
Рефераты по сексологии
Рефераты по информатике программированию
Рефераты по биологии
Рефераты по экономике
Рефераты по москвоведению
Рефераты по экологии
Краткое содержание произведений
Рефераты по физкультуре и спорту
Топики по английскому языку
Рефераты по математике
Рефераты по музыке
Остальные рефераты
Рефераты по авиации и космонавтике
Рефераты по административному праву
Рефераты по безопасности жизнедеятельности
Рефераты по арбитражному процессу
Рефераты по архитектуре
Рефераты по астрономии
Рефераты по банковскому делу
Рефераты по биржевому делу
Рефераты по ботанике и сельскому хозяйству
Рефераты по бухгалтерскому учету и аудиту
Рефераты по валютным отношениям
Рефераты по ветеринарии
Рефераты для военной кафедры
Рефераты по географии
Рефераты по геодезии
Рефераты по геологии
Рефераты по геополитике
Рефераты по государству и праву
Рефераты по гражданскому праву и процессу
Рефераты по делопроизводству
Рефераты по кредитованию
Рефераты по естествознанию
Рефераты по истории техники
Рефераты по журналистике
Рефераты по зоологии
Рефераты по инвестициям
Рефераты по информатике
Исторические личности
Рефераты по кибернетике
Рефераты по коммуникации и связи
Курсовая работа: Инфологическая модель базы данных "Тестирование"
Курсовая работа: Инфологическая модель базы данных "Тестирование"
содержание
Введение. 2
1. Анализ предметной области. 4
1.1. Описание предметной области. 4
1.2. Инфологическое моделирование. 5
2. Инфологическое проектирование. 10
2.1. Модель «сущность-связь». 10
2.2. Связи между сущностями. 12
Заключение. 15
Список литературы.. 16
Введение
Система тестирования знаний – программная система, призванная обеспечить проверку знаний учащихся. Во многих случаях разделяют использование таких систем для собственно контроля знаний и для самоконтроля (пробного тестирования).
Целью данной курсовой работы является систематизация, накопление и закрепление знаний о построении инфологической модели тестовой программы по электронному учебнику.
Процесс проектирования БД на основе принципов нормализации представляет собой последовательность переходов от неформального словесного описания информационной структуры предметной области к формализованному описанию объектов предметной области в терминах некоторой модели.
Инфологическая модель применяется на втором этапе проектирования БД, то есть после словесного описания предметной области. Процесс проектирования длительный и требует обсуждений с заказчиком и со специалистами в предметной области. Наконец, при разработке серьезных корпоративных информационных систем проект базы данных является тем фундаментом, на котором строится вся система в целом, и вопрос о возможном кредитовании часто решается экспертами банка на основании именно грамотно сделанного инфологического проекта БД. Следовательно, инфологическая модель должна включать такое формализованное описание предметной области, которое легко будет «читаться» не только специалистами по базам данных. И это описание должно быть настолько емким, чтобы можно было оценить глубину и корректность проработки проекта БД, и конечно, оно не должно быть привязано к конкретной СУБД. Выбор СУБД – это отдельная задача, для корректного ее решения необходимо иметь проект, который не привязан ни к какой конкретной СУБД.
Инфологическое проектирование прежде всего связано с попыткой представления семантики предметной области в модели БД.
В настоящее время практически во всех сферах человеческой деятельности используются базы данных. Данная инфологическая модель базы данных может применяться в различных учебных заведениях. Для обеспечения надежности системы управления данными необходимо выполнить следующие основные требования:
целостность и непротиворечивость данных,
достоверность данных,
простота управления данными,
безопасность доступа к данным.
1. Анализ предметной области
1.1. Описание предметной области
Современное состояние отечественной системы образования характеризуется достаточно высокой насыщенностью высших и других учебных заведений средствами вычислительной техники, что заставляет задуматься над эффективностью ее применения в учебном процессе. Одно из наиболее распространенных направлений - создание и эксплуатация автоматизированных систем контроля знаний (АСКЗ). В настоящее время известно множество практических реализаций систем автоматизированного тестирования как по отдельным дисциплинам (предметные тесты), так и универсальных систем оценивания знаний (т. н. “конструкторы тестов”), полностью или частично инвариантных к конкретным дисциплинам и допускающих их информационное наполнение преподавателями - организаторами тестирования.
