
Рефераты по сексологии
Рефераты по информатике программированию
Рефераты по биологии
Рефераты по экономике
Рефераты по москвоведению
Рефераты по экологии
Краткое содержание произведений
Рефераты по физкультуре и спорту
Топики по английскому языку
Рефераты по математике
Рефераты по музыке
Остальные рефераты
Рефераты по авиации и космонавтике
Рефераты по административному праву
Рефераты по безопасности жизнедеятельности
Рефераты по арбитражному процессу
Рефераты по архитектуре
Рефераты по астрономии
Рефераты по банковскому делу
Рефераты по биржевому делу
Рефераты по ботанике и сельскому хозяйству
Рефераты по бухгалтерскому учету и аудиту
Рефераты по валютным отношениям
Рефераты по ветеринарии
Рефераты для военной кафедры
Рефераты по географии
Рефераты по геодезии
Рефераты по геологии
Рефераты по геополитике
Рефераты по государству и праву
Рефераты по гражданскому праву и процессу
Рефераты по делопроизводству
Рефераты по кредитованию
Рефераты по естествознанию
Рефераты по истории техники
Рефераты по журналистике
Рефераты по зоологии
Рефераты по инвестициям
Рефераты по информатике
Исторические личности
Рефераты по кибернетике
Рефераты по коммуникации и связи
Шпаргалка: Архитектура ЭВМ
Шпаргалка: Архитектура ЭВМ
Содержание
1. Обобщенная структура центрального процессора
2. Центральное Устройство Управления.
3. Основные характеристики и классификация устройств управления
4. Арифметико-Логическое Устройство (АЛУ)
5. Назначение и классификация АЛУ.
6. Структура АЛУ для сложения и вычитания чисел с фиксированной запятой
7. Структура АЛУ для умножения чисел с фиксированной запятой (сумматор частичных произведений)
8. Умножение, начиная с младших разрядов множителя со сдвигом суммы частичных произведений вправо и при неподвижном множимом.
9. Умножение, начиная с младших разрядов множителя при сдвиге множимого влево и неподвижной сумме частичных произведений.
10. Умножение, начиная со старших разрядов множителя при сдвиге суммы частичных произведений влево и неподвижном множимом.
11. Умножение, начиная со старших разрядов множителя при сдвиге вправо множимого и неподвижной сумме частичных произведений.
12. Методы ускорения умножения. Умножения на 2 разряда множителя.
13. Деление дробных чисел
14. Деление целых положительных чисел.
18. Классификация аппаратных средств многопроцессорных вычислительных комплексов (МПВК) по Ф.Г. Энслоу.
19. МПВК с общей шиной
20. МПВК с перекрестной коммутацией
21. МПВК с многовходовыми
22. Ассоциативные вычислительные системы
23. Матричные вычислительные системы
24. Структура векторной вычислительной системы.
25. Принципы векторной обработки.
26. Факторы, снижающие производительность векторных ЭВМ.
27. Параллельная обработка данных на ЭВМ.
28. Краткая история появления параллелизма в архитектуре ЭВМ.
29. Использования параллельных вычислительных систем. Закон Амдала.
30. Конвейерная и суперскалярная обработка.
31. Принципы управления внешними устройствами. Понятие интерфейса ввода-вывода.
32. Типы интерфейсов.
33. Управление обменом данными.
34. Понятие подхода открытых систем. Свойства открытых систем.
35. Профили стандартов открытых систем.
36. Архитектура открытых систем.
37. Преимущества идеологии открытых систем
38. Открытые системы и объектно-ориентированный подход
39. Вычислительные системы. Назначение. Принципы построения. Признаки структурной и функциональной организации
40. Классификация архитектур вычислительных систем. Классификация Флинна
41. Классификация Шора
42. Параллельные вычислительные системы. Основные классы современных параллельных вычислительных систем
43. Способы доступа к модулям памяти параллельных компьютеров
44. Современное состояние параллельных вычислительных технологий
45. MPP-архитектура
46. SMP-архитектура
47. PVP-архитектура
48. Кластерные системы
49. MBC-архитектура
50. NUMA-архитектура
1. Обобщенная структура центрального процессора
Процессоры бывают: сигнальные, коммуникационные, общего назначения, специализированные
Машинный такт – интервал времени, в течении которого выполняется одна микрокоманда.
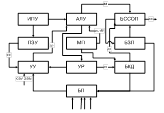
ИПУ – Инженерный Пульт Управления
МП – Местная Память
УР – Управляющие Регистры
БКД – Блок Контроля и Диагностики
БССОП – Блок Связи С Основной Памятью
БЗП – Блок Защиты Памяти
Для реализации программного режима работы наряду с программными средствами используется специальные аппаратные средства. Кроме уже упомянутой системы прерываний к ним относятся следующие средства: защита памяти, динамического распределения памяти, службы времени и др.
2. Центральное Устройство Управления
ЦУУ формирует управляющие сигналы для следующих функций:
- выборки из ОЗУ (ПЗУ) кодов очередной команды
- расшифровки кодов операций и признака выбранной операции
- формирование исоплнительного адреса операнда
- анализ запросов на прерывание исполняемой программы
- формирование адреса следующей команды
Структура ЦУУ:
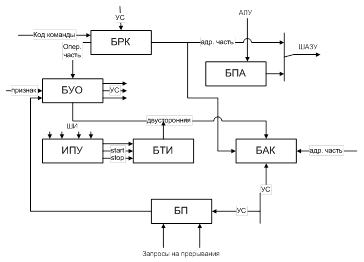
БРК – Блок Регистра Команд БПА – Блок Переадресации Адресов
БТИ – Блок Тактовых Импульсов ИПУ – Инженерный Пульт Управления
БП – Блок Прерываний БАК Блок Адреса Команд
БУО – Блок Управления Операциями УС – Управляющие Сигналы
Алгоритм: 1)код очередной команды программы принимается для расшифровки и исполнения в БРК, под воздействием УСов. Адрес формируется в БАКе. 2)--------3)Перед выборкой очередной команды производится анализ запроса на прерывание. Для этого включается БП. В состав ЦУУ включается блок для формирования исполнительных адресов – БПА. В его состав включаются: индексные, базовые регистры, а также схема алгебраического сложения. БТИ – Блок Тактовых Импульсов. Назначение формирование последовательности тактовых импульсов, которые позволяют провести временное развертывание цикла работы процессора. ИПУ – обеспечивает: а) пуск или остановку ЭВМ б) выполнение процессором заданного режима в) вывод на средства индикации
3. Основные характеристики и классификация устройств управления
1) Принцип формирования и развертывания временной последовательности УС для осуществления микроопераций цикла выполнения команд ЭВМ.
2) Способ построения цикла работы ЭВМ и ее ЦУУ:
3) Способ организации выработки УСов.
