
Рефераты по сексологии
Рефераты по информатике программированию
Рефераты по биологии
Рефераты по экономике
Рефераты по москвоведению
Рефераты по экологии
Краткое содержание произведений
Рефераты по физкультуре и спорту
Топики по английскому языку
Рефераты по математике
Рефераты по музыке
Остальные рефераты
Рефераты по авиации и космонавтике
Рефераты по административному праву
Рефераты по безопасности жизнедеятельности
Рефераты по арбитражному процессу
Рефераты по архитектуре
Рефераты по астрономии
Рефераты по банковскому делу
Рефераты по биржевому делу
Рефераты по ботанике и сельскому хозяйству
Рефераты по бухгалтерскому учету и аудиту
Рефераты по валютным отношениям
Рефераты по ветеринарии
Рефераты для военной кафедры
Рефераты по географии
Рефераты по геодезии
Рефераты по геологии
Рефераты по геополитике
Рефераты по государству и праву
Рефераты по гражданскому праву и процессу
Рефераты по делопроизводству
Рефераты по кредитованию
Рефераты по естествознанию
Рефераты по истории техники
Рефераты по журналистике
Рефераты по зоологии
Рефераты по инвестициям
Рефераты по информатике
Исторические личности
Рефераты по кибернетике
Рефераты по коммуникации и связи
Научная работа: Построение маршрута при групповой рассылке сетевых пакетов данных
Научная работа: Построение маршрута при групповой рассылке сетевых пакетов данных
МИНИСТЕРСТВО ОБРАЗОВАНИЯ И НАУКИ УКРАИНЫ
Государственный университет информатики и искусственного интеллекта
Д080403.1.01.03/056.НР
Кафедра программного обеспечения
интеллектуальных систем
ОТЧЕТ О НИРС
Тема: «Построение маршрута при групповой рассылке сетевых пакетов данных»
Руководитель:
___________ доц. А.И. Ольшевский
(дата, подпись)
Нормоконтроль:
___________ асс. Е.В. Курило
(дата, подпись)
Разработал:
___________ ст.гр. ПО-03м Л.В. Карпенко
(дата, подпись)
2008
![]() РЕФЕРАТ
РЕФЕРАТ
Отчет о НИРС: 39 с., 3 таблицы, 14 рисунков, 6 источников.
Объектом исследования является алгоритм построения оптимального маршрута при групповой рассылке данных.
Цель разработка алгоритма построения маршрута для дальнейшего теоретического и практического его применения, а также написание программного продукта как реализации алгоритма.
Предложено разбиение алгоритма на два этапа, для которых рассмотрены соответствующие теоретические исследования, проведен анализ предлагаемых подходов.
В итоге были выбраны методы решения для каждого из этапов алгоритма и представлены схематические результаты построения.
Также были разработаны структуры для хранения и обработки данных алгоритма, предложены методы настройки параметров алгоритма.
СЕТЬ, РЕГИОНАЛЬНЫЕ ЦЕНТРЫ, ДЕРЕВЬЯ ШТЕЙНЕРА, ГЕНЕТИЧЕСКИЕ АЛГОРИТМЫ, СТРУКТУРЫ ДАННЫХ
ВВЕДЕНИЕ
В настоящее время наиболее эффективным и перспективным методом обучения является дистанционное обучение (ДО). Широкое распространение персональных компьютеров и активное развитие глобальных сетей (ГС) вывело этот процесс на принципиально новый уровень. Теперь получить образование можно независимо от места жительства и физических возможностей. Дистанционное образование позволяет получить диплом любого ВУЗа, любой специальности.
Но для качественного обучения требуется как можно более плотное взаимодействие студента с преподавателями. Необходимо передавать огромные объемы данных: задания, методические указания, выполненные работы.
В связи с этим одним из актуальных вопросов ДО стал поиск оптимального способа пересылки данных. Разрабатываются более дешевые и быстрые пути передачи информации.
ГС не являются стабильными, т.е. изменяется их структура, количество участников, стоимость услуг. Поэтому разработать идеальный маршрут невозможно.
Для постоянного пересчета путей ищут алгоритмы их построения. Одним из способов построения является использование деревьев Штейнера (ДШ). Эта задача имеет множество способов решения. В данной работе предлагается решать ее с помощью генетических алгоритмов (ГА).
Объектом исследования данной работы является алгоритм построения оптимального маршрута при групповой рассылке данных по сети. Основным критерием оптимальности является стоимость рассылки по построенному маршруту.
Для этого алгоритм должен учитывать длину соединений, стоимость пересылки по каждой из ветвей, общую стоимость пересылки по всем требуемым направлениям.
Для оценки работы алгоритма, наглядного представления результатов и их практического применения предполагается написать программный продукт (ПП). Предлагаемые особенности реализации и настройки этого ПП будут рассмотрены в этом отчете.
1 ОБЩАЯ ПОСТАНОВКА ЗАДАЧИ
По своей сути сеть дистанционного обучения (СДО) представляет собой дерево с набором вершин и ребер. Построение оптимального маршрута для дерева является достаточно старой задачей, для решения которой существует множество алгоритмов. Но не следует забывать о специфике задачи: в реальной ситуации весьма существенными факторами становятся стоимость рассылки, протяженность и сложность маршрута, скорость передачи данных. Поэтому предлагается модифицировать существующие алгоритмы с учетом этих факторов.
Разрабатываемый алгоритм делится на две части. На первом этапе построения сеть разбивается на подсети по числу региональных учебных филиалов. Это позволит снизить нагрузку по рассылке с центрального учебного центра. Каждая подсеть объединятся вокруг своего регионального центра (РЦ). Этот процесс сродни задаче разделения объектов на классы. Абонент приписывается к определенному центру на основании экономической целесообразности (стоимости его связи с данным центром).
Для разбиения множества всех абонентов на подмножества не существует точных методов, но для конкретной задачи можно выработать специальный алгоритм на основе известных методов. При этом следует рассмотреть разные виды структур сетей (радиальные, древовидные), чтобы иметь возможность наиболее эффективно их комбинировать.
Второй этап алгоритма – это построение деревьев внутри каждой подсети. В качестве критериев обычно рассматривается время передачи единицы данных по каналу, расстояние или денежный эквивалент данного соединения, пропускная способность канала и др.
Для решения такой задачи существует множество чисто математических методов, но при достаточно большом числе абонентов они не всегда удобны. В реальных разветвленных сетях часто используют эвристические методы.
Но, так же как и для предыдущего этапа, универсального решения не существует. Поэтому следует рассмотреть различные методы построения деревьев и возможности их комбинирования.
Задача разработки программного продукта состоит в том, чтобы он предоставлял необходимые возможности. А именно: возможность создания и редактирования сети; визуализация схемы построенного маршрута; вывод результатов расчетов для пересылки по построенному маршруту; возможность настраивать параметры алгоритма для получения наиболее оптимального результата и др.
Сложность генетических алгоритмов при построении деревьев состоит в кодировке исходных данных. Для требуемых вычислений и представления структуры сети на экране используются различные типы данных. Поэтому предполагается совмещать вещественное представление хромосом с традиционным.
2 МЕТОДЫ СИНТЕЗА СТРУКТУРЫ СЕТИ 2.1 Размещение центров и синтез абонентских СДО в классе
радиальных структур
Точные методы для общей задачи структурного синтеза сетей неизвестны, однако для задач специального вида можно разработать алгоритмы, использующие, например, метод ветвей и границ.
2.1.1 Метод ветвей и границЭтот метод является универсальным методом дискретной оптимизации и включает следующие процедуры: задание исходного множества вариантов, выбор наиболее перспективного множества для разбиения, ветвление множества на подмножества, определение нижней границы значения критерия на каждом из образовавшихся подмножеств, поиск допустимого решения в каждом из образованных подмножеств, проверку признака оптимальности. Основная трудность метода ветвей и границ состоит в выборе способа ветвления (разбиения) множества на подмножества и задании эффективной нижней границы критерия, позволяющей отбрасывать большое число бесперспективных вариантов.
Рассмотрим реализацию метода ветвей и границ для задачи размещения центров и синтеза радиальной структуры сети. Метод состоит из конечного числа однотипных итераций, на каждой из которых строится совокупность подмножеств вариантов:
![]()
где к номер итерации.
Каждое
из подмножеств ![]() характеризуется следующими
множествами:
характеризуется следующими
множествами: ![]() — множество пунктов, где РЦ уже построены;
— множество пунктов, где РЦ уже построены; ![]() множество пунктов, где еще можно строить РЦ;
множество пунктов, где еще можно строить РЦ; ![]() — множество пунктов, где
наложен запрет на строительство РЦ, при этом
— множество пунктов, где
наложен запрет на строительство РЦ, при этом
![]()
где Y — исходное множество пунктов, в которых допускается строительство РЦ, Y Є Х.
Обозначим
через Xyi множество
абонентов, подключенных к РЦ уi (у Є Р) по
критерию минимума затрат на связь, т. е. х Є Хуi, если ![]() . Каждое из множеств
. Каждое из множеств ![]() характеризуется
величиной нижней границы критерия
характеризуется
величиной нижней границы критерия ![]() для всех структур (решений),
определяемых данным множеством. Величина ξ задается следующим
соотношением:
для всех структур (решений),
определяемых данным множеством. Величина ξ задается следующим
соотношением:
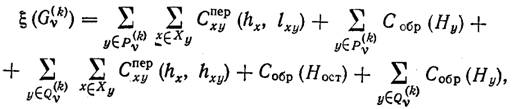
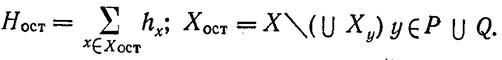
где .
Допустим,
что каким-то приближенным методом (например, R-структур) удается построить структуру Х0 на множестве ![]() . При этом в решение должны
войти все РЦ уi Є
. При этом в решение должны
войти все РЦ уi Є ![]() и не должно быть ни одного РЦ уi Є
и не должно быть ни одного РЦ уi Є ![]() .
