующей:
(хн, хi1)( хi1, хi2)( хi2… хik)( хik, xk) = (xн, хк).
Элементарный путь – путь, в котором вершины не повторяются.
Простой путь - путь, в котором дуги не повторяются.
Маршрут - последовательность ребер, составляющих, как и путь, цепочку.
Длина пути взвешенного графа определяется как сумма весов - его дуг. Если граф не взвешен, то можно считать веса дуг равными 1 .
Кратчайшим путем между выделенной парой вершин хн и хк называется путь, имеющий наименьшую длину среди всех возможных путей между этими вершинами.
Таким образом, нахождение кратчайшего пути – это поиск множества вершин, составляющих этот путь.
4.2 Словесное описание алгоритма и его работы
0. Инициализация кратчайших путей от вершины s до каждой вершины графа ∞, а все вершины 0, v=s.
1. Для каждой вершины u, смежной v, проверяем, отмечена ли она и какова длина пути между u и v. Если меньше, то запоминаем длину пути и текущую вершину u.
2. t= ∞, v=0. Для каждой вершины графа проверяем, отмечена ли она, и меньше ли путь от нее до s, чем t. Если так, то запоминаем её v=u, и её путь t=T[u] .
3. Если v=0, то пути нет, иначе если v=f, то путь найден и конец алгоритма.
4. Помечаем вершину v. Переход в п.1.
4.3 Выбор структур данных
Пусть p – количество вершин. Поскольку граф взвешен, то его представим в форме матрицы длин дуг:
С: array[1..p,1..p].
Используются следующие переменные и массивы:
s, f – вершины, между которыми следует найти кратчайший путь;
u, v – переменные циклов по вершинам;
T: array[1..p] of real – вектор, если вершина v лежит на кратчайшем пути от s к t, то T[v] – длина кратчайшего пути от s к v;
H: array[1..p] of 0..p – вектор, H[v] – вершина, непосредственно предшествующая v на кратчайшем пути;
X: array[1..p] of 0..1 – вектор меток вершин.
4.4 Описание схемы алгоритма
Блок-схема данного алгоритма изображена на рис. 4 в Приложении.
В блоке 1 происходит ввод графа в форме матрицы длин дуг, а также номеров вершин s и f. Далее организуется цикл по вершинам графа (блок 2). В нем инициализируются массив кратчайших путей и массив меток (блок 3): поскольку пути не известны, то они инициализируются бесконечностью, а метки – нулем. Далее отмечается вершина s, кратчайший путь от не до неё же самой равен 0, и ей никто не предшествует; текущей вершиной v становится s (блок 5). Далее организовывается цикл по смежным с текущей вершинам (блок 6). В блоке 7 происходит проверка смежны ли вершины. В блоке 8 сравнивается уже имеющийся путь с путем между u и v. Если текущий меньше, то он и номер вершины запоминаются (блок 9).
В остальных блоках происходит поиск конца кратчайшего пути. Изначально его длина не известна (равна ∞), и вершина, оканчивающая его также не известна (блок 11). В блоке 12 организуется цикл по всем неотмеченным вершинам. В блоке 13 производиться сравнение уже имеющегося кратчайшего пути t с текущим T[u]. Если текущий меньше, то запоминаем его и вершину (блок 14). Далее производится анализ полученного конца пути. Если v=0 (блок 16), то не была найдена вершина конца кратчайшего пути, и, следовательно, нет такого пути (блок 17). Если же v=f (блок 18), то есть конец совпадает с заданной вершиной, то между ними существует кратчайший путь (блок 19). В обоих случаях конец алгоритма.
Если же не достигнута заданная вершина f, то текущая вершина v помечается (блок 20) и переход в блок 6.
Алгоритм работает, пока не будет вершина t либо пока не станет ясно, что пути из s в f нет.
4.5 Контрольный пример решения задачи с помощью алгоритма поиска кратчайшего пути
Пусть задан граф, изображенный на рис. 1. Рассмотрим на этом примере работу алгоритма.
0. for v=1..p
T[v]=∞;
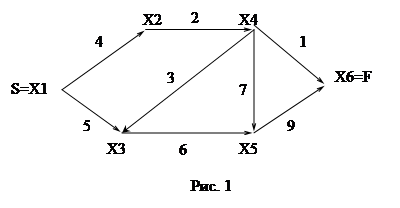 X[v]=0;
X[v]=0;
H[s]=0;
T[s]=0;
X[s]=1;
v=s;
1. X2 € G(1) →
X[2]=0&(∞>0+4) →
T[2]=T[1]+C[1,2]=4;
H[2]=1;
X3 G(1) →
X[3]=0&(∞>0+5) →
T[3]=T[1]+C[1,3]=5;
H[3]=1;
2. t=∞; v=0;
for u=1..p
X[2]=0&T[2]=4<∞ →
v=2; t=T[2]=4;
X[3]=0&T[3]=5!< ∞
3. v=2≠0;
v=2≠f=6;
4. X[2]=1 → п.1;
1. X4 € G(2) →
X[4]=0&(∞>0+2) →
T[4]=T[2]+C[2,4]=6;
H[4]=2;
2. t=∞; v=0;
for u=1..p
X[4]=0&T[4]=6<∞ →
v=4; t=T[4]=6;
3. v=4≠0;
v=4≠f=6;
4. X[4]=1 → п.1;
1. X3 € G(4) →
X[3]=0&(5!>6+3)
X5 G(4) →
X[5]=0&(∞>0+7) →
T[5]=T[4]+C[4,5]=13;
H[5]=4;
X6 G(4) →
X[6]=0&(∞>0+1) →
T[6]=T[4]+C[4,6]=7;
H[6]=4;
2. t=∞; v=0;
for u=1..p
X[3]=0&T[3]=5<∞ →
v=3; t=T[3]=5;
X[5]=0&T[5]=13!< 5
X[6]=0&T[6]=1<5 →
v=5; t=T[5]=7;
3. v=6≠0;
v=6=f=6; → конец алгоритма.
ЗАКЛЮЧЕНИЕ
В данной работе разработаны алгоритмы сортировки, поиска кратчайшего пути в графе и поиска покрытия, близкого к кратчайшему. Алгоритмы исполнены с нужной степенью детализации, необходимой для понимания их работы. Рассмотрены пути улучшения эффективности каждого алгоритма учитывая требования конкретной задачи.
Большое внимание уделено сравнению возможного использования нескольких структур данных, проведён анализ эффективности работы алгоритма в зависимости от используемой структуры.
Рассмотрена сложность каждого алгоритма, её зависимость от условий данной задачи, методы упрощения и облегчения понимания алгоритма.
ЛИТЕРАТУРА
1. Вирт Н. Алгоритмы и структуры данных. – С.-П.: Невский диалект, 2001. – 350 с.
2. Новиков Ф.А. Дискретная математика для программистов. – С.-П.: Питер, 2003.–292 с.
3. Шендрик Е.В. Конспект лекций по дисциплине «Теория алгоритмов». – Одесса, 2003.
© 2010 Интернет База Рефератов