4) Способ синхронизации узлов и блоков ЭВМ. ЦУУ бывает аппаратного и микропрограммного типа. Последовательность УС зависит от операционной и адресной части исполняемой командыю Во-вторых – от сигналов от операционных блоков, все это синхронизируется ТИ, которые определяют границу тактов. Поэтому БУО рассматривается как цифровой автомат, который определяется следующими множествами: а) входных сигналов, которые соответствуют двоичному коду операционной части и двоичным значением сигналов осведомительных признаков. б) двоичных УСов, которое соответствует множеству выдаваемых из ЦУУ сигналов микроопераций. в) множество подлежащих реализации микропрограмм, циклов выполнения команд и отдельных этапов.
БУО в ЦУУ аппаратного типа представляет собой ЦА в котором требуемое множество состояний задается множеством логических и запоминающих элементов. Это позволяет выдать на выход блока сигнал микрооперации.
ЦУУ микропрограммного типа – БУО выполняет функции блока хранения и выборки кодов микропрограмм. В каждом машинном такте произодится выборка требуемой МК, во-вторых – выдача сигналов МО, в-третьих – формирование адреса следующей МК.
Различают ЦУУ:
1. С прямым циклом. 1) Выборка из устройства команд 2) выполнение машинной операции
2. С обращенным циклом. 1) Сигналы МО-ций для выполнения машинной операции по коду команды, которая поступила в ЦУУ в предыдущем цикле.
3. С совмещенным циклом – для повышения быстродействия – многокомандные процы, конвейрная и суперскалярная обработка
5) По способу выработки УС. ЦУУ могут быть централизованными и смешанными. В первом случае БУО вырабатывает все сигналы микроопераций для всех команд, а во втором – «местные» БУО.
6) По способу синхронизации работы ЭВМ – в зависимости от числа тактов в цикле команд различают ЦУУ с постоянным и переменным числом тактов.
4. Арифметико-Логическое Устройство (АЛУ)
Назначение – обработка информации (операции +, -, <<, >>, и т.д.) и логические операции. Кроме того в малых и средних машинах, в которых нету отдельного БУО, связ. с формированием действительных адресов в АЛУ выполняется действия адресной арифметики или действия связанные с преобразованием адресов. Алгоритм операции включает последовательность элем. действий: 1) прием кода операнда 2) преобразование кода операнда 3) суммирование кодов двух операндов 4) сдвиг кода операнда 5) выдача кода результата.
1) Регистры для хранения кодов операндов на время выполнения действий над ними
2) Регистры сдвига вправо/влево на один или несколько разрядов
3) Преобразователи для преобразования ПК в ОК или ДК.
4) Сумматор – для суммирования и других действий.
Самматоры делят по типу используемых для суммирования базовых элементов: 1) комбинационного 2) накапливающего и по способу осуществления 3) последовательнго и параллельного действия.
АЛУ ЭВМ малой производительности, сумматоры параллельного типа – средняя и высокая производительность (основа – совокупность Т-триггеров).
Алгоритм работы: 1) перед суммированием по шине сброс всех триггеров – уст. в 0 состояние (можно использовать парафазное представление)
2) на счетные входы триггеров подается первое слагаемое и запоминается
3) на входы триггеров подается второе слагаемое.
4) триггер, в котором слагаемое=1 изменяет свое состояние на противоположное
5) переполнение разрядной сетки выявляется в результате переноса из старшего разряда и знакового.
Быстродействие параллельного сумматора ограничивается временем распространения переноса.
Tпер=Т1(n~1). Для сокращения этого времени в сумматор включают цепь || переноса. В состав АЛУ входят: схема управления – руководство порядком выполнения последовательности микроопераций.
5. Назначение и классификация АЛУ
1) Виды обработки операндов
2) организация выполнения действий над операндами
3) способы связи между основными узлами
Типы АЛУ: 1) используемая система счисления
2) по формам представления числовых данных – с фиксированной или плавающей запятой.
3) по виду связей между основными узлами – с непосредственной связью и с магистральной структурой.
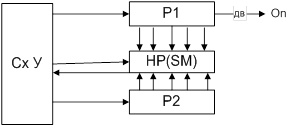
Принцип организации АЛУ с непосредственными связями:
сумматор и схема управления соединены непосредственно с выходами соответствующих регистров. Операнды считываются их определенных регистров. Результат определяется и передается также в определенные регистры.
АЛУ магистральной структуры: Схемы для преобразования информации выделены в отдельные блоки, включающие в себя сумматор и регистр сдвига. Регистры служат лишь для хранения операндов во время их обработки. Вх/вых сумм регистров содержат только схемы приема и выдачи информации.
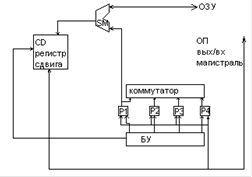
6. Структура АЛУ для сложения и вычитания чисел с фиксированной запятой
При выполнении сложения положительные слагаемые представляются в прямом коде, отрицательные – в дополнительном. Производится сложение двоичных кодов, включая разряды знаков. Если при этом возникает перенос из знакового разряда суммы при отстуствии переноса в этот разряд или перенос в знаковый разряд при отсутствии переноса из разряда знака, то имеется переполнение разрядной сетки соответственно при отрицательной и положительной суммах. Если нет переносов из знакового разряда и в знаковый разряд суммы или есть оба этих переноса, то переполнения нет и при 0 в знаковом разряде сумма положительна, а при 1 отрицательна и представленя в ДК.
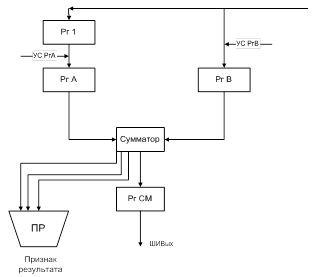
Алгоритм работы:
1) Из памяти по входной информационной шине в АЛУ поступают операнды, причем положительные числа – в прямом, а отрицательные – в дополнительном коде.
2) РгВ – первое слагаемое или уменьшаемое
3) РгА – второе слагаемое или вычитаемое. Рг1 связан с РгА цепями прямой и инверсной передачи кода. Прямая передача используется при сложении, инверсная - вычитания
4) Результат операции выдается из АЛУ в оперативную память по выходной информационной шине ШИВых. 5)При выполнении операции в АЛУ формируется 2-разрядный код признака результата ПР.
| Результат | Признак | результата |
| 0 | 0 | 0 |
| <0 | 0 | 1 |
| >0 | 1 | 0 |
| Переполнение | 1 | 1 |
6) Операция алгебраического вычитания Z=X-Y=X+(-Y) может быть сведена к изменению знака вычитаемого Y и операции алгебраического сложения. Изменение знака – принятый в Рг1 код инверсно передается в РгА и при сложении осуществляетя подсуммирование 1 в младший разряд сумматора.
7) Передача информации в регистрах АЛУ производится отдельными микрооперациями, инициируемыми соотвествующими УСами.