.
Обозначим
величину критерия для структуры Х0 через W(Х0). Справедлив следующий признак
оптимальности: если W(Х0) = ![]() ,
то вершина дерева решений
,
то вершина дерева решений ![]() является конечной и
дальнейшему разбиению не подлежит; если W(Х0) ≤ min
является конечной и
дальнейшему разбиению не подлежит; если W(Х0) ≤ min ![]() для всех висячих вершин
для всех висячих вершин ![]() построенных на k-й итерации, то Х0 — искомое
оптимальное решение (структура). Предположим, что уже проведено k итераций
и еще не найдено оптимальное решение. Опишем произвольную (k + 1)-ю итерацию:
построенных на k-й итерации, то Х0 — искомое
оптимальное решение (структура). Предположим, что уже проведено k итераций
и еще не найдено оптимальное решение. Опишем произвольную (k + 1)-ю итерацию:
1.Среди всех множеств ![]() , построенных в результате k-й итерации, выбираем наиболее
перспективное множество
, построенных в результате k-й итерации, выбираем наиболее
перспективное множество ![]() , т.
е. такое, что
, т.
е. такое, что
![]() .
.
2.Ветвление. Выбираем
некоторый РЦ yr Є ![]() и разбиваем
и разбиваем ![]() на два подмножества
на два подмножества ![]() и
и
![]() так, что на подмножестве
так, что на подмножестве ![]() РЦ
yr, переводится в разряд
действующих, а на подмножестве
РЦ
yr, переводится в разряд
действующих, а на подмножестве ![]() накладывается запрет на строительство РЦ в пункте уr. Таким
образом,
накладывается запрет на строительство РЦ в пункте уr. Таким
образом,
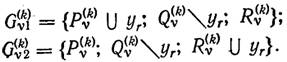
Будем
выбирать уr так,
чтобы подмножество ![]() с
наибольшей вероятностью содержало искомое решение, а
с
наибольшей вероятностью содержало искомое решение, а ![]() не содержало. Тогда
не содержало. Тогда
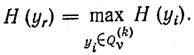
3.Вычисление
оценок ![]() и
и
![]() . В частности, для
множества
. В частности, для
множества ![]() можно
использовать следующую рекуррентную формулу:
можно
использовать следующую рекуррентную формулу:
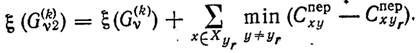
4.На
каждом из подмножеств ![]() и
и ![]() находим
допустимое решение, которое обозначим
находим
допустимое решение, которое обозначим ![]() и
и ![]() соответственно.
соответственно.
5.
Проверка признака оптимальности. Пусть ![]() ≤
≤ ![]() . Если
. Если
![]()
где
{![]() }
множество висячих вершин на k-й итерации, то
}
множество висячих вершин на k-й итерации, то ![]() — искомое решение и конец
работы алгоритма. В противном случае переходим на (k+2)-ю
итерацию, переобозначив для всех висячих вершин
— искомое решение и конец
работы алгоритма. В противном случае переходим на (k+2)-ю
итерацию, переобозначив для всех висячих вершин
![]()
Весь процесс решения реализуется в виде некоторого дерева вариантов.
Как показывают проведенные исследования, реализация метода ветвей и границ для структурного синтеза сетей ЭВМ требует больших вычислительных затрат уже при числе возможных пунктов размещения РЦ т ≥ 40. Поэтому основная область применения точных методов для структурного синтеза и оптимизации — это проверка асимптотической эффективности приближенных методов и степени близости получаемых решений к оптимальным. В связи с этим основное внимание в книге уделено приближенным инженерным методам проектирования структур сетей ЭВМ и систем передачи данных, представляющих наибольший интерес для проектировщиков.
2.1.2 Алгоритм R-структур для синтеза абонентских СДОПусть необходимо решить задачу при определенных ограничениях. Следует определить пункты размещения РЦ и множество абонентов Хy , привязанных к РЦ.
Рассмотрим эвристический алгоритм решения указанной задачи (алгоритм R-структур), позволяющий за сравнительно небольшое число шагов найти субоптимальное решение. Алгоритм состоит из предварительного этапа и не более, чем N — 1 итераций, где N — число узлов.
Предварительный этап. 1. Находим для каждого yi множество абонентов Хyi, подключенных к нему радиальными КС по критерию минимума затрат на связь: х Є Хуi если
![]()
2. Определяем суммарный объем ИВР, выполняемых ВЦy
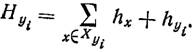
Рис 2.1 Дерево решений при синтезе структуры методом ветвей и границ
Основной этап состоит из ряда итераций. Целью каждой итерации является уменьшение суммы приведенных затрат W за счет объединения нескольких мелких ВЦ в один. Как только оказывается, что дальнейшее объединение не приводит к уменьшению критерия W, работа алгоритма прекращается.
Рассмотрим
(k+1)-ю
итерацию. Пусть в результате k итераций определено
множество наиболее целесообразных мест размещения ВЦ у (k) и найдены привязки ![]() , а соответствующее этому решению значение критерия Wk определяется
формулой.
, а соответствующее этому решению значение критерия Wk определяется
формулой.
1. Проранжируем y Є Y(k) в порядке убывания величин Ну.
2. Выберем yk такой, что НУк = min НУi. Удалим yk из множества У (k). Обозначим Уост (k) = Y (k)\yk.
3.Осуществим привязку абонентов ХУк к оставшимся ВЦ по критерию минимума затрат на связь. Новое значение критерия
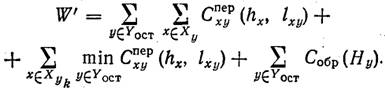
4.Сравним величины W‘ и Wk. Возможны два случая: 1) W‘≤Wk; 2) W‘>Wk.
В 1-м случае принимаем Y(k+1) = Yост(k), и итерация заканчивается. Во 2-м случае выбираем следующий по порядку пункт ук-1 и переходим к шагу 3.
Шаги 3 и 4 повторяются многократно до тех пор, пока либо очередной шаг 4 не закончится 1-м случаем, что означает конец итерации, либо множество Y(k) будет просмотрено полностью и ни один вариант укрупнения не приведет к улучшению величины критерия. Это является признаком окончания работы алгоритма.
2.2 Оптимизация структуры абонентских СДО в классе
древовидных сетей
Распространенный класс абонентских СДО для централизованных сетей ЭВМ составляют так называемые древовидные, структура которых представляет собой дерево или совокупность деревьев с корнями, которые соответствуют местам размещения РЦ. Такая структура получается, когда абонентские пункты (АП) подключают друг к другу по так называемой многопунктовой схеме. Применение многопунктовых сетей позволяет сократить капитальные затраты на создание СДО, повысить коэффициент использования каналов передачи данных, сократить общую протяженность сетей по сравнению с СДО радиальной структуры, в которой используются выделенные каналы для всех АП.
Задача синтеза абонентской СДО в классе древовидных сетей
формулируется следующим образом. Заданы множество абонентов X = {xj}, характеризуемых своими
географическими координатами местонахождения {δj, wj}
и объемами информации hj, а также места размещения
РЦ и привязки абонентов к РЦ Хyi., i = 1, т. Известны приведенные
затраты на передачу информации от пункта i к пункту j: ![]() . Требуется синтезировать структуру абонентской СДО в
классе древовидных структур минимальной стоимости при ограничениях на суммарный
поток (трафик) fij в каждой ветви (i, j):
fij ≤
dmax, где dmax
пропускная способность многопунктовой сети; fij
определяется как сумма информационных потоков от всех узлов, предшествующих
узлу i на
путях от концевых вершин к корню дерева, и потока hi, определяемого абонентом xi.
. Требуется синтезировать структуру абонентской СДО в
классе древовидных структур минимальной стоимости при ограничениях на суммарный
поток (трафик) fij в каждой ветви (i, j):
fij ≤
dmax, где dmax
пропускная способность многопунктовой сети; fij
определяется как сумма информационных потоков от всех узлов, предшествующих
узлу i на
путях от концевых вершин к корню дерева, и потока hi, определяемого абонентом xi.
Рассмотрим некоторые наиболее важные работы и алгоритмы решения этой задачи.
Задача синтеза древовидной сети впервые рассмотрена в работе Прима, в которой предложен точный алгоритм синтеза сети минимальной стоимости.
Первоначально рассмотрим исходное множество несвязанных узлов (вершин) X = {xi}.
1. Выбираем произвольный узел (подграф) xi и отыскиваем стоимость ввода ребра (i, j), связывающего xi с некоторым подграфом xjcij. Если подграфы хi и xj состоят из нескольких узлов, то отыскиваем ребро, связывающее ближайшую пару узлов xj и xil , принадлежащих к разным подграфам.
2. Среди всех пар (i, j) находим такую (i*, j*), что сi*j* = min cij.
3. Объединяем
подграфы ![]() и
и ![]() в один:
в один: ![]() =
= ![]() .
.
На этом одна итерация метода заканчивается. Таким образом, на каждой итерации число изолированных подграфов сокращается. Как только их число N станет равно 1, работа алгоритма заканчивается. Доказано, что данный алгоритм позволяет получить оптимальное решение. Заметим, что в задаче Прима не вводятся ограничения на пропускные способности сети, и поэтому отсутствует ограничение на суммарный поток frl, передаваемый по произвольной ветви (r, l). Таким образом, алгоритм Прима позволяет синтезировать кратчайшее связывающее дерево (КСД) без ограничений. Практически гораздо более важной является задача синтеза КСД с ограничениями на суммарный поток frl, определяемый пропускными способностями КС drl.
