
Рефераты по сексологии
Рефераты по информатике программированию
Рефераты по биологии
Рефераты по экономике
Рефераты по москвоведению
Рефераты по экологии
Краткое содержание произведений
Рефераты по физкультуре и спорту
Топики по английскому языку
Рефераты по математике
Рефераты по музыке
Остальные рефераты
Рефераты по авиации и космонавтике
Рефераты по административному праву
Рефераты по безопасности жизнедеятельности
Рефераты по арбитражному процессу
Рефераты по архитектуре
Рефераты по астрономии
Рефераты по банковскому делу
Рефераты по биржевому делу
Рефераты по ботанике и сельскому хозяйству
Рефераты по бухгалтерскому учету и аудиту
Рефераты по валютным отношениям
Рефераты по ветеринарии
Рефераты для военной кафедры
Рефераты по географии
Рефераты по геодезии
Рефераты по геологии
Рефераты по геополитике
Рефераты по государству и праву
Рефераты по гражданскому праву и процессу
Рефераты по делопроизводству
Рефераты по кредитованию
Рефераты по естествознанию
Рефераты по истории техники
Рефераты по журналистике
Рефераты по зоологии
Рефераты по инвестициям
Рефераты по информатике
Исторические личности
Рефераты по кибернетике
Рефераты по коммуникации и связи
Учебное пособие: Адресное пространство. Подсистемы ввода-вывода
Учебное пособие: Адресное пространство. Подсистемы ввода-вывода
Железо
Процессоры
Типы процессоров:
1. с регистрами общего назначения (РОН);
2. аккумуляторные;
3. стековые.
Процессоры с РОН
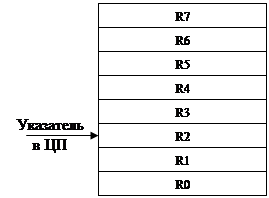
Любой регистр как операнд может участвовать в любой команде. Работа с операндами осуществляется только через регистры. Среди всех регистров выделяются два:
SP - указатель стека
PC - счетчик команд
Нет команд push и pop, всегда используется mov:
mov (SP)+,R0 вместо pop R0
mov R0,-(SP) вместо push R0
Вместо непосредственной загрузки константы в регистр (mov #5,R0) используется:
mov (PC)+,R0
db 5
PC может использоваться как универсальный регистр во всем множестве команд ЦП. PC используется и при выборке команды и при ее исполнении.
Конвейеризация сильно затруднена.
Недостаток: большой размер команд, т.к. много операндов, много типов адресации.
Можно уменьшить оперативность инструкций и упростить внутреннюю топологию ЦП.
Процессоры аккумуляторного типа
При любой операции один из операндов всегда находится в аккумуляторе и результат всегда помещается в аккумулятор. Непосредственно обратиться к PC и SP уже нельзя, но этого и не требуется.
Процессоры стекового типа
У них стек регистров. Система команд не позволяет непосредственно адресовать регистры. При выполнении операции из вершины стека снимаются операнды и кладется результат.
 |
Имеется стандартный набор команд:
- ADD
- SUB
- MUL
- DIV
- и т.д.
и еще дополнительные (только они работают с операндами в памяти):
- LOAD – помещение данных из памяти в верх стека
- STORE – перемещение данных с верха стека в память
Параметры ЦП
Разрядность ЦП – разрядность его регистров.
Во время выполнения инструкции состояние процессора не определено, оно становится строго определенным после завершения выполнения текущей инструкции.
В качестве операндов кроме данных в АЛУ поступают и адреса, следовательно, разрядность ЦП прямо определяет размер адресного пространства.
Архитектуры ЦП
Скалярная.
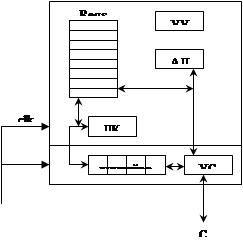
ЦП делится на две секции, каждая из которых независимо тактируется одним тактовым генератором.
Идея: АЛУ не должно простаивать, пока идет выборка команды из памяти.
Выборка инструкции происходит параллельно с работой АЛУ. Для этого используется конвейер.
Суперскалярная.