Анализ эффективности автоматизированного тестирования в высших и других учебных заведениях показывает, что многие преподаватели настороженно и даже негативно относятся к подобным системам. Среди наиболее существенных недостатков современных подходов к автоматизированному тестированию, называемых в качестве причин такого отрицательного отношения, можно отметить:
необходимость формулирования вариантов ответов на тестовые задания по принципу “один абсолютно правильный” - “N абсолютно неправильных”. Это не дает возможности организовать полноценное тестирование по слабо формализованным дисциплинам, для которых характерна диалектичность знаний (дисциплины общественно-политического, гуманитарного, социально-экономического и т.п. циклов);
примитивность и негибкость процедур расчета итоговой оценки, сводимых либо к определению отношения количества правильных ответов к количеству заданных вопросов, либо к суммированию баллов, назначаемых за каждый правильный ответ;
невозможность автоматизации разнообразных методик контроля знаний, широко применяемых в педагогической практике (оценка широты либо глубины знаний, учет относительной важности отдельных тем или разделов изучаемой дисциплины, выбор сложности теста с учетом уровня подготовленности и самооценки тестируемого, стимуляция правильных ответов и т.п.);
значительная трудоемкость ручного формирования такого множества тестовых заданий и вариантов ответов на каждое из них, которое позволит исключить или минимизировать вероятность предъявления одного и того же задания различным тестируемым при параллельной проверке их знаний.
Особенно ярко указанные недостатки автоматизированного тестирования проявляются при контроле знаний по дисциплинам гуманитарного, социально-экономического и общественно-политического циклов. Степень формализации знаний по этим дисциплинам в силу диалектичности слишком низка, чтобы их наличие могло определяться по тому, насколько хорошо помнит экзаменуемый отдельные факты, точные определения или конкретные формулы и правила их применения.
1.2. Инфологическое моделирование
Исходя из необходимости повышения эффективности учебного процесса и из возможности применения современных информационных технологий наиболее перспективным и целесообразным представляется автоматизация процесса педагогического тестирования. Высокая степень формализации и унификации процедуры тестирования, возможность одновременного проведения тестирования на нескольких компьютерах, а также возможность организации дистанционного тестирования посредством локальной вычислительной сети либо через глобальную информационную сеть Интернет предопределили всеобщий интерес к подобному способу оценивания знаний.
Определенный интерес представляет выявление роли и значимости тестирования на различных этапах контроля и оценивания знаний, а также его применимость при изучении различных дисциплин. Не вызывает сомнений целесообразность применения традиционных АСКЗ при изучении дисциплин, ориентированных на усвоение обучаемыми конечного множества фактов либо однозначно трактуемых правил. Примером подобной ситуации можно считать экзамен на знание правил дорожного движения. Практически безальтернативным представляется применение таких АСКЗ при проведении массового одновременного государственного тестирования знаний выпускников средних школ, хотя руководители центров тестирования отмечают большое количество конфликтов, связанных с оцениванием знаний по дисциплинам языкового цикла, для которых характерна неоднозначность некоторых “истинных” ответов даже с точки наиболее опытных преподавателей-предметников. АСКЗ широко применяются для уменьшения трудоемкости текущего контроля знаний по естественно-научным и техническим дисциплинам (т. н. “срезы”), цель которого состоит в оперативной и массовой проверке остаточных знаний большого количества обучаемых в доэкзаменационный период.
Можно утверждать, что процедуры “классического” тестирования, основанные на парадигме один абсолютно правильный ответ - N абсолютно неправильных ответов” и выводе итоговой оценки из соотношения количества правильных ответов и заданных вопросов, неадекватны представлениям большинства преподавателей о процессе оценивания знаний. Для многих дисциплин, знания в которых носят принципиально нечеткий характер и не могут быть сведены к однозначным формулировкам (например, дисциплины гуманитарного или общественного циклов), они вообще оказываются неприменимыми.