2.2.2 Алгоритм Исау-ВильямсаОдним из наиболее известных и распространенных алгоритмов синтеза КСД с ограничениями является алгоритм Исау—Вильямса, известный под названием CNDP. Предположим, что рц обработки данных расположен в пункте х1, а пропускная способность всех ветвей одинакова и равны d.
Пусть первоначально имеется некоторое множество изолированных узлов X — {x1,… хn}. Для каждого узла i вычисляем стоимость его подключения к РЦ сi1 = vi, а также стоимость связи сij двух узлов i и j между собой. В общем случае cij = cij(hi), где hi — поток информации в узле i. Вычисляем экономию от подключения узла i к j вместо подключения его к РЦ: Eij = cij ci1 = cij — vi. Находим такую пару (i*, j*), для которой Ei*j* = min Еij при условии, что hi*-hj*≤d. Если Ei*j* < 0, то вводим ветвь (i*, j*) и объединяем два узла xi* и xj* в один: Xi*H = xi*⋃xj*, при этом определяем новое значение потока информации Нi* = hi*. Пусть проведено k итераций и построено k обобщенных узлов (подграфов) X1 Х2, ... , Хк и пусть Hk = H(Xk) суммарный информационный поток всех узлов, входящих в Xk.
Опишем (k+1)-ю итерацию. Выбираем произвольный изолированный подграф Xi. Находим произвольный подграф Xj и проверяем возможность ввода ребра (i, j): Hi + Hj ≤. d.
Если условие выполняется, то вычисляем Eij = cij(Hi) - vi.
Находим такую пару (i*, j*), для которой Ei*j* =; min Еij.
Если Ei*j* < 0, то объединяем пару подграфов Xi и Xj в один: Xi* = Xj* = Xi* ⋃ Xj*, в противном случае подключаем все оставшиеся изолированные подграфы напрямую к РЦ, и конец работы алгоритма.
Алгоритм Краскала отдельно рассматривать не стоит, так как он аналогичен уже описанному. Отличительной особенность является то, что в начале все узлы изолированы, на каждом шаге отыскивают наименьшую по стоимости допустимую линию связи различных узлов.
2.2.3 Алгоритм ШармаОпределяют полярные координаты (аi, ri) каждого терминала относительно РЦ. Терминалы (узлы) рассматривают в последовательности, соответствующей возрастанию угла полярных координат ai, так что а1 ≤ а2 ≤ ...≤ ап. Строят минимальную по стоимости древовидную сеть терминалов х1, х2,…хк и РЦ, где х1, х2,…хк удовлетворяют ограничениям, но при добавлении хк+1 к многопунктовой (многоточечной) сети ограничения нарушаются. Вышеуказанную процедуру, начиная с хк+1 повторяют до тех пор, пока все терминалы не будут включены в дерево.
Как следует из описания, все перечисленные алгоритмы близки друг к другу и различаются только очередностью объединения компонент, которая обеспечивается назначением соответствующих весов значимости этим компонентам (узлам).
2.2.4 Алгоритм Фогеля (VАМ)Для каждого терминала (узла) хi подсчитывают выигрыш Ei как разность Еi = с’ij сij, где Xj ближайший к хi подграф; X’j следующий по порядку ближайший к хi подграф.
Текущая итерация алгоритма заключается в том, что находится i* такой, что Ei*= max Еi. Проводится проверка по ограничению: если оно выполняется, то хi подключается к ближайшему узлу хj. В результате образуется некоторый подграф Хi = xi ⋃ xj. Стоимость связи между двумя сегментами определяется как стоимость самой дешевой связи между двумя терминалами (узлами), принадлежащими разным подграфам. Если связь (i, j) нарушает ограничение по ПС, то сij = ∞. Когда все терминалы оказываются подключенными к РЦ, конец работы алгоритма.
2.2.5 Унифицированный алгоритм синтеза КСДВ результате анализа известных алгоритмов синтеза КСД (алгоритмы Прима, Исау — Вильямса, Краскала, Шарма и т. д.) предложен так называемый унифицированный алгоритм синтеза многопунктовых сетей, из которого можно получить как частный случай любой из известных алгоритмов синтеза, приписав определенные значения некоторым формальным параметрам. Для формального описания алгоритма введем следующие обозначения: vi — вес терминала i; Хi — подграф (набор терминалов), содержащий терминал i; (i, j) — линия, соединяющая терминалы i и j; Еij экономия, соответствующая линии (i, j); cij стоимость связи (i, j); N — число терминалов.
Шаг 0. 1. Задаем начальные значения величины vi для i = 1,2…N, используя соответствующее правило из таблицы 2.1.
2.Устанавливаем Хi = {i}, i = 1,2…N.
3.Определяем Еij =cij-vi для (i, j), если сij существует и терминалы (узлы) i и j не объединены.
Таблица 2.1 – Инициализация и коррекция весов
| Алгоритм | Инициализация весов | Коррекция весов при вводе связи (i, j) |
| Прима |
vi = 0, i = 1 vi = - ∞, i = 2,…,N |
0 -> vj, vi = 0 |
| Исау-Вильямса | vi = ci1, i = 2,N | vi = vj |
| Краскала | vi = 0, i = 1,N | Нет |
| Фогеля | v*i = bi - ai | v**i = bi - ai |
* Для определения bi, аi см. описание алгоритма.
** Величины bi, аi определяются с учетом вновь введенных компонент.
Шаг 1. Определяем Еi*j* = min Еij. Если Еi*j* = ∞, то заканчиваем поиск, в противном случае переходим к шагу 2.
Шаг 2. Оцениваем выполнение ограничений для Хi* ⋃ Xj* (объединения подграфов). Если любое из них нарушено (например, ограничение, что Нi + Hj < d), то устанавливаем Еi*j* = ∞ и возвращаемся к шагу 1. В противном случае переходим к шагу 3.
Шаг 3. 1. Вводим ветвь (i, j).
2.Изменяем величины vi для i = 1,2…N (таблица 1 и примечание 4).
3.Еij =cij-vi для тех i, для которых vi изменено.
4.Сформируем новый подграф Хi* ⋃ Xj*. Повторно пересчитываем ограничения и возвращаемся к шагу 1.
Примечания:
1.Для простоты изложения принимаем, что центр обработки данных находится в пункте 1.
2. Правила оценки весов vi используют для назначения терминалам весов значимости. Они приписывают им числовые значения, соответствующие степени желаемого использования линий, исходящих из каждого терминала.
3. Величина Еij может быть определена только в том случае, если имеется ветвь (ij) и компоненты, содержащие терминалы i и j, можно соединить без нарушения каких бы то ни было ограничений. В противном случае значение Еij является неопределенным и для удобства расчетов полагаем Еij = ∞.
4. Значения vi необходимо изменять не всегда, например, в алгоритме Краскала.
Связь между унифицированным алгоритмом и частными алгоритмами синтеза КСД отображается в таблице 1, где указаны решающие правила для вычисления начальных весов vi и их коррекция при вводе связи (i, j). Меняя правило задания и коррекции весов vi, можно получить любой из алгоритмов, причем одни правила во многих случаях дают лучшие результаты, чем другие. Однако пока не найдено такое универсальное правило, которое бы давало наилучшие результаты во всех случаях. Поэтому применяют параметрический способ определения весов. Рассмотрим один из таких способов. Запишем веса узлов в виде
vt= a(bci0 + (l — b)ci2),
где ci0, ci2 стоимости соединения терминала i с центральным узлом и с его ближайшим соседним терминалом соответственно; а и b некоторые константы, причем а ≥ 0, 0 ≤ b ≤ 1. При а = 0 получаем алгоритм Краскала; при а = b = 1 — алгоритм Исау — Вильямса; при а = 1, b = 0 — алгоритм Фогеля. Наконец, придавая а и b некоторые промежуточные значения, можем получить одновременно свойства всех вышеперечисленных алгоритмов.
На практике обычно параметрам а и b придают некоторые начальные значения и затем, варьируя их по очереди и оценивая получаемые результаты, последовательно приближаются к наилучшему. Такой способ позволяет получить результаты на 1—5 % лучше, чем при использовании алгоритмов Исау— Вильямса и Фогеля. Указанный способ параметризации можно применять для одновременного решения задач группирования и размещения терминалов, если в выражении для vi под сi0 понимать стоимость соединения терминала i с ближайшим центральным узлом. При этом никакого предварительного разбиения терминалов на группы не производится, а оно выполняется автоматически в процессе работы алгоритма.
Рассмотрим эффективность реализации унифицированного алгоритма синтеза КСД. Сложность алгоритма — время вычислений и необходимый объем памяти — зависит от размерности графа N. В общем случае граф должен быть полным, что требует просмотра всех пар узлов. Однако при большом количестве терминалов можно без значительного снижения точности результатов решать задачу с помощью разреженного графа, в котором каждый терминал связан лишь с некоторым ограниченным числом соседних терминалов. Например, в сети с 40 узлами достаточно рассматривать соединения каждого терминала с пятью соседними. Дальнейшее увеличение числа терминалов К лишь незначительно улучшает результаты. Для сети терминалов, однородно распределенных вокруг центрального узла, можно игнорировать около 75 % возможных соединений. Для быстрой оценки приближенного значения К всю область, содержащую терминалы, разбивают на прямоугольники, в пределах каждого из которых находят К ближайших соседей заданного терминала. Благодаря такому правилу число операций для повторного вычисления Eij при включении новой ветви в дерево можно снизить с N (N — 1)/2 до N х К. Кроме того, учитывая, что Еij =vi-cij, где cij константа, пересчет Еij можно свести к пересчету vi, т. е. вместо N х К повторных вычислений Eij достаточно пересчитать N раз значение vi.