Несколько АЛУ и каждое занимается своим делом. Добавляется АЛУ для вычисления адресов. Несколько команд могут выполняться одновременно. Возникает проблема, когда команда, стоящая в памяти дальше, выполняется быстрее. Выход – механизм замещения регистров: используются копии регистров для хранения результатов.
Принцип параллельности команд – независимость операндов, т.е. если у команд есть общий операнд – они не параллельны. Если в инструкциях операнды в памяти, то трудно проверить, пересекаются ли они – процессор считает такие команды не параллельными. Процессор оперирует относительными адресами в адресном пространстве процесса, которые дал компилятор и линковщик. Два адреса могут указывать на одно место в физической памяти и два одинаковых адреса – на разные участки физической памяти.
Архитектура RISC.
Запрещает использовать методы адресации во всех инструкциях, кроме load и store. Все мнемонические команды остаются (они необходимы всем ЦП).
add R0,R1 команды почти одинаковы с точки
sub R0,R1 зрения внутренней топологии
add R0,R1 эти сильно
add R0,(R1) отличаются
Запретив команды add R0,(R1) существенно меняем набор команд.
Таким образом, можно максимально сгруппировать команды загрузки из/в память. Еще надо побольше регистров (лучше несколько десятков).
Рост быстродействия RISC колоссален, по сравнению с CISC (если еще использовать кэш для ОП и сгруппировать обращения к ОП вместе).
Адресное пространство
Существует два типа адресных пространств:
- Логическое АП этими адресами оперирует ЦП (разрядность ЦП)
- Физическое АП этот адрес выставляется на шину.
В общем случае ЛА и ФА – разные.
ЦП не может сгенерировать адрес, выходящий за пределы его разрядности. Для памяти нужен ФА большой разрядности.
Возникает две проблемы:
1. Сделать физическую память разрядности больше разрядности ЦП.
2. Если увеличить разрядность ФА, тогда не хватит физической памяти, что делать? (Например, 32-разрядный процессор позволяет каждому процессу иметь ЛАП 4Гб, но где взять столько физической памяти)
Пусть ЛАП < ФАП.
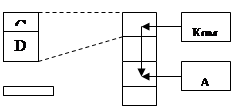 |
Тогда нужен отдельный базовый регистр для кода – CS. Следовательно, ЦП должен выдавать Устройству Сопряжения с Шиной какой-то признак вместе с операцией, чтобы УСШ знало, какой базовый регистр использовать.
Все операции работы с памятью используют CS, если выбирается код, и DS, если выбираются данные.
 |
Недостатки данной схемы: сегменты могут налезать друг на друга, программа сама заполняет сегментные регистры, следовательно, ей доступна вся память.
Страничное преобразование
Все логическое адресное пространство делится на страницы фиксированного размера. Все физическое адресное пространство делится на страницы того же размера.
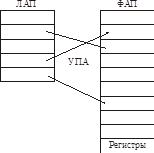
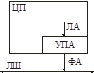
УПА = Устройство Преобразования Адреса. УПА может добавлять к смещению произвольный базовый адрес страницы.

Таблицу страниц можно (и нужно) вынести за пределы ЦП.
В таком случае получаем диспетчер памяти (ДП) вместо УПА.
Сегментная организация памяти

Нужно частично размещать программу в памяти (?) – существуют два метода: страничный и сегментный метод организации памяти.
Вся память делится на сегменты произвольной длины. Каждый сегмент характеризуется базовым адресом и смещением.
Надо выделять физическую память сегменту (половинке – нельзя (?)).
УПА преобразует логический адрес в физический:
В Intel-процессорах имеется набор базовых регистров – CS, DS, SS, ES, GS, FS.
Для идентификации сегментов используются не их логические адреса, а их логические номера.

Дескрипторная таблица (ДТ)
Дескриптор: адресная часть (содержит базовый адрес сегмента в физической памяти) и дескрипторная часть (?) (содержит сведения о защите + длину + бит присутствия).
ДТ находится в оперативной памяти.
При обращении к байту каждый раз производится преобразование адреса + контроль выхода за границу сегмента + права доступа. Т.е., чтобы прочитать байт, нужно два обращения к памяти – так нельзя, нужно кэшировать дескрипторы!