Следовательно, АСКЗ будет признаваться конкретным преподавателем эффективным инструментом промежуточного или итогового контроля знаний только в том случае, если она будет: а) содержать информационную модель предметной области, релевантную предметным знаниям организатора тестирования в период проведения контроля; б) обладать возможностью учитывать неполные или не совсем точные ответы; в) содержать адаптивную и управляемую преподавателем процедуру выявления знаний, анализа их глубины и качества с последующей реконструкцией на этой основе информационной модели обучаемого; г) выводить итоговую оценку знаний обучаемого по результатам сопоставления эталонной модели, содержащейся в АСКЗ, с реконструированной моделью, построенной по ответам обучаемого.
Построение такой АСКЗ требует применения принципиально иных подходов к представлению и обработке знаний. Сформулируем основные принципы построения АСКЗ нового поколения, основанные на методах и моделях, развиваемых в рамках теории интеллектуальных вычислений и инженерии знаний. Эти принципы определяют концепцию интеллектуального тестирования, более адекватную представлениям преподавателя о требуемой организации процесса контроля и оценивания знаний и позволяющую реализовать неформализованные ранее педагогические приемы и методики:
Переход от задания истинности предлагаемых вариантов ответов в категориях двоичной логики (“правильно - неправильно”) к более общей и универсальной схеме оценивания ответов функциями предпочтения, определяемыми в категориях нечеткой логики. Заметим, что такой переход не отрицает и традиционный подход, поскольку в соответствии с современными представлениями двоичная логика может считаться частным (точнее, вырожденным) случаем нечеткой логики.
Переход от индивидуального организации теста к коллегиальной экспертной подготовке всех его этапов, что увеличит доверие конечных пользователей к АСКЗ и повысит валидность результатов тестирования.
Количественное определение сложности и важности каждого тестового задания по пропорциональной цифровой шкале, что даст возможность повысить объективность оценивания демонстрируемых знаний.
Разбиение множества тестовых заданий на тематические подмножества, элементы которых семантически коррелируют друг с другом, с обязательным ранжированием как тестовых заданий внутри каждого подмножества, так выделенных подмножеств между собой. Реализация этого принципа создаст объективную основу для формализации ряда применяемых в настоящее время “ручных” методик контроля знаний - таких, например, как оценивание широты или глубины знаний, тесты повышенной или пониженной сложности и т.п.
Переход от характерного для современных АСКЗ использования программно реализованных алгоритмов прямого тестирования (при котором выбор очередного задания практически не зависит от ответов тестируемого на предыдущие вопросы) к их модульному конструированию при подготовке теста, а также к построению алгоритмов адаптивного тестирования, обусловливающих выбор очередного i-го задания ответами обучаемого на предыдущих (i - 1) - м, (i - 2) - м,..., и т.д. шагах теста. Реализация этого принципа позволит формализовать широко применяемые в педагогической практике методики дополнительных, наводящих и уточняющих вопросов.
Построение, унифицированное описание и однотипная реализация в рамках одной и той же ИАСКЗ набора алгоритмов тестирования, реализующих различные методики контроля знаний, и предоставление организатору тестирования возможности выбирать в конкретной ситуации те из них, применение которых либо предписывается нормативными документами, либо определяется его собственными предпочтениями.
Создание инструментария для построения, настройки и модификации различных шкал итогового оценивания знаний, включая как возможность изменения количества и ширины оценочных интервалов, так и определение и варьирование зон неопределенности оценок. Это дает возможность организовать параметрический анализ валидности промежуточных и итоговых результатов тестирования.
Автоматизация наиболее трудоемкого этапа подготовительной стадии тестирования, связанного с формированием множества тестовых заданий и вариантов ответов на них. Базис этой процедуры могут составить, в частности, формализованная модель знаний по изучаемой дисциплине, представленная в виде структурированной семантической сети, и известные из инженерии знаний фрейм-технологии.