7. Структура АЛУ для умножения чисел с фиксированной запятой (сумматор частичных произведений)
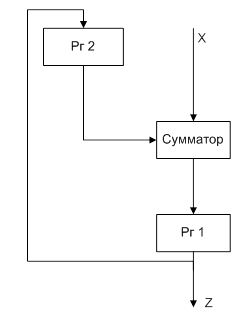
В ЭВМ операция умножения чисел с фиксированной запятой с помощью соответствующих алгоритмов сводится к операциям сложения и сдвига. Произведение двух (n-1)-разрядных чисел может иметь 2(n-1) значащих разрядов. Т.о. при операции умножения целых чисел необходимо предусмотреть возможность формирования в АЛУ произведения, имеющего двойную по сравнению с сомножителем длину. В ЭВМ, в которых числа с фиксированной запятой являются дробями, младшие n-1 разрядов произвдения часто отбрасываются (возможно с операцией округления).
Для выполнения умножения АЛУ должно содержать регистры множимого, множителя и схемы формирования суммы частичных произведений – сумматор частичных произведений, в котором путем соответствующей организации передач производится последовательное суммирование частичных произведений.
Операция умножения состоит из n-1 [(n-1) – число цифровых разрядов множителя] циклов. В каждом цикле анализируется очередная цифра множителя, и если это 1, то к сумме частичных произведений прибавляется множимое, в противном случае прибавления не происходит. Цикл завершается сдвигом множимого относительно суммы частичных произведений либо сдвигом суммы частичных произведений относительно неподвижного множимого.
8. Умножение начиная с младших разрядов множителя со сдвигом суммы частичных произведений вправо и при неподвижном множимом
Регистр множителя и сумматор частичных произведений при этом должны иметь цепи сдвига вправо. Регистр множимого может не иметь цепей сдвига. Последовательность действий в каждом цикле выполнения умножения определяется младшим разрядом регистра множителя, куда последовательно одна за другой поступают цифры множителя. Поскольку по мере сдвига множителя вправо старшие разряды регистра множителя освобождаются, он может быть использован для хранения младших разрядов произведения, поступающих из младшего разряда сумматора частичных произведений по мере выполнения умножения. Для этого при выполнении сдвига младший разряд регистра сумматора частичных произведений соединяется со старшим разрядом регистра множителя. После выполнения умножения старшие разряды произведения находятся в ргеистре сумматора, младшие – в регистре множителя. При данном методе умножения все три регистра имеют одинаковую длину, равную числу разрядов сомножителей. Этот метод нашел наибольшее применение в ЭВМ.
Алгоритм: 1. Берутся модули от сомножителей.
2. Исходное значение суммы частичных произведений принимается равным 0
3. Если анализируемая цифра множителя равна 1, то к сумме частичных произведений прибавляется множимое; если эта цифра 0, прибавление не производится.
4. Производится сдвиг суммы частичных произведений вправо на один разряд.
5. Пункты 3 и 4 последовательно выполняются для всех цифровых разрядов множителя, начиная с младшего.
6. Произведению присваивается знак плюс, если знаки сомножителей одинаковы, минус – в противном случае.
9. Умножение, начиная с младших разрядов множителя при сдвиге множимого влево и неподвижной сумме частичных произведений
Регистр множителя должен иметь цепи сдвига вправо, регистр множимого – влево, сумматор не должен иметь цепей сдвига. Последовательность действий определяется младшим битом регистра множителя. При этом методе регистр множимого и сумматор частичных произведений должны иметь двойную длину. Этот метод требует больше оборудования, но никаких преимуществ не дает, поэтому его применение нецелесообразно.
10. Умножение, начиная со старших разрядов множителя при сдвиге суммы частичных произведений влево и неподвижном множимом
Регистр множителя и сумматор частичных произведений должны иметь цепи сдвига влево. Регистр множимого не имеет цепей сдвига. Последовательность действий в каждом цикле выполнения умножения определяется старшим разрядом регистра множителя. При этом методе сумматор частичных произведений должен иметь двойную длину. И данный метод требует дополнительного по сравнению с первым методом оборудования. Но он применяется в некоторых АЛУ, т.к. позволяет без дополнительных цепей сдвига выполнять и деление (а при первом методе для выполнения деления необходимы дополнительные цепи сдвига влево в регистре множимого (частного) и в сумматоре частичных произведений (разностей).
11. Умножение, начиная со старших разрядов множителя при сдвиге вправо множимого и неподвижной сумме частичных произведений
Регистр множителя должен иметь цепи сдвига влево, регистр множимого – цепи сдвига вправо. Сумматор частичных произведений не имеет цепей сдвига. Последовательность действий на каждом шаге определяется старшим разрядом регистра множителя. При этом методе и регистр множимого, и сумматор частичных произведений должны иметь двойную длину. Однако, как и третий метод, он не требует дополнительных цепей сдвига для выполнения деления. Также в случае этого метода можно совмещать во времени операции сдвига и сложения и за этот счет увеличить быстродействие АЛУ при выполнении умножения (а также деления). Если необходимо образование произведения двойной длины (напр. при операциях с целыми числами), то наиболее экономичным является первый способ (т.к. все регистры одинарной длины). Если в результате умножения достаточно иметь произведение одинарной длины, то целесообразно использовать либо 1ый, либо 4ый метод умножения. При использовании 1го требуется введение дополнительных цепей сдвига для реализации деления, а при использовании 4го необходимо удлинение сумматора. При образовании произведений одинарной длины простое отбрасывание младших разрядов вносит погрешность, которая будет накапливаться, т.к. произведение всегда будет вычисляться с недостатком. Поэтому для повышения точности вычислений часто производят округление результата умножения, вследствие чего погрешность становится знакопеременной. Для округления длина сумматора увеличивается на 1 разряд. После образования произведения к этому дополнительному разряду добавляется 1. Если он был равен 0, то произведение получается с недостатком. Если был равен 1, то произведение получается с избытком. При этом максимальное значение погрешности равно половине 1 младшего разряда.
12. Методы ускорения умножения. Умножения на 2 разряда множителя
Классификация: 1) аппаратное 2) логическое (за счет развертывания процесса умножения во времени) 3) алгоритмическое (смешанные)
Устранение фиктивных операций сложения и объединение одноразрядных сдвигов в единые многоразрядные сдвиги.
Аппаратные методы развертывание процесса умножения в пространстве, за счет укрупнения блоков обрабатываемой информации и уменьшения числа этих блоков.
Эти методы вызывают усложнение схемы АЛУ и не затрагивают схемы управления. При реализации логических методов ускорения умножения усложняется в основном схема управления АЛУ.