![]()
Дескриптор загружается в скрытую часть сегментного регистра каждый раз, когда в сегментный регистр загружается нами номер сегмента. Далее - проверка выхода и прав доступа. В разных режимах работы ЦП используется один режим адресации. Скрытые части базовых сегментных регистров фактически выполняют функцию кэшей!
Недостатком данного метода является переменная длина сегментов, трудно организовать загрузку/выгрузку сегментов. Возникает фрагментация памяти.
Страничная организация памяти
Если все блоки (которые меняются) имеют один и тот же размер, исчезает фрагментация 1-го уровня. (Однако есть фрагментация 2-го уровня блоки одного сегмента «разбегаются» по памяти).
Это и есть механизм страничной организации памяти.
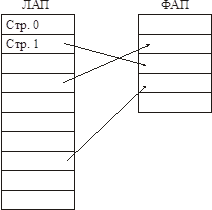
ЛАП и ФАП делится на страницы фиксированного размера.
ТСП (таблица страничного преобразования) – это вектор, содержащий дескрипторы для страниц. Тут должны быть описаны все страницы ЛАП-ва. В дескрипторе страниц есть бит присутствия (есть ли страница в памяти или она на диске).
Если происходит обращение к странице, отсутствующей в памяти происходит страничное прерывание.
Существует два типа исключений: прерывание и ловушка.
В первом случае управление возвращается на ту же инструкцию, которая вызвала исключение (специально для того, чтобы можно было, загрузив недостающую страницу, повторить эту операцию). В другом – управление возвращается на инструкцию, следующую за вызвавшей исключение.

Таблица страниц каждого процесса занимает 4 Мб (?), она должна быть резидентна в памяти – это не допустимо.
Применяется 2-х уровневая система.
Каталог страниц (КС) состоит из одной физической страницы, он обязательно резидентен.
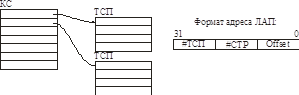
На одну операцию чтения байта потребуется три (!!!) обращения к памяти – Ужас!
Нужен кэш. Кэшируются все данные, с которыми работает ЦП (логическое кэширование не годится, нужно универсальное). Чаще всего происходит обращение к ТСП, они и будут занимать большую часть кэш.
Тогда буфер трансляции адреса (TLB) – используется только для адресных преобразований. А кэш данных – только для кэширования данных (хотя, в некоторых ЦП используется только один кэш – в расчете на то, что в нем в основном будет оседать ТСП).
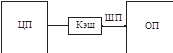
Любое обращение к памяти происходит через кэш.
Кэш никогда не обменивается байтами или словами. Обращаясь к байту, кэш считывает целый блок (например, 128 бит в случае 128-разрядной шины).
Понятие интерфейса
Интерфейс – это правила перехода границы (т.е. правила, по которым граница может быть пересечена).
Типы интерфейсов:
- Физический интерфейс – правила, описывающие механические характеристики подключения ВУ.
- Электрический интерфейс – определяет величины напряжений, токов и нагрузок, которые должны выполняться при подключении.
- Логический интерфейс – определяет последовательность во времени сигналов (оперирует логическими понятиями 0 и 1, а не вольтами).
- Программный интерфейс – описывает как интерпретировать значения регистров в процессе управления устройством.
Логический интерфейс системной шины
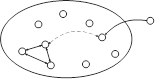
Системная шина нужна для объединения узлов ВС.
Связь между каждыми двумя узлами может быть специализированна для этих двух узлов.
Добавление еще одного узла приводит к нехилому увеличению числа связей.
Жертвуем оптимальностью, так, что сложность связей не зависит от сложности системы. Появляется шинный интерфейс.
Оптимальность этого интерфейса будет логарифмически падать с ростом числа устройств и различием между ними.
Виды интерфейсов
Интерфейс «общая шина» (UNIBUS)

Реализовано в PDP-11 (DEC).
Максимально универсальна.
Этот интерфейс предполагает, что все устройства примерно одинаковы. Вывод идет со скоростью «самого медленного солдата» - все определяется самым медленным устройством.
Шина ISA
ISA (Industry Standard Architecture) – применяется с первых моделей PC.
ISA-8 (8 бит данных и 20 бит адреса) и ISA-16 (16 бит данных и 24 бит адреса).
Частота системной шины – до 8 МГц.