В общем случае сложность алгоритма оценивается выражением: AN2 + BKN + CKN log2K, где А ,В и С константы. При этом предполагается, что программа обеспечивает возможность реализации любого правила v. Однако, если правило v таково, что не требуется пересчет vi для каждого терминала, то членом AN2 можно пренебречь. Для многих практических целей сложность алгоритма имеет вид BKN + CKN log2К. Время работы ЭВМ и требуемый объем оперативной памяти при реализации алгоритма экспериментально оценены в сетях, содержащих 20, 40, 60, 80, 120, 200 узлов при учете только пяти соседних терминалов, использовании правила изменения v по алгоритму Исау — Вильямса и суммарном графике в ветви, ограниченном значением Н ≤ N/4.
Результаты экспериментов показали, что зависимость логарифма времени работы ЭВМ от логарифма числа терминалов имеет линейный характер с наклоном кривой, который свидетельствует о квадратичной зависимости вычислительной сложности унифицированного алгоритма от размерности задачи N. В результате исследований выявлено, что время решения задачи почти не изменяется при переходе от одного правила v к другому и при изменении ограничений, в то же время оно сильно зависит от числа соседних терминалов, подключаемых к данному (т. е. числа новых линий, подключаемых к дереву). Зависимость времени работы унифицированного алгоритма синтеза КСД от числа соседних терминалов для сети с 40 терминалами приведена в таблице 2.2.
Таблица 2.2 – Зависимость времени работы терминала
| Число соседних терминалов, К | Время работы алгоритма, мин | Относительная стоимость связи |
| 1 | 0,434 | 7,77 |
| 2 | 0,491 | 5,26 |
| 3 | 0,522 | 4,54 |
| 4 | 0,557 | 4,50 |
| 5 | 0,589 | 4,48 |
| 8 | 0,691 | 4,45 |
| 10 | 0,767 | 4,45 |
| 15 | 0.985 | 4,45 |
| 20 | 1,240 | 4,45 |
| 25 | 1,503 | 4,45 |
| 30 | 1,767 | 4,45 |
| 39 | 2,245 | 4,45 |
В
модели многопунктовой ЛС, используемой как в унифицированном алгоритме
Кершенбаума — Чжоу, так и в алгоритмах Исау — Вильямса, Мартина, Краскала и
других, учитывают следующее допущение: при подключении очередного АП к
многопунктовой сети стоимость канала передачи данных между узлами i и
j ![]() не зависит от объема информации hi, при этом вводится лишь
одно ограничение: fij ≤ d, где
fij— суммарный поток (трафик)
в любой ветви (i, j). Такое
допущение справедливо в случае, когда по всей длине многопунктовой связи ее пропускная
способность d остается
постоянной. Вместе с тем использование модемов, работающих с различными
скоростями передачи данных, позволяет организовать многопунктовые связи, в
которых пропускная способность постепенно изменяется по мере приближения линии к
центру обработки данных.
не зависит от объема информации hi, при этом вводится лишь
одно ограничение: fij ≤ d, где
fij— суммарный поток (трафик)
в любой ветви (i, j). Такое
допущение справедливо в случае, когда по всей длине многопунктовой связи ее пропускная
способность d остается
постоянной. Вместе с тем использование модемов, работающих с различными
скоростями передачи данных, позволяет организовать многопунктовые связи, в
которых пропускная способность постепенно изменяется по мере приближения линии к
центру обработки данных.
Таким
образом, для многопунктовых связей с изменяемой (регулируемой) пропускной
способностью традиционно используемое допущение ![]() (hi) =
const оказывается неверным,
что исключает возможность использования унифицированного алгоритма
Кершенбаума—Чжоу.
(hi) =
const оказывается неверным,
что исключает возможность использования унифицированного алгоритма
Кершенбаума—Чжоу.
Для
решения задачи синтеза структуры древовидной сети при переменной скорости
передачи данных предложен алгоритм D-структур.
Важной особенностью алгоритма D-структур
является то, что на шаге 1 определяются оптимальные места размещения РЦ и
радиальная структура СДО, а затем она преобразуется в древовидную структуру.
Рассмотрим описание алгоритма. Введем следующие обозначения: Хi, Xj — подграфы графа X, Xi = {xi*, xi2,
... , Xin}; xi*
направляющая вершина подграфа Хi т. е. его концевая
вершина на данной итерации, куда сходятся информационные потоки из всех хЄХi. Будем предполагать, что
подключить Xi к Xj можно
введением ветви (i*, j), исходящей
только из направляющей вершины xi*, причем
хjЄХj, и на Xj ограничения
не накладываются; Hi — суммарный объем ИВР
подграфа Xi, ![]() ,hij — суммарный поток в ветви
(i, j); С(Хi)— стоимость передачи
информации во всех ветвях подграфа Xi.
,hij — суммарный поток в ветви
(i, j); С(Хi)— стоимость передачи
информации во всех ветвях подграфа Xi.
1.Применяем алгоритм синтеза R-структур, находим размещение РЦ Y* = {yi*} и привязки абонентов к РЦ Хyi.Далее предполагаем, что РЦ размещен в пункте 1.
2.Определяем
начальные веса всех вершин vi = ![]() (hi,li1) и
выполняем переход на подпрограмму «Оценка» (шаги 3—20).
(hi,li1) и
выполняем переход на подпрограмму «Оценка» (шаги 3—20).
Подпрограмма «Оценка». В подпрограмме «Оценка» определяем стоимость передачи объема информации Hi от подграфа Xi к подграфу Xj при наилучшем варианте подключения. Пусть к началу итерации построено К. подграфов X1, Х2 , … Хк.
3.Выбираем изолированный подграф Хi.
4.Проверяем возможность введения ветви (i, j)
Нi + Нj ≤dmax
Если условие выполняется, то переходим к шагу 5, в противном случае полагаем, что экономия Еij = ∞, переходим к шагу 4 и выбираем другую пару подграфов Хr, Хl для анализа.
5.Отыскиваем вершину xj1, (xj1 Є Хj), ближайшую к xi*:
![]()
6. Проверяем,
является ли xj1 направляющей
в подграфе Xj.
Если — да, то запоминаем дугу (i*,
j*), вычисляем ![]() = Ci*j*(Hi,li*j*), Н’j=Нj + Нi и переходим к шагу 21,
иначе — к шагу 7. Шаги 7—20 предназначены для нахождения наилучшего варианта
подключения Хi к
Xj.
= Ci*j*(Hi,li*j*), Н’j=Нj + Нi и переходим к шагу 21,
иначе — к шагу 7. Шаги 7—20 предназначены для нахождения наилучшего варианта
подключения Хi к
Xj.
7. Определяем направленный маршрут из xi* в xj* через вершину xj1. Пусть им окажется πi*j*={xi* – xj1 – xj2 – … xjk}, xjk=xj*.
8. Вычисляем
Сi*j1 = ![]() (Hi,li*j1), находим
ni*j1 = ]Hi/d[,
где ni*j1 — число каналов в ветви (i*, j1);
знаком] [ обозначено округление с избытком. Пусть nikjk — число каналов в ветви (ik, jк).
(Hi,li*j1), находим
ni*j1 = ]Hi/d[,
где ni*j1 — число каналов в ветви (i*, j1);
знаком] [ обозначено округление с избытком. Пусть nikjk — число каналов в ветви (ik, jк).
9. Принимаем
Сij =
0; Сij = ![]() (li*j1).
(li*j1).
10.Полагаем s = 0, где s — номер итерации.
11.s=s+1.
12.Проверяем условие, все ли ветви маршрута πi*j* просмотрены. Если s<K, то переходим к шагу 13, иначе — к 21.
13.Вычисляем
![]() (Hi) — приращение стоимости для передачи
дополнительного объема информации Hi:
(Hi) — приращение стоимости для передачи
дополнительного объема информации Hi:
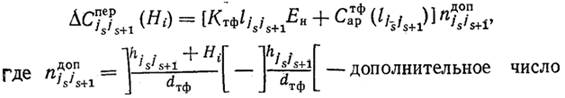
единичных каналов, которые необходимо установить в ветви (js, js+1); dТФ ПС телефонного канала связи.
14.Вычисляем величины
![]()
15.Определяем
Cij = Cij + ![]() (Hi).
(Hi).
16.
Вычисляем ![]() =
= ![]() (li*js+i, Hi).
(li*js+i, Hi).
17. Сравниваем
Cij с
![]() . Если Cij <
. Если Cij <
![]() то
переходим к шагу 11, иначе переходим к шагу 18.
то
переходим к шагу 11, иначе переходим к шагу 18.
18. Полагаем
Cij =
![]() , вводим дугу (i*, js+1)
вместо (i*,
j).
, вводим дугу (i*, js+1)
вместо (i*,
j).
19. Восстанавливаем прежние значения трафиков hij на всех предыдущих ветвях маршрута πi*j*:
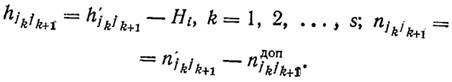
20. Переходим к шагу 11.
21. Вычисляем экономию Еij при подключении Xi к Xj по сравнению с подключением Xi к РЦ напрямую: Eij = Сij — vi.
22. Находим минимальное значение Eiljl = min Eij, где минимум берется по всем подграфам Xi, Xj.
23. Проверяем условие Eiljl < 0. Если оно выполняется, то переходим к шагу 24, иначе подключаем все оставшиеся изолированные подграфы напрямую к РЦ, и конец работы алгоритма.
24. Вводим дугу (il, jl) и подключаем Хil к Хjl. Образуем новый подграф Х’jl =Хil ⋃ Хjl с направляющей вершиной x’jl*= xjl*, H’jl=Hil+Hjl.
25. Проводим коррекцию весов для всех вершин нового подграфа Х’jl:
![]()
где ![]() — стоимость передачи информации из направляющей вершины
— стоимость передачи информации из направляющей вершины ![]() в РЦ у1.
в РЦ у1.
26. Если подграф Хjl напрямую связан с ВЦy1, то ![]() , и тогда v’jl = 0, v’il = 0. В этом случае
подграф Хjl из дальнейшего
рассмотрения исключается.