Виды аппаратных методов ускорения умножения: 1) Ускорение выполнения операций + и >> (за счет элементной базы и технологии) 2) Введение дополнительных цепей сдвига, которые за один такт могут производить сдвиг информации в регистрах сразу на несколько разрядов. 3) Совмещенные по времени операции + и >>. Классификация логических методов ускорения умножения. В основе логических методов УУ лежит целенаправленный анализ цифр множителя. Этот анализ позволяет исключить из процесса умножения ряд микроопераций сложения и сдвига. Анализу подвергается или 1 разряд или 2-3-4. 1) Метод, позволяющий уменьшить количество сложений 2) количество сдвигов. Если при выполнении умножения в множителе встречается группа 1, то вместо сложений, число которых равно количеству единиц в группе можно выполнить одно сложение и одно вычитание. Выполнить следующее: 1) множитель сдвигается до появления первой единицы. 2) производится вычитание множимого и сдвиг множителя до появления первого нуля. 3) производится прибавление множимого и вновь сдвигается множитель до появления первой единицы.
1. Модифицированный метод. а) 0001000 Если две группы нулей разделены единицей, в К-той позиции, то вместо выполнения в К n сложений в K+1 позиции достаточно выполнить толко сложение в К-ой позиции. б) 1110111 – достаточно только вычитание в К-ой позиции.
2. Анализ двух разрядов множителя. Если пара 00, то производится простой сдвиг на два разряда вправо суммы частичных произведений. Если 01, то к сумме частичных произведений прибавляется одинарное множимое и сумма частичных произведений сдвигается на два разряда вправо. При 10 прибавляетя удвоенное множимое и сумма частичных произведений сдвигается на два разряда вправо. При 11 из суммы частичных произведений вычитается одинарное множимое и сумма частичных произведений сдвигается на два разряда вправо. При обработке следующей пары следует учесть, что при 11 на следующем шаге надо прибавить к сумме одинарное множимое.
13. Деление дробных чисел
Сводится к многократному вычитанию сначала из делимого, а потом из остатков (эти остатки умножаются на основание системы счисления – 10).
Сравнение величины модуля делимого и делителя, а впоследствии и остатков в ЭВМ производится с помощью операции вычитания (с помощью знака разности). Умножение делимого, а впоследствии остатков от деления на основание системы счисления осуществляется сдвигом исходного числа влево на 1 разряд. Z = X / Y. X – делимое, Y –делитель.
14. Деление целых положительных чисел
Делимое всегда берется двойным словом – 2n. Делитель – n. Модули операндов формируют n-1 разрядную сумму, часть частного и n-разрядный остаток со своим знаком. Знак остатка должен совпадать со знаком делимого. При большей величине модуля делимого и малой делителя – случай некорректного деления => перед началом необходимо провести проверку на корректность деления. Z=|X|/|Y| < 2^(n-1). Проверку можно совместить с первым шагом деления. |X|-2^(n-1)|Y|<0. Если результат пробного вычитания >0, то |Z|>=2^(n-1), и деление невозможно. Если <0, то можно выполнить деление.
Алгоритм деления с неподвижным делителем с восстановлением остатка:
1. Берутся модули от делимого и делителя.
2. Исходное значение частичного остатка полагается равным старшим разрядам делимого
3. Частичный остаток удваивается путем сдвига на один разряд влево, при этом в освобождающийся при сдвиге младший разряд частичного остатка заносится очередная цифра делимого.
4. Из сдвинутого частичного остатка вычитается делитель и анализируется знак результата вычитания.
5. Очередная цифра модуля частного равна 1, если результат вычитания положителен, и 0, если отрицателен. В последнем случае значение остатка восстанавливается до того, которое было до вычитания
6. Пункты 3-5 последовательно выполняются для получения всех цифр модуля частного.
7. Знак частного плюс, если знаки делимого и делителя одинаковы, и минус в противном случае.
Алгоритм без восстановления остатка:
4. Из сдвинутого частичного остатка вычитается делитель, если остаток положителен, и к сдвинутому частичному остатку прибавляется делитель, если остаток отрицателен.
5. Очередная цифра модуля частного равна 1, если результат вычитания положителен и 0 если отрицателен.
18. Классификация аппаратных средств многопроцессорных вычислительных комлпексов (МПВК) по Ф.Г. Энслоу
Общая шина
Перекрестная коммутация
Многовходовые ОЗУ
Ассоциативные
Матричные, векторные
С конвейерной обработкой.
19. МПВК с общей шиной
Физическая или логическая (опр. методы передачи инфы по проводам). Все устр-ва в ней. Связь только между двумя устройствами. Малонадежны, делают дополнительную шину, кот-ую можно использовать для ускорения работы. Дост. – простота выполнения, доступ всех модулей к ОЗУ. Низкое быстродействие и надежность.
20. МПВК с перекрестной коммутацией
Три вида: 1) сетка – к ней все подключено 2) к каждому процессору добавляется своя память
3) отделяются процессоры ввода-вывода, в дополнительную матрицу. Они соединяется через процессор ввода-вывода.
Достоинства: обмен инфой по нескольким путям, эфф. Скорость передачи выше чем в первом случае, отсутствие проблем при || работе процссорв, упрощ. интерфейсы, отст. Конфликтов., возможность установления связи на любое длит. время, нарушение к-л не влечет выход всей системы.
Недостатки – сложность наращивание, дороговизна комм. матрицы.
21. МПВК с многовходовыми ОЗУ
1) Коммутация устройств осуществляется в памяти
2) Модули памяти ОЗУ имеют число входов равное числу устройств, которое к нему подключается
3) Средства коммуникации распределены между несколькими устройствами
4) Для наращивания системы предусматривается дополнительные входы в память
Особенности:
1) Используется несколько путей передачи информации
2) Блоки ОЗУ должны быть снабжены логическими схемами для разрешения конфликтов – когда несколько внешних устройств требуют доступа к одному и тому же элементу.
3) Каждый модуль памяти должен идентифицировать и обрабатывать запросы на доступ к определенным ячейкам памяти. Максимально возможная конфигурация системы данного типа ограничена числом входов модулей памяти.
22. Ассоциативные вычислительные системы
Предпосылки их появления обработка информации, поступающей от многих датчиков, или систем слежения за многими объектами. Ассоциация – обработка данных может производиться не только обычными средствами, но и путем идентификации и выбора данных по их содержанию.
1) при приеме и размещении в памяти входного потока данных
2) реализация функций, связанных с перестроением данных.
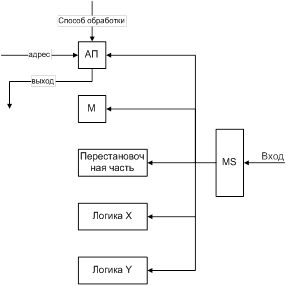
Достижение наивысшей степени параллелизма обработки возможно когда число обрабатываемых элементов равно числу слов.
23. Матричные вычислительные системы
Выполняют последовательно поразрядные арифметические и логические операции. Каждый элемент соединяется с 4-мя другими. ПЭ – Процессор и ОЗУ. Разрядность слов устанавливается программно. От УУ – команды управления и различные константы.