Существует расширение до 32 бит – EISA (совместима, для режима EISA используются специальные управляющие сигналы) – 32 бит адрес и данные, частота до 33 МГц.
Шина PCI
PCI (Peripheral Component Interconnect) – локальная шина, являющаяся мостом между шиной процессора и шиной ввода/вывода ISA/EISA.
Разрядность данных – 32/64 бит. Разрядность адреса – 32 бит. Частота – 33/66 МГц.
Шина является синхронной.
На ее базе существуют расширения (например AGP).
Шина VLB
VLB (VESA Local Bus) – использует шину процессора для подключения периферии (графический адаптер, контроллеры дисков и т.д.).
32-битная шина (32/64 – данные, 32 адрес), частота колеблется от 33 до 50 МГц.
Шина MassBus
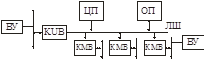
MassBus – высокоскоростная синхронная блочная шина.
Использовалась на VAX-11 (DEC).
В многошинных интерфейсах некоторые узлы выведены из-под управления общей шины.
Интерфейс системной шины. Асинхронная шина
Инициатор – ЦП. Взаимодействие происходит с одним устройством.
Любое устройство – дешифратор адреса (ДША). Обладает диапазоном адресов.
Вводится специальный таймаут для проверки существования адреса.
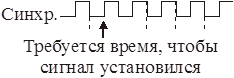
Среагировать на изменение сигнала можно в лучшем случае на следующем такте, т.к. триггеры переключаются не мгновенно.
Синхронная шина
К ней могут подключаться только те устройства, которые соответствуют ее временным характеристикам.
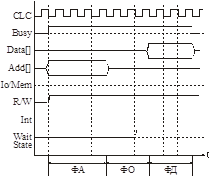
Цикл шины делится на фазы фиксированного времени.
Фаза адреса (ФА): длина – не менее 2-х тактов, чтобы приемники смогли «засечь» адрес.
Фаза ожидания (ФО): пока ВУ не выдает данные на шину. ФО имеет стандартный фиксированный размер.
Все ВУ должны успевать за ФО дешифровать адреса, выбрать данные и т.д. Иначе они не смогут работать с этой шиной.
Фаза данных – на шину выставляются данные.
Но все устройства имеют разное быстродействие. Для этого заводится сигнал wait state (WS). Он устанавливается до фазы данных – в середине ФО. ЦП, получив сигнал WS (медленное устройство), продлевает ФО еще на один такт.
Есть также сигнал High Speed (например, для ОП) – от ФО отнимается один такт.
IO/Mem – определяет, это порт ввода-вывода или адрес памяти.
Высокочастотные шины
Из-за высокой частоты передачи возникают некоторые эффекты, из-за которых могут потеряться данные.
Применяется код Хэмминга:
![]()
Завершающие три бита формируются по восьми.
2 бита – diagnostics, 1 бит – modify
Если испорчен один бит, код Хэмминга поможет его восстановить, если два – устранить ошибку.
Контроль паритета [выявит] только одну ошибку. Биты дополняются еще одним – четность/нечетность.
Если к устройству пришел неверный адрес, оно выставляет на шину сигнал ошибки. На высокочастотных шинах появляются:
- Фаза ожидания ошибки адреса
- Фаза ожидания данных
Т.к. ошибки появляются [редко], в эти фазы все просто чего-то ждут, обмена по шине нет.
Разделение шины между несколькими ЦП
Эффективность шины очень мала:
1) Большую часть времени на шине ничего не происходит.
2) Даже во время активности шины не все провода используются одновременно.
Надо совместить разные фазы шины разных ЦП, так, чтобы ЦП друг другу не мешали и использовали шину параллельно.
Предыдущий ЦП освободил шину следующий ее занимает. Такие шины называются транзакционными.
В настоящее время в […] системах, т.к. алгоритмы анализа очень сложны (ко всему прочему, фазы могут быть разной длины).
Используется арбитр шин устройство, которое управляет разделением шины между разными ЦП.

П просит АШ выдать ему шину. Если несколько запросов, АШ по какому-то алгоритму выделяет шину конкретному ЦП.
ЦП тогда начинает анализировать сигнал Busy.