, и тогда v’jl = 0, v’il = 0. В этом случае
подграф Хjl из дальнейшего
рассмотрения исключается.
27.Проверяем условие, все ли подграфы подключены к РЦ. Если условие выполняется, то переходим к шагу 28, иначе — к шагу 3.
28.Вычисляем
критерий — суммарные приведенные затраты Wпр — для построенного
варианта D-структуры: Wпр = ![]()
Итак, как следует из описания алгоритма D-структур, объединение изолированных подграфов проводится до тех пор, пока это экономически целесообразно и выполняется ограничение, в противном случае соответствующий подграф подключается напрямую к узлу 1 (РЦ). Завершается работа алгоритма построением дерева с корнем в узле, соответствующем месту размещения РЦ. Следует отметить, что алгоритм D-структур, как и другие алгоритмы синтеза СДО в классе древовидных структур, требует вычислительных затрат порядка N log N, где N — число узлов.
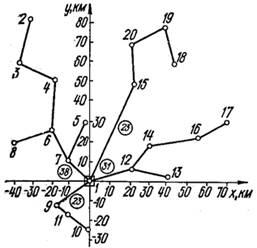
Работа различных алгоритмов синтеза КСД иллюстрируется на примере решения задачи синтеза структуры сети, имеющей N = 20 узлов. Прямоугольные координаты узлов (xj, yj) и объемы информации hj, генерируемые каждым из узлов, приведены в таблице 2.3. Стоимость единицы длины канала составляет 30 руб./(кан.- км), а ограничение по пропускной способности dmax = 25 бод (бит/c).
Таблица 2.3 Исходные данные для задачи
| і |
*Г км |
у,; км | бит/с | / | км |
щ км |
бит/о | V | */-км | у,; км | бит/с |
| 2 | —35 | 80 | 5 | 9 | —16 | — 12 | 5 | 15 | 20 | 50 | 4 |
| 3 | —39 | 60 | 7 | 10 | 0 | —23 | 11 | 16 | 53 | 25 | 2 |
| 4 | —20 | 50 | 3 | 11 | —10 | —16 | 7 | 17 | 70 | 34 | 10 |
| 5 | —4 | 30 | 4 | 12 | 22 | 7 | 5 | 18 | 42 | 62 | 8 |
| 6 | -20 | 25 | 4 і | 13 | 40 | 5 | 8 | 19 | 35 | 78 | 7 |
| 7 | -12, | 12 | 9 | 14 | 30 | 20 | 4 | 20 | 17,5 | 70' | 4 |
| 8 | —40 | 18 | 6 |
Территориальное размещение узлов (АП) и решение задачи по алгоритму Прима (КСД без ограничений) показано на рисунке 2.2, а. РЦ расположен в пункте 1. Общая протяженность сети L = 366 км, а стоимость W = 10 980 руб. Оптимальная структура с учетом ограничений, полученная по методу ветвей и границ при L = 426 км, W = 12 780 руб., изображена на рисунке 2.2, б. Цифры, указанные в кружках на ребрах графа, соответствуют суммарному трафику (бит/с), передаваемому по данной связи. Как следует из рисунка 2.2, а, для сети Прима нарушаются ограничения по пропускной способности для связей 1—12 и 1—7.
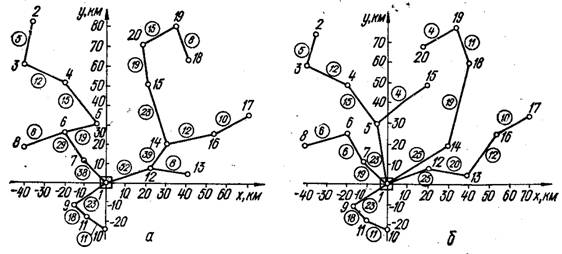
Рисунок 2.2 – Структура СДО, синтезированная по алгоритму:
а Прима; б – метод ветвей и границ
На рисунке 2.3, а построена структура СДО, синтезированная по алгоритму Исау — Вильямса, на рисунке 2.3, б — по алгоритму Шарма, на рисунке 2.3, в — по алгоритму Фогеля при L = =447 км, W = 13 400 руб. и на рисунке 2.3, г — по алгоритму Краскала. Для данной задачи из всех эвристических алгоритмов наилучшие результаты дает решение по алгоритмам Исау — Вильямса и Шарма (L = 440 км, W = 13 200 руб.), а наихудшим оказался алгоритм Краскала (L — 456 км, W = 13 680 руб.). Далее эта задача решена методом D-струк-тур для случая, когда имеются каналы двух типов d1 = 25 бит/с, c1 = 30 руб. /(кан.- км) и d2 = 40 бит/с, с2 = = 50 руб./(кан.- км). Она характеризуется показателями L = = 387 км, W = 12 330 руб. Синтезированная структура показана на рисунке 2.4.
Рисунок 2.3 – Структура СДО, синтезированная по алгоритму:
а – Исау-Вильямса; б – Шарма; в – Фогеля; г – Краскала.
Рисунок 2.4 – Структура СДО, синтезированная по алгоритму D-структур
2.3 Разработка структуры для поставленной задачиВ предыдущих разделах были описаны достоинства и недостатки различных способов разработки и оптимизации структур сетей. Приводились доводы за и против использования какой-либо структуры для поставленной задачи синтеза сети дистанционного обучения.
В результате предлагается остановиться на варианте D-структуры как наиболее универсальной. Она объединяет в себе преимущества радиальной и древовидной структур, и в то же время учитывает специфику сети передачи данных.
В рамках поставленной задачи не следует забывать о том, что составляющие элементы сети уже будут заданы конкретной ситуацией. От разработчиков не зависит расположение абонентов, существующие связи между ними, а зачастую и расположение промежуточных узлов.
Таким образом, сама по себе сеть будет задана внешними условиями, а задача синтеза сводится к оптимизации распределения абонентов между региональными центрами.
В конце работы первого этапа алгоритма построения маршрута синтезированная сеть будет приблизительно иметь вид, представленный на рисунке 2.5.
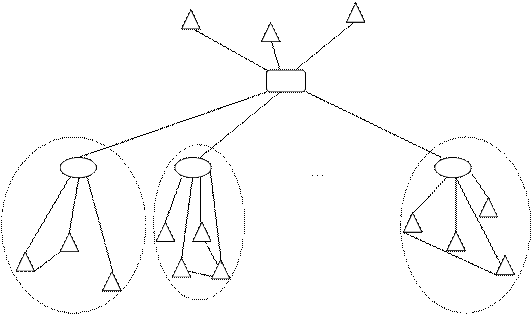 |
Рисунок 2.5 Схематичное представление синтезированной СДО
Обозначения:
![]()
![]() – ВУЗ
– ВУЗ
![]()
![]() – региональные центры
– региональные центры
![]()
![]() – абоненты
– абоненты
3 МЕТОДЫ ПОСТРОЕНИЯ ДЕРЕВЬЕВ 3.1 Задача Штейнера для построения сети
Задача Штейнера относится к классу так называемых NP-полных задач, поэтому алгоритмы, дающие точные решения, как правило, не могут быть использованы в САПР из-за неприемлемой временной сложности. Это обстоятельство послужило стимулом для разработки многочисленных эвристических алгоритмов. Наибольший практический интерес представляет алгоритм последовательного введения дополнительных вершин в дерево Прима-Краскала. Использование предложенного алгоритма позволяет строить деревья Штейнера, длина которых в среднем не превышает длину оптимального дерева Штейнера более чем на 0.5 процента. Временные характеристики модификаций алгоритма позволяют успешно использовать его на данном этапе построения маршрута.
Математическая модель задачи синтеза структуры сети по критерию стоимости приведена ниже.
Пусть имеется
множество Х={xj} абонентов сети – источников информации с объемом трафика
абонента h;
{gj, wj} – географические
координаты пункта, а также места размещения сервера {yi*} и привязки абонентов к
серверу Xyi,i=1..m. Известны приведенные
затраты на передачу информации от пункта i к пункту j: ![]() . Требуется
синтезировать структуру сети в классе древовидных структур минимальной
стоимости при ограничениях на суммарный поток fij в каждой ветви (i,j):
. Требуется
синтезировать структуру сети в классе древовидных структур минимальной
стоимости при ограничениях на суммарный поток fij в каждой ветви (i,j): ![]() , где dmax – пропускная способность
линии связи; fij определяется как сумма информационных потоков от всех узлов,
предшествующих узлу i на путях от концевых вершин к корню дерева и потока hi, определяемого абонентом
xi.
, где dmax – пропускная способность
линии связи; fij определяется как сумма информационных потоков от всех узлов,
предшествующих узлу i на путях от концевых вершин к корню дерева и потока hi, определяемого абонентом
xi.
Для ДШ постановка задачи выглядит следующим образом.
Дано:
– сеть, представленная в виде ненаправленного графа G=(V, E), где V – набор узлов, а Е набор связей;
– матрица
стоимости W,
где Wij показывает стоимость использования связи (i,j) ![]() Е;
Е;
– узел-центр s ![]() V и набор узлов-участников
D
V и набор узлов-участников
D ![]() V;
V;
– каждый узел vi имеет координаты xi и yi на экране, название и тип (центр, участник, вершина Штейнера, незадействованный узел).
Нужно найти такое дерево Т сети G с корнем в s, стягивающее всех членов набора D так, что полная стоимость ребер дерева Т будет минимальна. В стоимость обычно включается время передачи единицы данных по каналу, расстояние или денежный эквивалент данного соединения, пропускная способность канала или комбинация критериев.
Основными критериями оценки алгоритма являются скорость сходимости и близость получаемого решения к оптимальному.
Предложен ряд процедур, позволяющих кардинальным образом сократить время работы за счет предварительной «отбраковки» тех вершин, чья вероятность оказаться штейнеровской точкой равна нулю или крайне мала. Данная процедура в несколько раз уменьшает временную сложность исходного алгоритма и, что не менее важно, в среднем качество получаемых решений не ухудшается.