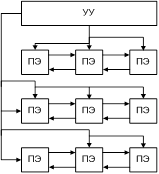
Многомодальная логика каждый ПЭ м.б. активным или пассивным.
25. Принципы векторной обработки
Векторная обработка увеличивает скорость и эффективность обработки за счет того, что обработка целого набора (вектора) данных выполняется одной командой. Скорость выполнения операций в векторном режиме приблизительно в 10 раз выше скорости скалярной обработки. Для фрагмента типа
Do i = 1, n
A(i) = B(i)+C(i)
End Do
в скалярном режиме потребуется сгенерировать целую последовательность команд: прочитать элемент B(I), прочитать элемент C(I), выполнить сложение, записать результат в A(I), увеличить параметр цикла, проверить условие цикла. В векторном режиме этот фрагмент преобразуется в: загрузить порцию массива B, загрузить порцию массива C (эти две операции будут выполняться со сдвигом в один такт, т.е. практически одновременно), векторное сложение, запись порции массива в память, если размер массивов больше длины векторных регистров, то повторить эту последовательность некоторое число раз.
Перед тем, как векторная операция начнет выдавать результаты, проходит некоторое время (startup), связанное с заполнением конвейера и подкачкой аргументов. Чем больше длина векторов, тем менее заметным оказывается влияние данного начального промежутка времени на все время выполнения программы.
Векторные операции, использующие различные ФУ и регистры, могут выполняться параллельно.
26. Факторы, снижающие производительность векторных ЭВМ. Возможность векторной обработки программ
Некоторый фрагмент программы может быть обработан в векторном режиме, если для его выполнения могут быть использованы векторные команды (соответственно полная или частичная векторизация). Поиск таких фрагментов в программе и их замена на векторные команды называется векторизацией программы. Для векторизации необходимы вектора-аргументы + независимые операции над ними. Кандидаты для векторизации - это самые внутренние циклы программы.
Пример. Нужно выполнить независимую обработку всех элементов поддиагональной части массива; в этом случае можем векторизовать по строкам, можем по столбцам, но не можем обработать все данные сразу в векторном режиме из-за нерегулярности расположения элементов поддиагональной части массива в памяти. Пример векторизуемого фрагмента, для которого выполнены все указанные условия:
Do i=1,n
A(i) = A(i) + s
EndDo
Пример невекторизуемого фрагмента (очередная итерация не может начаться, пока не закончится предыдущая):
Do i=1,n
A(i) = A(i-1)+s
End Do
Препятствия для векторизации
Препятствий для векторизации конкретного цикла может быть много, вот лишь некоторые из них:
Зависимость по данным (предыдущий фрагмент).
Отсутствие регулярно расположенных векторов:
Do i=1,n
ij = FUNC(i)
A(i) = A(i)+B(ij)
End Do
Присутствие цикла, вложенного в данный - для реализации такого фрагмента нет соответствующих векторных команд.
Вызов неизвестных подпрограмм и функций:
Do i=1,n
CALL SUBR(A,B)
End Do
29. Использование параллельных вычислительных систем. Закон Амдала
Предположим, что в вашей
программе доля операций, которые нужно выполнять последовательно, равна f, где
0<=f<=1 (при этом доля понимается не по статическому числу строк кода, а
по числу операций в процессе выполнения). Крайние случаи в значениях f
соответствуют полностью параллельным (f=0) и полностью последовательным (f=1)
программам. Так вот, для того, чтобы оценить, какое ускорение S может быть
получено на компьютере из 'p' процессоров при данном значении f, можно
воспользоваться законом Амдала: ![]()
Если 9/10 программы исполняется параллельно, а 1/10 по-прежнему последовательно, то ускорения более, чем в 10 раз получить в принципе невозможно вне зависимости от качества реализации параллельной части кода и числа используемых процессоров (ясно, что 10 получается только в том случае, когда время исполнения параллельной части равно 0).
Посмотрим на проблему с другой стороны: а какую же часть кода надо ускорить (а значит и предварительно исследовать), чтобы получить заданное ускорение? Ответ можно найти в следствии из закона Амдала: для того чтобы ускорить выполнение программы в q раз необходимо ускорить не менее, чем в q раз не менее, чем (1-1/q)-ю часть программы. Следовательно, если есть желание ускорить программу в 100 раз по сравнению с ее последовательным вариантом, то необходимо получить не меньшее ускорение не менее, чем на 99.99% кода, что почти всегда составляет значительную часть программы!
30. Конвейрная и суперскалярная обработка
Разработчики архитектуры компьютеров издавна прибегали к методам проектирования, известным под общим названием "совмещение операций", при котором аппаратура компьютера в любой момент времени выполняет одновременно более одной базовой операции. Этот общий метод включает два понятия: параллелизм и конвейеризацию. Хотя у них много общего и их зачастую трудно различать на практике, эти термины отражают два совершенно различных подхода. При параллелизме совмещение операций достигается путем воспроизведения в нескольких копиях аппаратной структуры. Высокая производительность достигается за счет одновременной работы всех элементов структур, осуществляющих решение различных частей задачи.
Конвейеризация (или конвейерная обработка) в общем случае основана на разделении подлежащей исполнению функции на более мелкие части, называемые ступенями, и выделении для каждой из них отдельного блока аппаратуры. Так обработку любой машинной команды можно разделить на несколько этапов (несколько ступеней), организовав передачу данных от одного этапа к следующему. При этом конвейерную обработку можно использовать для совмещения этапов выполнения разных команд. Производительность при этом возрастает благодаря тому, что одновременно на различных ступенях конвейера выполняются несколько команд. Конвейерная обработка такого рода широко применяется во всех современных быстродействующих процессорах.
Конвейеризация увеличивает пропускную способность процессора (количество команд, завершающихся в единицу времени), но она не сокращает время выполнения отдельной команды. В действительности, она даже несколько увеличивает время выполнения каждой команды из-за накладных расходов, связанных с управлением регистровыми станциями. Однако увеличение пропускной способности означает, что программа будет выполняться быстрее по сравнению с простой неконвейерной схемой.
31 Принципы управления внешними устройствами. Понятие интерфейса ввода-вывода
Производительность ЭВМ определяется:
1) Возможностями процессора (МГц) 2) емкостью ОЗУ
3) техническими данными устройств периферии 4) способом организации взаимодействия устройств с ЭВМ.
Особенности, которые надо учесть при разработке УВВ:
1) Возможность реализации машин с переменным составом оборудования
2) Возможность одновременной работы процессора по заданной программе и выполнения перифириыйными устройствами процедур ввода-вывода.
3) Необходимость упростить операции ввода-вывода
4) Обеспечение возможности автоматического распознавания ситуаций в перифирийных устройствах.