Использование кэш
Когда мы общаемся с ВУ, должны на шину выставить адрес.
В некоторых системах:
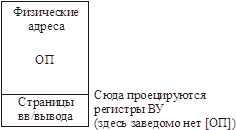
Старшие разряды шины служат для адресации регистров ВУ.
Когда мы даем команду «писать в регистр», данные оседают в кэш. Если после этого будет дана команда «читать кэш», прочитаны данные будут прочитаны из кэша! Что неверно!
КЭШ предназначен для устройств, обладающих только свойством хранения (например, ОП). А любое ВУ обладает еще какой-нибудь функцией (при этом совсем не обязательно ему обладать функцией хранения). Например, видеопамять – хранение и отображение.
Кэш не может отличить память ВУ от ОП. От нас потребуется соответствующее управление. Надо обращение к регистрам делать отличным от обращения к ОП.
- Шина адресов
- Шина ВУстройств
То есть, делаем логическую шину, отличную от адресной.
В Intel ввели специальные инструкции – in и out. ЦП четко различает (по коду) команда работы с памятью и с портами. Обращения к ВУ не кэшируются.
Есть еще одна проблема: в случае большой памяти ВУ.
По байтам брать нельзя, т.к. на каждый байт нужно прерывание, а это накладно (на весь пакет нужно одно прерывание).
1-е решение: сигнал кэшу сбросить всю свою память перед выполнением обмена с памятью. Но сбросятся все таблицы страниц! В ЦП УПА управляет адресацией с помощью таблицы страничных преобразований.
2-е решение: для каждой страницы 2 бита: «запрет кэширования» и «кэширование только при чтении»
Способы подключения ВУ к ВС. Использование контроллера ввода/вывода
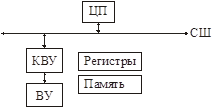
КВУ знает протокол СШ и подключается к ней. С другой стороны он подключается к ВУ, т.е. должен знать интерфейс ВУ.
Управляющими объектами (ВУ-ва) являются регистры и память. ВУ отображает их на виртуальное АП.
Если устройство быстрое и большие объемы передаваемых данных – используется резидентная память (существует два механизма – прямой доступ к памяти и отображение памяти).
Если медленное устройство и малые объемы передачи данных – используются регистры ВУ.
Как же КВУ интерпретирует адрес, выставленный на шину?..
Используются регистры:

К такому регистру (например, к RD) можно обращаться по одному адресу, но физически это два разных регистра. В один – отправляются данные, а из другого получаются.
КВУ дешевы и достаточно универсальны.
Недостаток: они реализованы в виде фиксированной логики. Логику работы изменить нельзя!
Если нужно подключать программируемые устройства, контроллеры не годятся, нужно применять механизм сопроцессора.
Механизм сопроцессора
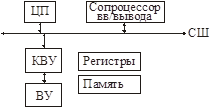
Сопроцессор не обладает полной вычислительной самостоятельностью. Он не может самостоятельно обмениваться данными по шине, принимать решения об обмене.
Сопроцессор имеет собственную систему команд, ему требуется помощь ЦП для организации работы.
1) Сопроцессор должен отличать циклы шины ЦП от своих циклов шины.
2) ЦП также должен отличать циклы шины сопроцессора от своих.
Escape-признак – это префикс команды.
Если команда, встречаемая ЦП имеет такой префикс, ЦП ее пропускает. Сопроцессор выполняет команды, следующие за признаком Escape.
Недостаток: нельзя изолировать поток команд сопроцессора от потока команд ЦП (в поток команд ЦП входят команды сопроцессора).
Тогда применяются процессоры ввода/вывода (ПВВ).
Они также имеют собственную систему команд, но могут управлять системной шиной. Следовательно, в памяти можно изолировать команды ЦП и ПВВ.
Отличие ПВВ от ЦП: ЦП никогда не останавливается. ПВВ останавливается по завершению операции.
ПВВ часто называют канальным процессором, а его программу – канальной программой.
Применяются для управления [произвольным] оборудованием (нужно только загрузить нужную программу) (например, в Mainframe’ах IBM).
Механизмы управления ВУ-ми через контроллеры. Управление через отображение регистров и адресов памяти на СШ

Самый простой способ.