В данной работе под средними показателями алгоритма (качественными, временными или какими либо другими) следует понимать средний результат для 10.000 задач. Тестовый набор для каждого значения размерности состоит из 10.000 различных задач, полученных случайным образом. Все результаты, приведенные в работе, получены на этих тестовых наборах.
Можно отметить, что для модифицированного варианта алгоритма процент улучшения дерева Прима-Краскала немного, всего лишь на несколько сотых долей, но все-таки больше, чем тот же самый показатель исходного алгоритма. Это обусловлено сокращением числа локальных неоптимальных минимумов эвристики за счет сокращения числа возможных дополнительных точек.
Однако можно сделать интересное наблюдение, если сравнивать не средние результаты достаточно большого тестового набора, а результаты, полученные двумя различными способами для каждой конкретной задачи. В строке G («good») приведен процент от общего числа тех задач, в которых вышеописанный модифицированный алгоритм дает выигрыш в суммарной длине всех ребер дерева по сравнению с исходным алгоритмом. В строке B («bad») приведен процент тех задач, в которых модифицированный алгоритм уступает исходному. И, наконец, в строке U («unchanged») показан процент всех оставшихся задач, для которых результаты работы обоих алгоритмов совпали.
Можно отметить две тенденции. Во-первых, с ростом числа точек уменьшается число задач, в которых оба алгоритма получают один и тот же результат. Во-вторых, число более удачных решений модифицированного алгоритма по отношению к исходному приблизительно равно числу менее удачных решений. Данное соотношение справедливо как для задач малой размерности, так и для больших задач. Объяснение этому достаточно простое. Как и большинство всех известных эвристических алгоритмов (и не только применительно к задаче Штейнера), данная эвристика не всегда сходится к оптимальному решению, а, как раз наоборот, чаще сходится к некоторому решению - локальному минимуму, отличному от оптимального решения. С ростом числа точек растет количество таких локальных неоптимальных минимумов, и, соответственно, уменьшается вероятность схождения алгоритма к решению с наилучшим результатом. Также на окончательный результат сильно влияет первая итерация алгоритма, очень часто именно она задает практически окончательную конфигурацию дерева, которая уже очень мало изменяется на последующих итерациях.
Данные рассуждения не являются каким-то таким уж невероятным открытием. Однако, тот факт, что средние результаты двух алгоритмов отличаются всего лишь во втором, третьем, а то и большем знаке, ловко маскирует другую тенденцию. А именно, практически абсолютная идентичность средних результатов достигается не за счет сходимости двух разных алгоритмов к одному и тому же решению, а за счет, так сказать, статистической схожести этих двух эвристик. Эта интересная тенденция, по-видимому, до сих пор выпадала из поля зрения исследователей, работающих с этим алгоритмом. Сравнивая различные методы улучшения качественных показателей, коллеги ориентировались только на средний результат и стремились получить максимальный выигрыш сразу, за один проход. Яркий пример этого подхода iterated 2-Steiner algorithm, где предлагается оценивать выигрыш от введения сразу двух возможных точек Штейнера в дерево Прима-Краскала. Временная сложность алгоритма в этом случае вырастает невероятно, что уже не позволяет использовать его на данном этапе.
Данная работа предлагает способ, позволяющий за приемлемое время значительно улучшить качественные показатели модифицированного алгоритма за счет последующего динамического перестроения дерева Штейнера. Иными словами, использовать данную конфигурацию дерева (близкую к оптимальному решению) не как окончательный результат, а как исходную конфигурацию для следующего этапа эвристики.
3.2 Локальное перестроение дерева ШтейнераДля улучшения начальной конфигурации дерева предлагается для каждой глобальной точки исходной задачи провести процедуру локального перестроения дерева Штейнера. Эту процедуру следует проводить на множестве точек, включающем саму эту точку и инцидентные ей вершины (рисунок 3.1). Поскольку степень точки в дереве Штейнера не может быть выше 4-х, то максимальная размерность локальной задачи Штейнера, соответственно, не может быть больше 5-ти. Для задач же с размерностью до 5-ти точек включительно, как известно, существуют быстрые алгоритмы определения оптимальной конфигурации дерева Штейнера.
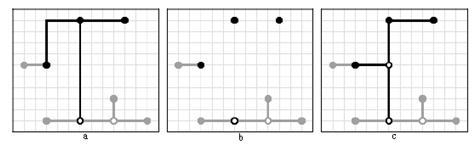
Рисунок 3.1 – Процесс локального перестроения дерева для глобальной вершины
Для данного метода перестроения дерева характерно некоторое число положительных исходов данной процедуры (стратегия A).
Аналогичную процедуру можно провести и для дополнительных точек, локально перестраивая дерево Штейнера на том же множестве точек инцидентных данной точке, но, в отличие от той же процедуры для глобальной точки, не включая в данное множество рассматриваемую точку (рисунок 3.2). Данный подход также позволяет получить некоторое небольшое число положительных исходов (стратегия B).
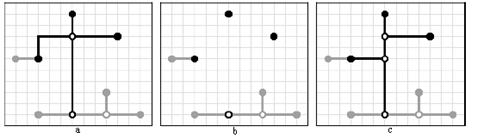
Рисунок 3.2 – Процесс локального перестроения дерева для дополнительной вершины
Факт наличия выигрыша от использования описываемых алгоритмов и сам факт незначительности этого выигрыша объясняются особенностями первого этапа модифицированного алгоритма. На этапе предварительной выборки дополнительных точек существует очень маленькая, но все-таки ненулевая вероятность пропустить точку, которая могла бы дать выигрыш при включении ее в дерево Штейнера.
К достоинствам вышеописанных процедур можно отнести линейную от размерности задачи временную сложность. Недостаток же очевиден – это малое число положительных исходов.
Использование совокупности только этих двух алгоритмов в качестве процедуры перестройки дерева Штейнера неэффективно. Большая часть времени будет затрачена на такие подготовительные процедуры, как выделение памяти и инициализация переменных, а затем, после отработки алгоритмов, на освобождение занятой памяти (стратегия 0). Однако использование этих процедур в качестве отдельного этапа (первого среди нескольких) – вполне разумно, тем более, что максимальный эффект от их использования достигается в совместном использовании с другими подходами, что и будет показано немного ниже.
Стоит добавить, что можно не ограничиваться рассмотрением только лишь инцидентных вершин каждой рассматриваемой точки. Если в построение локального дерева Штейнера включить инцидентные вершины второго уровня (рисунок 3.3) и использовать для определения конфигурации дерева модифицированный алгоритм, то количество положительных исходов вырастает во много раз за счет, конечно, увеличения временных показателей (стратегии D, E, F).
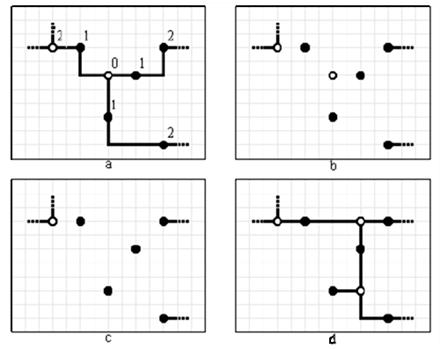
Рисунок 3.3 – Локальное перестроение дерева Штейнера для вершины 0 и инцидентных вершин первого и второго уровней
3.3 Процедура объединения свободных ребер
Введем понятие свободного ребра. Свободное ребро – это ребро, соединяющее две несовпадающие вершины, причем X и Y координаты первой вершины не равны соответственно X и Y координатам второй вершины.
Разработчик свободен в выборе окончательной конфигурации этого соединения, поэтому его будем называть «свободным». Вершины, у которых равны или X координаты, или Y координаты, можно соединить только одним единственным оптимальным способом − вертикальным или горизонтальным ребром соответственно (рисунок 3.4). Такие ребра будем называть жесткими или несвободными.
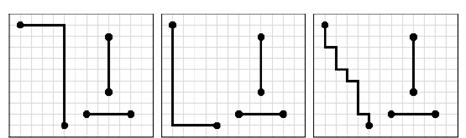
Рисунок 3.4 – Примеры конфигураций свободного ребра и двух жестких ребер
Предлагается использовать следующий метод перестроения дерева Штейнера. Для каждой пары свободных ребер AB и CD текущего дерева Штейнера ищется и добавляется в дерево ребро EF минимальной длины, соединяющее ребра AB и CD. В возникающем в результате такого добавления цикле удаляется самое длинное ребро (рисунок 3.5). При удалении ребра для избежания появления избыточных точек необходимо учитывать, что точки Штейнера могут иметь только степень 3 или 4. Если данная процедура дает выигрыш в общей длине дерева, то запоминается текущая конфигурация дерева, если нет, то восстанавливается исходная конфигурация.
Выигрыш в данном случае составляет 3 условные единицы длины.
Для избежания избыточных вычислений можно воспользоваться простой дополнительной проверкой: расстояние между двумя свободными ребрами должно быть строго меньше длины самого большого ребра в текущем дереве Штейнера.
Если два свободных ребра имеют общую вершину, то такую пару ребер можно не рассматривать, поскольку ситуация, аналогичная той, которая изображена на рисунке 3.6 (a), принципиально невозможна после работы первого этапа (локальное перестроение дерева Штейнера для точек обоих типов). Остальные конфигурации, такие как, например, на рисунке 3.6 (b) не могут дать какой-либо выигрыш в суммарной длине дерева.
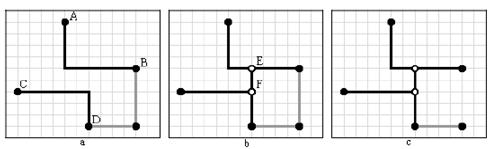
Рисунок 3.5 – Процесс объединения двух свободных ребер
(a) исходная конфигурация;
(b) в дерево добавляется ребро EF, соединяющее два свободных ребра AB и CD;
(c) в возникшем цикле удаляется самое длинное ребро.