Три вида средств для обеспечения интерфейса:
1) специальные управляющие сигналы и их последовательности
2) устройства сопряжения
3) физическая среда передачи данных (каналы связи)
4) программы, реализующие обмен данными.
Интерфейс – комплекс линий и шин, сигналов, электр. схем, алгоритмов и программ.
32. Типы интерфейсов
Деление в зависимости от типов соединяющих устройств. Различают:
1) внутренний интерфейс (системная шина, и т.п.)
2) интерфейс ввода-вывода (сопряжение с внешними устройствами)
3) интерфейсы межмашинного обмена (вычислительные сети)
4) интерфейса человек-машина.
33. Управление обменом данными
Классифицируется на основе участия ЦП в обмене.
Три способа управления обменом:
1) режим сканирования/асинхронный обмен
2) синхронный обмен
3) прямой доступ к памяти (DMA или ПДП)
1. Асинхронный режим. Суть: Опрос ЦП-ом перифирийного устройства. Такой режим снижает производительность ЭВМ. При большом быстродействии перифирийного устройства процессор может не успеть организовать обмен данными.
2. Синхронный режим. Процессор выполняет основную роль по организации обмена. Но когда устройство занято, то он выполняет другие операции. При наступлении сбоя – вызов прерывания.
3. DMA. Установка связи и передача данных между основной памятью и внешними устройствами – контроллер прямого доступа к памяти. Программирование DMA-контроллера: 1) В него передаются адреса основной памяти и количество передаваемых данных
2) ЦП от DMA-контроллера отключается, и может выполнять другую работу
3) Об окончании обмена контроллер сообщает процессору.
ПДП обеспечивает выполнение следующих функций: 1) освобождение процессора от управления операциями ввода-выводаю 2) позволяет параллельно организовать выполнение программы и ввод-вывод.
34. Понятие подхода открытых систем. Свойства открытых систем
Открытые системы – основа развития информационных технологий сегодня. ОС – это система, которая состоит из компонент, взаимодействующих через стандартные интерфейсы. Общие свойства ОС: 1) Расширяемость/масштабируемость 2) portability/мобильность
3) interoperability (способность взаимодействия с другими системами)
4) driveability – легкость управления
35. Профили стандартов открытых систем
Интеграция в открытые системы должна соответствовать профилям стандартов ОС (на интерфейсы). Профиль это набор согласованных стандартов, интерфейсов, компонентов на каждом уровне системы. Данный набор обеспечивает совместимость этих компонентов.
Структура ОС содержит 5 групп компонентов:
1) управление/менеджмент (системное администрирование, безопасность, управление ресурсами, конфигурация, сетевое управление)
2) пользовательский интерфейс
3) системные интерфейся для программ – это интерфейсы между прикладными программами и между прикладными программами и операционной системой.
4) формат информации и данных
5) интерфейсы коммуникаций
Европейская рабочая группа предлагает 6 стандартов:
1) Среда рабочих станций
2) Среда серверов процессов
3) Среда серверов данных
4) Среда транзакций
5) Среда реального времени
6) Среда суперкомпьютера
Кроме этого существует необходимость формирования вертикальных профилей, которые ориентированы на область применения. Наша классификация ОС: (профилей)
1) Интегрированные производственные системы
2) Информационные системы с … доступом к ресурсам
3) Системы автоматизации учреждений
4) Системы автоматизации банков
5) Системы научных исследований (САПР)
6) Определение систем связи и передачи данных
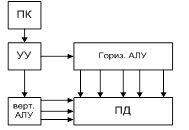
Машина № 3
Объединение 1ой и 2ой машин. Ортогональная машина. Память данных – и пословно и поразрядно.
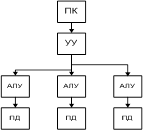
Машина № 4
За основу берется машина 1 и увеличивается число пар АЛУ-ПД.
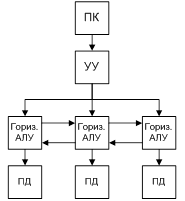
Машина № 5
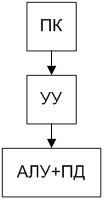
Машина № 6 (машина с функциональной памятью)
Эта машина построена по другому принципу – распределенная логика процессора по всему запоминающему устройству.
36. Архитектура открытых систем
Архитектура ОС является иерархическим описанием ее внешнего облика и каждого компонента.
1) интерфейс 2) учет интересов проектировщика системы 3) учет интересов системного программиста 4) учет интересов разработчика аппаратуры интерфейса оборудования, составляющего архитектуру типовых средств. В данное понятие входит: 1) Система команд процессора
2) Организация памяти 3) Ввод-вывод 4) Физическая реализация системной шины, шин памяти, интерфейсы внешних устройств, физический уровень передачи данных и физический уровень среды хранения.
Значение идеологии открытых систем состоит в том, что данная идеология открывает путь к унификации всех интерфейсов, протоколов взаимодействия между родственными устройствами для всего класса систем (открытых систем).
37. Преимущества идеологии открытых систем
1) Новые возможности сохранения сделанных вложений благодаря свойствам эволюции – замена отдельных узлов без перестройки системы.
2) Освобождение от зависимости от одного поставщика
3) Дружественность среды, в которой работает пользователь
4) Возможность использования информационных ресурсов другой организации.
Проектировщик получает:
1) Возможность использования различных аппаратных платформ
2) Возможность совместного использования прикладных программ, реализованных в различных операционных системах
3) Развитые средства поддержания проектировщика
4) Использовать готовые программные и информационные ресурсы
Разработчики общесистемных программных средств получает:
1) Новые возможности разделения труда благодаря повторному использованию программ.
2) Развитые инструментальные среды и системы программирования
3) Возможности модульной организации программных комплексов
38. Открытые системы и объектно-ориентированный подход
Суть ООПодхода: 1) Данные и процедуры объединены в объекты
2) Для связи объектов используется механизм посылки сообщений
3) Объединения в класс объектов с похожими свойствами
4) Объекты используют свойства других объектов через …. Класса
Особенности:
1) Инкапсуляция свойства ООС. Данные и процедуры скрываются от внешнего. Связь с объектами организуется набором сообщений
2) Полиморфизм (многозначность сообщений) – одинаковые сообщения по разному интерпретируются разными объектами (в зависимости от класса объекта)
3) Позднее связывание. Имя становится известно только во время выполнения программы.
4) Абстрактные типы данных. Объединение данных и определений для описания новых типов позволяет использовать новые типы наравне с существующими.
5) Наследование. Позволяет при создании новых объектов использовать свойства уже существующих.
Свойства:
1) Мобильность инкапсуляция – позволяет скрыть машинно-зависимые части системы, которые должны быть реализованы заново при переходе на другие платформы. Гарантируется, что остальная часть системы не потребует изменений.
При реализации многое может быть взято из уже существующей системы, благодаря наследование.
2) Расширяемость наследование, абстрактные типы данных. Позволяет сэкономить средства на создание системы, используя уже отлаженные компоненты – надежность.