Драйвер ВУ должен знать, какой регистр за что отвечает. Драйвер может в любой момент времени обратиться к любому регистру.
Преимущества:
- разработчик драйвера наиболее свободен в выборе – когда и что делать;
- за 1 цикл шины позволяет обращаться к запрошенному регистру (нет задержки).
Недостаток: если устройство сложное, нужно много регистров, а разрядность шины регистров ограничена.
Следовательно, нужно экономить регистры! (см. след. тему).
Механизм косвенной адресации
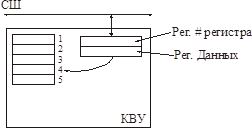
Число регистров в КВУ уменьшить невозможно (сколько есть, столько есть). Регистры эти имеют некоторые адреса внутри КВУ и не отображаются на шину.
На шину отображаются два регистра регистр номера регистра и регистр данных.
Алгоритм работы:
Надо сгенерировать два цикла шины:
Цикл 1: число, обозначающее номер регистра в рег. # регистра.
Цикл 2: данные передаются из регистра данных во внутренний регистр с этим номером, либо коммутируются внутри регистра на шину (прямо так, без пересылки данных из него в регистр данных).
Драйвер может опять в любой момент обращаться к любому регистру, но существует задержка, т.к. требуется два цикла шины.
Примечание: для ВУ с большим числом регистров, доступ к которым осуществляется редко (пример: часы реального времени (70h и 71h – регистры номера и данных) и CMOS-память – используются только в момент загрузки компьютера).
Если надо гонять часто большие объемы данных, механизм косвенной адресации неприменяем!
В случае быстрых устройств и больших объемов данных необходимо выставить мало регистров на шину, но чтобы не тратилось два цикла шины.
Конвейерная схема загрузки регистров
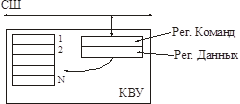
Смысл: любое устройство, работающее с таким КВУ имеет фиксированный набор команд и строго определенный порядок загрузки регистров для каждой команды.
Регистры уже не доступны драйверу по номеру, Номер регистра, в который будет помещена информация, определяется самой командой, а не драйвером.
Надо выполнить транзакцию и передачу КВУ данных, необходимых для данной операции. А КВУ сам распихает их по своим регистрам и запустит операцию.
В регистр команд загружаем команду (например, «читать сектор»). После этого последовательно помещаем все необходимые данные для этой команды в рег. данных.
После получения всего блока данных транзакция управления завершена, КВУ получает результат.
Чтобы не было бесконечного ожидания, считается, что любая операция записи в регистр команд сбрасывает предыдущую команду, если только она еще не выполняется.
Недостаток: в драйверах уже нельзя просто так использовать многопоточность, т.к. регистры должны запоминаться в нужном порядке.
Как еще можно снизить диапазон адресов? (см. след. тему).
Схема прямого доступа
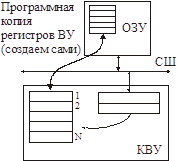
Можно организовать так называемый канал управления (для обмена командами с КВУ).
ПДП (DMA) может использоваться как для обмена данными, так и для обмена командами.
Заполняем программную копию регистров ВУ в ОЗУ требуемыми значениями и толкаем операцию ПДП.
Контроллер ПДП копирует блок из ОЗУ в регистры ВУ. Затем, КВУ автоматически начинает производить операцию.
Также в любой момент мы можем скопировать регистры ВУ в ОЗУ.
Недостаток: для организации обмена требуется ПДП.
КВУ должно поддерживать механизм ПДП. Ему нужно два канала: для данных и для управления. В Intel количество каналов ПДП ограничено, поэтому отказались от этого механизма.
В ВС с большими диапазонами АП актуальность сужения диапазона адресов уменьшается (для 32, 64 бит). Так что используют простое отображение регистров ВУ на шину.
Управление по опросу (polling)
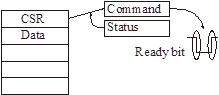
В
Status-регистре любого устройства всегда есть бит Ready (чаще всего он в знаковом разряде).
При поступлении команды в регистр команд аппаратура сбрасывает этот бит. При завершении команды бит снова устанавливается.
Ready bit можно проверять в цикле или по таймауту.
Для большого числа устройств работа в режиме polling’а неприемлема. Для асинхронных устройств этот режим вообще неприемлем.