2. Инфологическое проектирование
2.1. Модель «сущность-связь»
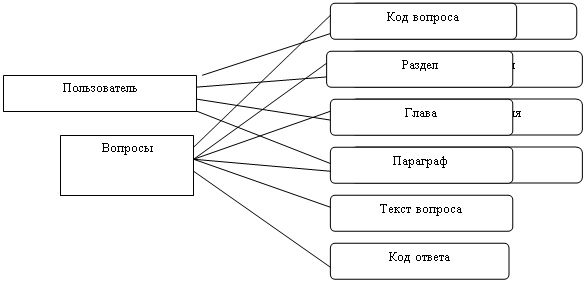
Инфологическая модель применяется после словесного описания предметной области. На основании анализа предметной области выделим следующие сущности модели «сущность-связь» («Entity Relationship» - ER-модели).
| Вопросы |
| Код вопроса |
| Раздел |
| Глава |
| Параграф |
| Текст вопроса |
| Код ответа |
| Пользователь |
| Код пользователь |
| Тип пользователя |
| Права пользователя |
| Пароль |
| Ответы |
| Код ответа |
| Код вопроса |
| Балл |
Как любая модель, модель «сущность-связь» имеет несколько базовых понятий, которые образуют исходные кирпичики, из которых строятся уже более сложные объекты по заранее определенным правилам.
Эта модель в наибольшей степени согласуется с концепцией объектно-ориентированного проектирования, которая в настоящий момент, несомненно, является базовой для разработки сложных программных систем, поэтому многие понятия вам могут показаться знакомыми, и если это действительно так, то тем проще вам будет освоить технологию проектирования баз данных, основанную на ER-модели.
Сущность, с помощью которой моделируется класс однотипных объектов. Сущность имеет имя, уникальное в пределах моделируемой системы. Так как сущность соответствует некоторому классу однотипных объектов, то предполагается, что в системе существует множество экземпляров данной сущности. Объект, которому соответствует понятие сущности, имеет свой набор атрибутов – характеристик, определяющих свойства данного представителя класса. При этом набор атрибутов должен быть таким, чтобы можно было различать конкретные экземпляры сущности.
Рассмотрим сущности проектируемой предметной области.



 2.2. Связи между сущностями
2.2. Связи между сущностями
Связи делятся на три типа по множественности: один-ко-одному (1: 1), один-ко-многим (1: М), многие-ко-многим (М: М).
Связь один-ко-одному означает, что экземпляр одной сущности связан только с одним экземпляром другой сущности.
Связь один-ко-многим (1: М) означает, что один экземпляр сущности, расположенный слева по связи, может быть связан с несколькими экземплярами сущности, расположенными справа по связи.
Связь «многие-ко-многим (М: М) означает, что несколько экземпляров первой сущности могут быть связаны с несколькими экземплярами второй сущности, и наоборот. Между двумя сущностями может быть задано сколько угодно связей с разными смысловыми нагрузками.
 |
Определим связи между выявленными сущностями.
1 М М 1
В разных нотациях мощность связи изображается по-разному. Между двумя сущностями может быть задано сколько угодно связей с разными смысловыми нагрузками. Связь любого из этих типов может быть обязательной, если в данной связи должен участвовать каждый экземпляр сущности, необязательной – если не каждый экземпляр сущности должен участвовать в данной связи. При этом связь может быть обязательной с одной стороны и необязательной с другой стороны. Обязательность связи тоже по-разному обозначается в разных нотациях. Мы снова используем нотацию POWER DESIGNER. Здесь необязательность связи обозначается пустым кружочком на конце связи, а обязательность перпендикулярной линией, перечеркивающей связь. И эта нотация имеет простую интерпретацию. Кружочек означает, что ни один экземпляр не может участвовать в этой связи. А перпендикуляр интерпретируется как то, что, по крайней мере, один экземпляр сущности участвует в этой связи.