Возможность конструирования абстрактных типов данных обеспечивается самим понятием классов, которые объединяют похожие объекты с одним набором операций.
3) Интероперабельность полиморфизм, динамическое связывание. Сообщение объекту передается используя действия и некоторые дополнительные аргументы сообщения. Как это сделать знает только сам объект – получатель сообщения.
4) Дружественность мобильность необходима для смены старых устройств.
Расширения требуются для разработки программных способов общения человека с машиной.
39. Вычислительные системы. Назначение. Принципы построения. Признаки структурной и функциональной организации
Параллельные вычислительные процессы – конвейеризация, векторные вычислительные процессы, параллелизм.
Построение вычислительных систем: 1) Возможность работы в различных режимах 2) модульная структура 3) стандартизация 4) иерархия 5) адаптация 6) сервис
Структура ЭВМ ВС совокупность компонентов и связей между ними. Архитектура ЭВМ – организация ЭВМ.
Функциональная классификация:
1) по назначению универсальные и специализированные.
2) многомашинные и многопроцессорные
Основная особенность параллельная работа процессоров и использование общей оперативной памяти обеспечивается единой общей ОС.
Недостатки: 1) возникновение конфликтов 2) применение коммутаторов.
3) по типу ЭВМ или процессоров – однородная или неоднородная
4) по степени территориальной разобщенности – совмещенные и распределенные
5) по типу управления централизованное и децентрализованное управление
6) системы с жестким закреплением или с плавающим
7) по режиму работы оперативный или неоперативный
40. Классификация архитектур вычислительных систем. Классификация Флинна
В основе два возможных вида параллелизма: независимость потоков заданий или команд и независимость данных, обрабатываемых в каждом потоке.
I instruction, D – data, S – Sole, M – Multiple.
1) SISD – один поток команд и данных (ОКОД). Совмещение выполнения операций отдельными блоками АЛУ, а также параллельная обработка работы устройств ввода-вывода и процессора. Однопроцессорная ЭВМ.
2) SIMD (ОКМД)
Матричная структура. Система содержит некоторое число одинаковых сравнительно простых быстродействующих процессоров, соединенных друг с другом и с памятью данных регулярным образом так, что образуется сетка (матрица), в узлах которой размещаются процессоры. В системе имеется несколько потоков данных и один общий поток команд, т.е. все процессоры выполняют одновременно одну и ту же команду (допускается пропуск выполнения команды в отдельных процессорах), но над разными операндами, доставляемыми процессорам из памяти несколькими потоками данных. Другое название – системы с общим потоком команд. Возникает сложная задача распараллеливания алгоритмов решаемых задач для обеспечения загрузки процессоров. В ряде случаев эти вопросы лучше решаются в конвейрной системе.
3) MISD (МКОД)
Конвейрная МПС. Система имеет регулярную структуру в виде цепочки последовательно соединенных процессоров, так что информация на выходе одного процессора является входной для другого. Процессоры образуют процессорный конвейер. На вход конвейера одинарный поток данных доставляет операнды из памяти. Каждый процессор обрабатывает соответствующую часть задачи, передавая результаты соседнему процессору, который использует их в качестве исходных данных. Т.о. решение задач для некоторых исходных данных развертывается последовательно в конвейрной цепочке. Это обеспечивается подведением к каждому процессору своего потока команд, т.е. имеется множественный поток команд.
4) MIMD (МКМД)
Общий случай МПС, несколько потоков данных и команд.
41. Классификация Шора
1) Количество устройств управления
2) Количество АЛУ
3), 4) наличие и способ организации памяти команд и памяти данных.
Предполагается, что выборка данных может осуществляться двумя способами: словами или вертикальной выборкой.
Существует 6 машин.
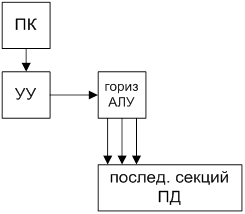
Машина № 1.
Последовательная обработка слов при параллельной обработке разрядов. Считывание данных осуществляется выборкой всех разрядов данного слова. 1) Классические последовательные машины 2) конвейрно-скалярные 3) векторно-скалярные.
Машина № 2
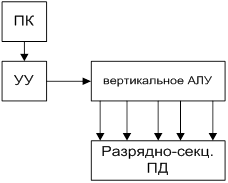
Последовательная обработка битовых слоев при параллельной обработке множества слов.
Матричные машины.
42. Параллельные вычислительные системы. Основные классы современных параллельных вычислительных систем
Основные классы:
Massive Parallel Processing
Symmetrical MultiProcessing
Кластерные системы
Non-Uniform Memory Access
Parallel Vector Processing
43. Способы доступа к модулям памяти параллельных компьютеров
1) Имеет ли каждый процессор локальную память?
2) Соединяет ли коммуникационная сеть все процессоры с общей памятью?
Способы:
1. Распределенная память. Система обмена сообщениями – только с помощью неё доступ к чужой локальной памяти.
2. Общая память возможность прямого доступа к общей памяти посредством общей шины (высокоскоростной сети).
3. Виртуальная память «Глобальных адресов».
44. Современное состояние параллельных вычислительных технологий
Основных направлений развития высокопроизводительной вычислительной техники в настоящее время четыре. 1. Векторно-конвейерные компьютеры. Конвейерные функциональные устройства и набор векторных команд - это две особенности таких машин. В отличие от традиционного подхода, векторные команды оперируют целыми массивами независимых данных, что позволяет эффективно загружать доступные конвейеры, т.е. команда вида A=B+C может означать сложение двух массивов, а не двух чисел. Характерным представителем данного направления является семейство векторно-конвейерных компьютеров CRAY. 2. Массивно-параллельные компьютеры с распределенной памятью. Идея построения компьютеров этого класса тривиальна: возьмем серийные микропроцессоры, снабдим каждый своей локальной памятью, соединим посредством некоторой коммуникационной среды - вот и все. Достоинств у такой архитектуры масса: если нужна высокая производительность, то можно добавить еще процессоров, если ограничены финансы или заранее известна требуемая вычислительная мощность, то легко подобрать оптимальную конфигурацию и т.п. Однако есть и решающий "-", сводящий многие "+" на нет. Дело в том, что межпроцессорное взаимодействие в компьютерах этого класса идет намного медленнее, чем происходит локальная обработка данных самими процессорами. Именно поэтому написать эфф. прогу для таких компьютеров очень сложно, а для некоторых алгоритмов иногда просто невозможно. К данному классу можно отнести компьютеры Intel Paragon, IBM SP1, Parsytec, в какой-то степени IBM SP2 и CRAY T3D/T3E, хотя в этих компьютерах влияние указанного минуса значительно ослаблено. К этому же классу можно отнести и сети компьютеров, которые все чаще рассматривают как дешевую альтернативу крайне дорогим суперкомпьютерам. 3. Параллельные компьютеры с общей памятью. Вся оперативная память таких компьютеров разделяется несколькими одинаковыми процессорами. Это снимает проблемы предыдущего класса, но добавляет новые - число процессоров, имеющих доступ к общей памяти, по чисто техническим причинам нельзя сделать большим. В данное направление входят многие современные многопроцессорные SMP-компьютеры или, например, отдельные узлы компьютеров HP Exemplar и Sun StarFire. 4. Последнее направление, строго говоря, не явл-я самостоятельным, а скорее представляет собой комбинации предыдущих трех. Из нескольких процессоров (традиционных или векторно-конвейерных) и общей для них памяти сформируем вычислительный узел. Если полученной вычислительной мощности не достаточно, то объединим несколько узлов высокоскоростными каналами. Подобную архитектуру называют кластерной, и по такому принципу построены CRAY SV1, HP Exemplar, Sun StarFire, NEC SX-5, последние модели IBM SP2 и другие. Именно это напр-ие явля- в настоящее время наиболее персп-м для конструирования компов с рекордными показателями производительности.