Появился режим прерываний (см. след. тему).
Организация механизма прерываний
Задачи:
1) Проинформировать ЦП о завершении операции ввода/вывода.
2) Найти ту программу, которая может обработать это прерывание.
Была разработана схема, названная «векторной таблицей».
Все события пронумерованы.

Дескрипторы описывают программы обработки прерывания.
Дескрипторы аппаратно (процессорно) зависимы.
ЦП должен сохранять тот контекст, который нельзя сохранить другими средствами. Если работаем с виртуальной памятью, надо аппаратно сохранять тот контекст, который меняется автоматически аппаратно во время перехода (таблица страниц, стек и т.д.).
Чтобы выполнить процедуру аппаратного прерывания достаточно сказать о факте происхождения события и передать номер сообщения (сигнализация и передача номера).
Система прерываний – специальный набор действий (какой номер выставлять на шину, что делать, если несколько и т.д.).
Система прерываний радиального типа
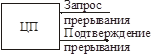
Ножка запроса прерываний всегда опрашивается центральным процессором между выполнением машинных инструкций.
Аппаратно в ЦП можно блокировать опрос этого бита (CLI).
Если этот бит устанавливается в 1, начинается обработка прерываний:
1) ЦП должен спасти свой контекст.
2) ЦП должен получить номер дескриптора таблицы (для этого сгенерировать цикл шины – подтверждение прерывания).

Контроллер прерываний программируемое через СШ устройство.
Необходимо указать контроллеру, какой номер события связан с каким ВУ.
Система прерываний радиального типа: каждое прерывание ассоциирует с каждым устройством специальный единичный запрос.
Для каждой линии IRQx – одно событие. Устройства подключаются к таким линиям.
Приоритет предоставления прерываний – алгоритм, по которому контроллер прерываний определяет приоритеты ВУ, подключаемых к одной линии IRQx (?).
В MS-DOS и Windows используется линейная приоритетная схема: устройства имеют статические приоритеты, которые определяются номером линии IRQx.
Возможны и другие алгоритмы.
Например, циклическая схема: после завершения обработки прерываний устройство становится самым низкоприоритетным.
Наивысший приоритет предоставляется асинхронным устройствам, а также системным событиям. Низший – синхронным устройствам.
Главный недостаток – ограничено число линий запроса, а следовательно и устройств.
Можно построить иерархическую схему (расширяем вторым контроллером):

Третий контроллер подключить нельзя, т.к. не хватит линий прерываний. Шина тоже может накладывать ограничение на число прерываний (ISA – 15).
Если количество устройств очень большое, нельзя использовать эту схему!
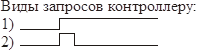
Чтобы не потерять короткие прерывания используется маска запомненных прерываний.
End of Interrupt – команда сброса масок блокировок и запомненных прерываний.
Нужно отправить ее контроллеру!
Нужно, чтобы на одну линию можно было подключить сколько угодно устройств – в этом случае нельзя использовать контроллер!
Приоритетная (параллельная) схема обработки прерываний
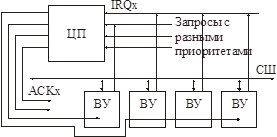
Производится программная или аппаратная привязка.
Устройство выставляет номер вектора на шину.
Но в цикле прерывания только одно устройство должно выставлять номер на шину.
Для этого вводится сигнал ответа устройству данного приоритета. ЦП должен иметь столько линий подтверждения прерываний, сколько у него линий запроса.
ACK должен попасть только к одному устройству данного приоритета!
Устройства с одинаковым приоритетом имеют «внутренний приоритет», определяемый их близостью к ЦП.
В этой схеме есть проблема, связанная с блокировкой запросов (в прошлой схеме проблем не было, блокировкой занимался контроллер).
С запросами связывается битовая маска, которая транслируется в слово состояния процессора. Т.е. ответственность за блокировку/разрешение прерываний возлагается на программиста (системного, конечно ;) )!
Действия, выполняемые в обработчике прерывания
intx: push ax
push si
 push
ds
push
ds
in ax, #port
mov ds:[si], ax
inc si
dec cx
pop
...
iret
Если темп поступления прерывания высок, не успеем все обработать.