Кроме того, в ER-модели допускается принцип категоризации сущностей. Это значит, что, как в объектно-ориентированных языках программирования, вводится понятие подтипа сущности, то есть сущность может быть представлена в виде двух или более своих подтипов – сущностей, каждая из которых может иметь общие атрибуты и отношения и/или атрибуты и отношения, которые определяются однажды на верхнем уровне и наследуются на нижнем уровне. Все подтипы одной сущности рассматриваются как взаимоисключающие, и при разделении сущности на подтипы она должна быть представлена в виде полного набора взаимоисключающих подтипов. Если на уровне анализа не удается выявить полный перечень подтипов, то вводится специальный подтип, называемый условно «Прочие», который в дальнейшем может быть уточнен. В реальных системах бывает достаточно ввести подтипизацию на двух-трех уровнях.
Сущность имеет имя, уникальное в пределах модели. При этом имя сущности – это имя типа, а не конкретного экземпляра.
Сущности подразделяются на сильные и слабые. Сущность является слабой, если ее существование зависит от другой сущности – сильной по отношению к ней.
Сущность может быть расщеплена на два или более взаимоисключающих подтипов, каждый из которых включает общие атрибуты и/или связи. Эти общие атрибуты и/или связи явно определяются один раз на более высоком уровне. В подтипах могут определяться собственные атрибуты и/или связи. В принципе выделение подтипов может продолжаться на более низких уровнях, но в большинстве случаев оказывается достаточно двух-трех уровней.
Сущность, на основе которой определяются подтипы, называется супертипом. Подтипы должны образовывать полное множество, то есть любой экземпляр супертипа должен относиться к некоторому подтипу. Иногда для полноты множества надо определять дополнительный подтип, например, «Прочие».
Заключение
На мой взгляд, нелегко правильно воспринять и оценить тех советов и рекомендаций по построению хорошей инфологической модели, которые десятилетиями формировались крупнейшими специалистами в области обработки данных. В идеале необходимо, чтобы предварительно был реализован хотя бы один проект информационной системы, предложенный его реальным пользователям.
Любые теоретические рекомендации воспринимаются всерьез лишь после нескольких безрезультатных попыток оживления неудачно спроектированных систем. (Хотя есть и такие проектировщики, которые продолжают верить, что смогут реанимировать умирающий проект с помощью изменения программ, а не инфологической модели базы данных)
Для определения перечня и структуры хранимых данных надо собрать информацию о реальных и потенциальных приложениях, а также о пользователях базы данных, а при построении инфологической модели следует заботиться лишь о надежности хранения этих данных, напрочь забывая о приложениях и пользователях, для которых создается база данных.
Целесообразно:
четко разграничивать такие понятия как запрос на данные и ведение данных (ввод, изменение и удаление);
помнить, что, как правило, база данных является информационной основой не одного, а нескольких приложений, часть их которых появится в будущем;
плохой проект базы данных не может быть исправлен с помощью любых (даже самых изощренных) приложений.
Список литературы
1. Атре Ш. Структурный подход к организации баз данных. – М.: Финансы и статистика, 1983. – 320 с.
2. Бойко В.В., Савинков В.М. Проектирование баз данных информационных систем. М.: Финансы и статистика, 1989. – 351 с.
3. Дейт К. Руководство по реляционной СУБД DB2. – М.: Финансы и статистика, 1988. – 320 с.
4. Джексон Г. Проектирование реляционных баз данных для использования с микроЭВМ. - М.: Мир, 1991. – 252 с.
5. Кириллов В.В. Структуризованный язык запросов (SQL). – СПб.: ИТМО, 1994. 80 с.
6. Мартин Дж. Планирование развития автоматизированных систем. – М.: Финансы и статистика, 1984. – 196 с.
7. Мейер М. Теория реляционных баз данных. – М.: Мир, 1987. – 608 с.
8. Тиори Т., Фрай Дж. Проектирование структур баз данных. В 2 кн., – М.: Мир, 1985. Кн.1. – 287 с.: Кн.2. – 320 с.
9. Ульман Дж. Базы данных на Паскале. – М.: Машиностроение, 1990. – 386 с.
10. Хаббард Дж. Автоматизированное проектирование баз данных. – М.: Мир, 1984. – 294 с.
11. Цикритизис Д., Лоховски Ф. Модели данных. – М.: Финансы и статистика, 1985. – 344 с.
© 2010 Интернет База Рефератов