45. MPP-архитектура
Massive Parallel Processing (Массивно-параллельные системы). Архитектура: состоит из однородных вычислительных узлов, у каждого – своя локальная память, каждый узел включает один или несколько ЦП, в большинстве случаев – RISC. Прямой доступ к памяти других узлов невозможен.
Узел: 1) ЦП 2) локальная память 3) коммуникационный процессор 4) жесткие диски
Можно выделить специальные узлы ввода-вывода, управляющие узлы. Масштабируемость – до нескольких тысяч. Полноценная ОС работает только на управляющей системе (машине) – front end, а на других – урезанный вариант её же.
Модель программирования. MPP имеют более скоростные и более специализированные каналы связи между вычислительными узлами. В MPP фиксирован достаточно высокий уровень интерфейса прикладных программ. Характерное требование к системе: малая задержка, возможность совмещения передачи с вычислением, базирование на стандартах, поддержка различных топологий.
Особенности:
1) Сложность отдельных процессоров 2) Значительное увеличение числа параллельно работающих потоков 3) свойства по автоматическому обнаружению неисправностей и т.о. продолжение вычислений при выходе из строя отдельного процессора или потока.
46. SMP-архитектура
Symmetrical Multiprocessing. Архитектура: несколько однородных процессоров и массив общей памяти. Масштабируемость – не более 32-х процессоров. Наличие общей памяти упрощает взаимодействие между собой. Для построения масштабируемых систем на базе SMP используются кластерные или номо-архитектуры. ОС вся система работает под управлением одной ОС (обычно Unix-подобной).
47. PVP-архитектура
Parallel Vector Processing. (SIMD). Присутствуют конвейерные процессы. Команды однотипной обработки. Работает в рамках МП объединенных посредством коммутатора. Векторизация циклов, распараллеливание.
48. Кластерные системы
Архитектура – набор персональных компьютеров. Для связи – стандартная сетевая архитектура. Могут одновременно использоваться в качестве рабочих мест/станций. Модель программирования: В рамках модели передачи сообщений MPI. Недостаток: большие накладные расходы на взаимодействие параллельных процессов.
Особенности:
1) Компоновка кластерных систем из компонентов высокой готовности
2) Построение на основе стандартных программно-аппаратных решений, которые поддерживают общую систему имен и возможностей доступа.
3) Согласованность наборов прикладных программ.
4) Общая для всех модулей организация ИБ
5) Общий алгоритм обнаружения неисправностей
6) Общий алгоритм реконфигурации системы при обнаружении ошибки
Коммутатор мультиплексор. Область использования – мини- и микро- ЭВМ с непосредственными связями.
4) по характеру использования элементов и узлов: а) блочные б) многофункциональные АЛУ.
Блочное – операции над числами с фиксированной и плавающей запятой (двоичными) и над десятичными числами выполняются в отдельных блоках.
Многофункциональное одни и те же элементы коммутируются в зависимости от требуемого режима работы.
Функциональная схема АЛУ:
Регистры разделены на части, которые могут объединяться. Конфигурация определяется типом операции.
Суть многофункционального АЛУ – для всех форм представления числовой информации операции выполняются одними и теми же схемами, но которые конфигурируются в зависимости от режима работы. Эти части объединяются элементами И в той конфигурации, которая определена видом выполняемой операции. Пример – выполнение операции над числами с фиксированной запятой. Сумматор – на две части, в первой мантисса, во 2ой над порядками. И1 – разделяет. Применяется в машинах малой и средней производительности, позволяет сэкономить аппаратные средства.
АЛУ блочного типа высокопроизводительные ЭВМ –
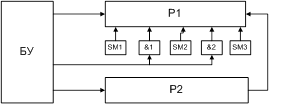
могут параллельно выполнять операции над информацией.
Обобщенная схема АЛУ:
ГрРг – группа регистров прием и размещение операндов
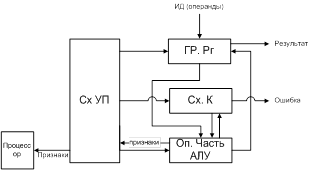
ОпЧАЛУ – Операционная часть АЛУ – преобразование операндов согласно заложенного в машине алгоритма
Сх.К – схема контроля Сх.УП – формирование управляющих сигналов (УСов). Координация взаимодействия всех блоков АЛУ между собой, а также с другими блоками ЦП. Замечания: 1) ГрРг как правило связана с ОЗУ и м.б. ПЗУ, а также м.б. связана с регистрами общего назначения ЦП. 2) Количество регистров в блоке и их разрядность широко варьируется.
6) По способу организации работы – асинхронные и синхронные. В асинхронных АЛУ ожидается фактическое окончание операции, после этого начинается следующая операция. В синхронных АЛУ на выполнение отдельной операции отводится фиксированное время.
49. MBC-архитектура
Многопроцессорная вычислительная машина с массивно-параллельной архитектурой. Принципы построения: 1) По модульному принципу. 2) Структурная единица вычислительный модуль из стандартных промышленных компонент. 3) Состав вычислительного модуля – вычислительный процессор и коммуникационный процессор. Взаимодействуют через разделяемую память.
4) Каждый модуль имеет собственную память (локальная память)
5) Количество модулей от 10 до 1000
Применение – большой спектр задач и большой параллельный сервер БД.
50. NUMA-архитектура
Non-Uniform Memory Access. Состав: однородные базовые модули, небольшое число процессоров и блок памяти. Модули объединяются между собой с помощью коммуникационной сети. Поддерживает единое адресное пространство. Аппаратно поддерживает доступ к удаленной памяти. Масштабируемость: Ограничена объемом адресного пространства, возможностями аппаратуры, возможностями ОС по управлению процессорами. Максимум – 256 процессоров. Обычно под управлением единой ОС.
© 2010 Интернет База Рефератов