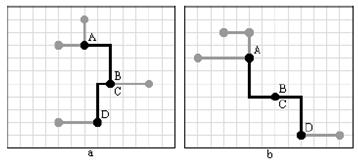
Рисунок 3.6 – Примеры возможных положений свободных ребер, имеющих общую вершину
Выбор только свободных ребер в описываемом алгоритме не случаен. Экспериментальные исследования показали, что при хорошей начальной конфигурации дерева достаточно ограничиться одним лишь рассмотрением всех пар свободных ребер (стратегия G). Попытка объединить все остальные ребра (горизонтальные и вертикальные) как между собой, так и со свободными ребрами, в общем случае гораздо менее эффективна (стратегия H). Соотношение количества положительных исходов ко времени счета значительно уступает тому же показателю процедуры объединения только свободных ребер.
3.4 Процедура отсоединения ребра, содержащего дополнительнуювершину
В качестве следующего этапа предлагается воспользоваться следующей процедурой. В текущем дереве Штейнера убирается одно из ребер. Как минимум одна из вершин такого ребра должна быть дополнительной. Результатом такого удаления являются два поддерева. Оба они перестраиваются с целью достижения максимального выигрыша и снова соединяются вместе.
Если в результате данной процедуры есть выигрыш в суммарной длине дерева, то данная конфигурация становится текущей, если – нет, то восстанавливается исходная конфигурация дерева (рисунок 3.7). Данная операция повторяется в том же виде для каждого следующего ребра, одна из вершин которого дополнительная. Причем для достижения большей эффективности все новые ребра такого типа, возникающие в результате работы процедуры, следует добавлять в конец соответствующего списка.
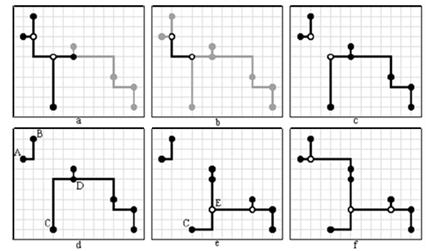
Рисунок 3.7 – Перестроение дерева с использованием процедуры отсоединения ребра с дополнительной вершиной
(a) исходное дерево; формируется список ребер, один конец которых дополнительная вершина;
(b) перестроение на примере одного из ребер;
(c) выбранное ребро удаляется из дерева;
(d) удаляются дополнительные вершины со степенью меньше трех;
(e) два поддерева перестраиваются с целью минимизации суммарной длины ребер;
(f) поддеревья соединяются кратчайшим образом.
Выигрыш в данном случае составляет 2 условные единицы длины.
Для перестроения возникающих в результате удаления ребра двух деревьев предлагается использовать все выше предложенные подходы. А именно: локальное перестроение дерева для глобальных и дополнительных вершин (стратегия I), то же самое плюс объединение свободных ребер (стратегия J). Рассматривать следует лишь только те вершины и ребра, которые были изменены или появились в результате разделения дерева на два поддерева. Действительно, использование тех или иных процедур перестроения в качестве самостоятельных этапов перед работой рассматриваемого алгоритма гарантирует то, что их повторное использование не может дать какой-либо выигрыш. Поэтому, например, в процедуре объединения свободных ребер поддерева вместо рассмотрения всех пар свободных ребер поддерева достаточно ограничиться рассмотрением всех новых свободных ребер с остальными. Одно новое ребро обычно возникает при начальном отсоединении ребра (ребра AB и CD на рисунке 3.7d), одно или несколько могут возникнуть после процедуры локального перестроения (ребро CE на рисунке 3.7e).
При рассмотрении каждой пары ребер следует учитывать уже упомянутое условие, а именно, расстояние между ребрами должно быть строго меньше длины самого длинного ребра поддерева. Все данные ограничения позволяют существенно сократить общее время счета алгоритма без какой-либо потери качества. Отсюда вытекает следующий вывод. Если обе вершины удаляемого ребра дополнительные, то следует пытаться перестроить оба поддерева, если же одна вершина дополнительная, а другая глобальная, то поддерево, соответствующее второй вершине можно даже не рассматривать. Характер используемых процедур перестроения не может дать какой-либо выигрыш в суммарной длине второго поддерева.
Экспериментальные результаты показали, что, если после процедур перестроения поддеревьев суммарный выигрыш так и остался равен длине удаленного ребра, то эти два поддерева можно даже и не объединять, а сразу возвращаться к исходной конфигурации. Вероятность выигрыша в данном случае мала, и этот выигрыш несопоставим с тем временем, которое требуется на соединение двух деревьев, поскольку в данном случае приходится вычислять расстояния между каждым ребром первого дерева и каждым ребром второго дерева.
Все выше приведенные рассуждения, ограничения и экспериментальные данные объясняют постулированное в самом начале главное ограничение. Удаление ребра, обе вершины которого глобальные вершины, абсолютно неэффективная процедура.
Для максимального улучшения дерева можно добавить также процедуру объединения вершины и свободного ребра: сначала в качестве самостоятельного этапа, а затем в составе процедуры перестроения поддеревьев (стратегия K приложения). Этот метод аналогичен процедуре объединения двух свободных ребер (рисунок 3.8).
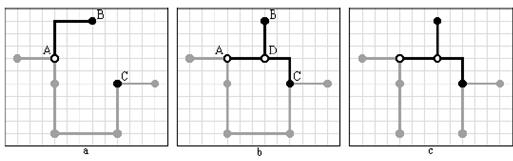
Рисунок 3.8 – Процесс объединения свободного ребра и вершины
(a) исходная конфигурация;
(b) в дерево добавляется ребро CD, соединяющее свободное ребро AB и вершину C;
(c) в возникшем цикле удаляется самое длинное ребро.
Выигрыш в данном случае составляет 1 условную единицу длины.
Жесткие ребра не берутся в рассмотрение по уже указанной причине, а именно, изначально хорошая конфигурация дерева Штейнера дает максимальную эффективность только лишь при работе со свободными ребрами. А при работе в составе процедуры перестроения поддеревьев следует ограничиться следующими множествами:
- новые свободные ребра – все вершины поддерева;
- все новые и измененные вершины поддерева – все старые и новые свободные ребра.
3.5 Стратегии алгоритмаСтратегия 0 – процедура перестроения дерева без каких-либо методов улучшения как таковых. Посчитана отдельно и приведена здесь для того, чтобы показать общее для всех стратегий время, затрачиваемое на предварительные мероприятия (выделение памяти, инициализация переменных), и время на последующее освобождение памяти, дабы отделить это время от непосредственно методов улучшения.
Стратегия A – локальное перестроение дерева для всех глобальных точек.
Стратегия B – локальное перестроение дерева для всех дополнительных точек.
Стратегия C – объединение двух вышеописанных стратегий A и B.
Стратегии D, E, F аналогичны стратегиям A, B, C соответственно, но в каждом случае локального перестроения дерева включены в рассмотрение инцидентные точки второго уровня.
Все нижеследующие стратегии содержат стратегию C в качестве первого этапа (кроме специально оговоренного случая).
Стратегия G – процедура объединения свободных ребер.
Стратегия H – процедура объединения всех ребер (горизонтальных, вертикальных и свободных).
Все нижеследующие стратегии содержат стратегию G в качестве второго этапа.
Стратегия I – процедура удаления ребер с дополнительными точками. В качестве процедуры перестроения поддеревьев используется локальное перестроение дерева для глобальных и дополнительных точек.
Стратегия J – то же самое, что и стратегия I, но в процедуру перестроения поддеревьев добавлена процедура объединения свободных ребер.
Стратегия K – то же самое, что и стратегия J, но добавлена процедура объединения точек и свободных ребер в качестве отдельного этапа и в составе процедуры перестроения поддеревьев.
Стратегия L – стратегия максимального улучшения начального дерева Штейнера. Включает в себя все процедуры стратегии K, но во всех местах своего использования метод локального перестроения дерева заменен той же процедурой, но с использованием точек второго уровня инцидентности.
3.6 Заключительный вид алгоритмаИсходный алгоритм последовательного введения дополнительных точек в дерево ПримаКраскала выглядит теперь следующим образом:
- 1 этап: предварительная отбраковка дополнительных вершин;
- 2 этап: последовательное введение дополнительных вершин в дерево Прима;
- 3 этап: динамическое перестроение дерева Штейнера.
Непосредственно перед работой алгоритма часть дополнительных точек исключается из рассмотрения за счет процедуры «отбраковки». Затем после отработки основной части алгоритма запускается вышеописанная процедура динамического перестроения дерева. Она исправляет «огрехи» предварительного этапа, поскольку существует маленькая, но все же ненулевая вероятность исключить из рассмотрения точку, которая дала бы выигрыш в длине при включении в дерево Штейнера. Попутно эта процедура исправляет недостатки основного алгоритма, трансформируя исходное дерево в дерево с лучшей, а зачастую, оптимальной конфигурацией.
Для этапа перестроения предлагается использовать стратегию J. Эта стратегия в сравнении с другими имеет лучшее соотношение числа положительных исходов ко времени счета. Среднее число положительных исходов при применении данного метода составляет несколько процентов для задач с 6-ю – 7-ю точками, уже около двух десятков процентов для задач с 10-ю точками и больше 90% для задач с 60-ю точками.
Совместный итог работы и предложенного подхода – новый алгоритм, временные показатели которого в несколько раз лучше исходного алгоритма. Качество получаемых решений при этом близко к оптимальным показателям.
3.7 Генетические алгоритмыГенетические алгоритмы – есть поисковые алгоритмы, основанные на механизмах натуральной селекции и натуральной генетики. Их реализовывает сильнейших среди рассматриваемых структур формируя и изменяя алгоритм, на основе моделирования эволюций поиска.
Популяция набор решений.
Эволюция популяции – чередование поколений, в которых хромосомы изменяют свои гены, т.о. чтобы каждая новая популяция наилучшим образом приспосабливалась к новой (внешней) среде.
Основной сложностью применения ГА для построения ортогональных деревьев Штейнера является оптимальное кодирование и выбор эффективных генетических операторов. Повышение эффективности алгоритма достигается за счет введения в процедуру поиска оператора мутации, транслокации и рекомбинации. Оператор транслокации до последнего времени не применялся при решении задач оптимизации.
Предлагается комбинированный эвристический алгоритм построения дерева Штейнера, использующий модифицированный метод кодирования, основанный на триангуляции, и модифицированный точечный оператор кроссинговера.
Данное множество вершин в ортогональной плоскости разбивается на триады в соответствии с расположением вершин на координатной плоскости. Далее происходит построение ДШ для каждой из триад методом горизонтальных или вертикальных столбов (метод определяется случайным образом). Ген в хромосоме будет содержать информацию об одной из триад: номера вершин, вид столба (горизонтальный/вертикальный) и номер вершины, через которую проходит столб.
На следующем этапе проводим отбор. Две хромосомы, имеющие наименьшее значение целевой функции (суммарной длины ребер) будут участвовать в воспроизводстве далее. Следующим этапом, к отобранным хромосомам применим модифицированный точечный оператор кроссинговера (точечный оператор кроссинговера). Получение потомков получается путем замены одного из генов родителей (например, третий ген первого родителя становится на место третьего гена второго родителя, а тот в свою очередь на место первого родителя, в результате, получив двух потомков). Повышение эффективности алгоритма достигается за счет введения в процедуру поиска оператора мутации, транслокации и рекомбинации.
Оператор мутации случайно выбирает ген в хромосоме и обменивает его на рядом расположенный ген.
В процессе транслокации случайным образом производится разрыв в каждой хромосоме в определенном для обеих хромосом месте. При формировании потомка берется левая часть до разрыва из одного родителя и инверсия правой части до разрыва из второго родителя. В процессе рекомбинации в результирующую популяцию добавляются хромосомы являющиеся родителями на этапах кроссинговера, мутации и транслокации. Далее производится элитная селекция. Отбираются две наилучшие хромосомы. В случае, если критерий остановки не достигнут, процедура оптимизации повторяется. Критерием остановки является количество популяций, определяемое пользователем.
Применение ГА для решения задачи построения ДШ дает, возможно, не самый лучший результат, но, при соответствующем подборе генетических операторов, он может быть достаточно хорошим. Главное достоинство применения генетических алгоритмов – относительно небольшое время решения. Особенно это важно в условиях очень большого числа абонентов сети, которое постоянно растет, и изменяющихся сетях (их конфигурации и стоимости услуг).
3.8 Результат работы алгоритмаВ итоге работы второго этапа алгоритма построения маршрута должна быть получена структура (маршрут рассылки), соответствующая конкретному случаю. Т.е. определены связи, ведущие к нужным абонентам и затрачивающие на это минимум ресурсов. В этом случае могут использоваться соединения между абонентами, минуя промежуточные узлы, к тому же не всегда в рассылке должны быть задействованы все абоненты.
Пример полученного маршрута для схемы сети, представленной на предыдущем этапе, показан на рисунке 3.9.
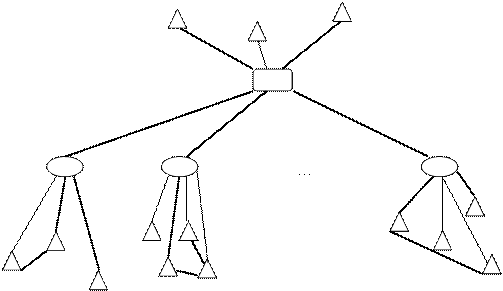

Рисунок 3.9 Пример построенного маршрута рассылки
Здесь более темным цветом показаны задействованные связи, обычным цветом – связи существующие, но не участвующие в данной рассылке.
4 РЕАЛИЗАЦИЯ АЛГОРИТМА 4.1 Постановка задачи разработки программного продукта
Задача разработки программного продукта состоит в том, чтобы он предоставлял необходимые возможности. А именно:
– возможность создания и редактирования сети, т.е. добавление и удаление узлов и связей;
визуализация схемы построенного маршрута;
– вывод результатов расчетов для пересылки по построенному маршруту;
– возможность настраивать параметры алгоритма для получения наиболее оптимального результата;
предоставление необходимой информации о программе и правилах работы с ней (помощь);
– удобный пользовательский интерфейс.
С учетом современных технических средств, программа должна иметь графический интерфейс, представляемый на цветном дисплее, совместимость с операционной системой Windows, удобную работу с клавиатурой и мышью.
Структура ПП должна учитывать все перечисленные выше технические и функциональные требования.
Сложность генетических алгоритмов при решении задачи Штейнера состоит в кодировке исходных данных. В то же время эта кодировка не применима при создании структуры сети и ее отображении.
Учитывая специфику выбранного подхода к решению задачи, нужно разработать удобные структуры данных для хранения элементов сети, их обработки в алгоритме и вывода результатов.
4.2 Описание структур данных
Как уже говорилось ранее, для хранения данных в этой программе необходимо разработать несколько структур, в соответствии с процедурой обработки этих данных.
На этапе создания структуры сети, т.е. добавления узлов и связей между ними, данные хранятся в двух отдельных массивах: массив узлов и массив связей. Эти массивы имеют различную структуру.
Структура узлов:
Point = record
x,y:integer;
t:boolean;
end;
Здесь x и y – координаты узла на плоскости сети, t – его тип (активный или неактивный).
Структура связей:
Link = record
b,e:byte;
t:boolean;
p:real;
end;
Поля b и e обозначают номера начального и конечного узлов связи соответственно, t – тип связи (используется ли она в построенном маршруте), p – стоимость пересылки данных по этой связи.
При таком виде хранения данных можно было бы использовать вещественное представление хромосом генетических алгоритмов. Но в этом случае хромосома должна быть двумерной, так как учитываются координаты х и у. В то же время такие хромосомы предполагали бы изменение координат, т.е. имеющиеся узлы в большинстве своем не будут задействованы. Поэтому предполагается совмещать вещественное представление хромосом с традиционным. Точки Штейнера могут быть добавлены, поэтому для них допустимо использовать вещественные хромосомы. Для заданных узлов следует работать с их номерами. Целевая функция должна будет объединять в себе обработку этих двух типов хромосом.
Конкретный механизм совмещения обработки и представления хромосом будет разработан в соответствии с выбранным алгоритмом.
4.3 Настройки алгоритмаДля практического применения алгоритма следует учитывать особенности каждой конкретной ситуации. С помощью программы можно воссоздать структуру любой реальной сети, задать ее параметры (например, стоимость каждой связи), расположить и связать узлы сети в соответствии с действительностью.
При этом для разных ситуаций могут быть оптимальными разные настройки алгоритма. За счет того, что генетические алгоритмы работают достаточно быстро, можно производить пересчет маршрута с самыми различными настройками, подбирая наиболее оптимальный вариант.
В данном ПП предполагается предоставить такие возможности по настройке алгоритма построения маршрута:
– выбор метода отбора предков: равномерный, пропорциональный;
– выбор оператора кроссинговера: одноточечный или двухточечный;
– выбор оператора мутации: сколько генов будет изменяться и как будет происходить их отбор;
– выбор степени элитизма: какой процент наилучших хромосом попадет в следующую популяцию без изменения.
В результате подбора различных настроек ПП поможет построить наиболее оптимальный маршрут для конкретной ситуации.
ВЫВОДЫ
В данной работе затронута актуальная на сегодняшний день тема дистанционного обучения. Его распространение в разные уголки страны позволит значительно повысить уровень образования. И для того, чтобы сделать дистанционное обучение более доступным, разрабатывается этот проект.
Для оптимизации построения сетей дистанционного обучения применяется множество методов. В работе проведен анализ наиболее известных алгоритмов построения структуры сети. Предлагается разбить задачу на два этапа: определение общей структуры и построение маршрута для определенной задачи. Строго математические методы ограничены количеством абонентов. Для растущего числа студентов построение сети становится дорогим и длительным процессом, особенно учитывая скорость изменения самих сетей и их услуг. Поэтому существует тенденция применения эвристических методов решения данной задачи. Один из таких методов генетические алгоритмы.
Эволюционное программирование, частью которого есть ГА, является относительно новым и достаточно перспективным направлением среди методов решения подобных задач. Существуют большие возможности по усовершенствованию методов и соответственно результатов.
В конечном итоге этой реализацией станет программный продукт, который позволит наглядно представить результаты работы алгоритма, применить его для реальных сетей дистанционного обучения.
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
1. Дюк В., Самойленко А. Data Mining: учебный курс. – СПб: Питер, 2001. – 386с.
2. Калашников Р.С. Построение дерева Штейнера методом генетического поиска // Перспективные информационные технологии и интеллектуальные системы. – 2005. – № 2 (22).
3. Курейчик В.М. Генетические алгоритмы. – Таганрог: изд-во ТРТУ, 1998. – 242 с.
4. Маршалл У. Берн, Рональд Л. Грэм Поиск кратчайших сетей. // Scientific American (издание на русском языке). – 1989. – № 3. – С. 64–70.
5. Панченко Т.В. Генетические алгоритмы: Учебно-методическое пособие / под ред. Ю.Ю. Тарасевича. – Астрахань: АГУ, 2007. – 87 с.
6. Рыженко Н.В. Алгоритм построения минимальных связывающих деревьев с дополнительными вершинами (деревьев Штейнера) для случая прямоугольной метрики. Труды ИМВС РАН, 2002.
© 2010 Интернет База Рефератов