Механизм прямого доступа к памяти
ЦП не участвует в обмене.
Аппаратуре нужно знать: номер порта и адрес буфера. Контроллер прямого доступа (КПДП) и есть та самая железяка!
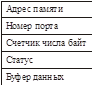
Это минимальный набор регистров
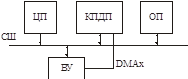
Как подключить это устройство.
По завершении операции КПДП генерирует прерывание.
Схемы организации прямого доступа:
1) Радиальная:
Канал прямого доступа резервируется для каждого устройства. ВУ выставляет к КПДП запрос DMAx с номером этого канала.
Недостаток: ограничиваем количество физических устройств, которые могут работать ПДП посредством каналов к КПДП.
2) Динамическая
Конкретное физическое устройство не привязывается к номеру канала.
Канал ПД выдается устройству при необходимости в прямом доступе и освобождается по завершению операции.
КПДП выполняет обмен между ОП и ВУ, генерируя цикл шины. В цикле шины могут присутствовать только физические адреса. Необходимо добавить (к регистрам выше) набор регистров адресации памяти, например, таблицу страниц.
Кроме того, буфер должен быть физически непрерывным.
Вопрос с кэшированием!
Параллельные вычисления
Общие понятия.
Сильно и слабо связанные:
- Сильно связанные общая память для всех ЦП;
- Слабо связанные у каждого ЦП своя память.
Однородные и неоднородные:
- Однородные – все ЦП одинаковые;
- Неоднородные разные ЦП.
Архитектуры:
- Симметричная (SMP) – сильно связанная система с однородными процессорами;
- Массово-параллельные системы (MPP) – неоднородные слабо связанные системы.
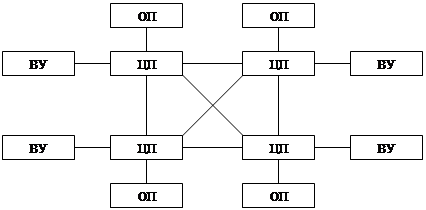 |
Параллельность команд и параллельность данных.
1. Уровень процессов (изолированных задач)
2. Второй уровень параллельности – общие коды (процесс), общие данные, много потоков – многопоточная обработка.
3. Алгоритмическая параллельность – параллельностью обладает сам алгоритм. Например, умножение матрицы на вектор, можно считать компоненты результирующего вектора одновременно (параллельно).
4. Формами параллельности обладает и самый обычный код (параллельность на уровне машинных команд, независимые операции).
При увеличении числа процессоров скорость системы увеличивается не линейно. Это объясняется тем, что передача информации будет занимать все большую часть времени.
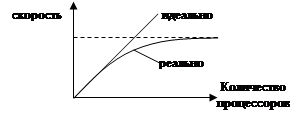 |
Перед обработкой данные надо сначала распределить между узлами, а потом передать результаты обратно.
Топологии массово-параллельных систем:
1. Пространственный куб
2. Пространственный тор
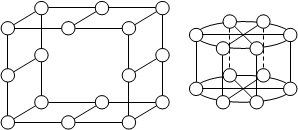 |
Цель: минимизировать число передач данных между узлами.
Обеспечивают большее количество подключенных устройств при меньшем количестве передач. Каждый узел – это ЦП, ОП, ВУ и т.д.
В SMP-системах синхронизация осуществляется с помощью семафоров.
Команда xchg AX,[BX] – обмен значений регистра AX и содержимого ячейки с адресом BX. Все происходит в цикле чтение/модификация/запись.
При наличии кэша ситуация резко ухудшается, т.к. ЦП обращается к кэшу, а не к общей ОП. Нужен механизм управления кэшами.
Путь 1 – поместить общие данные в некэшируемые ячейки данных.
Путь 2 – Синхронизация кэшей.
Заводится бит Shared для данных в кэше. Если такие данные изменяются, то ЦП обмениваются данными.
У Интела добавляются четыре бита SMEH.
Принципы работы периферийных устройств
- Внешние Запоминающие Устройства (ВЗУ)
- Устройства отображения
- Устройства связи
- Устройства сопряжения с объектами управления
- Специальные внешние устройства (таймеры и т.д.)
· Символьные (передают потоки данных в виде потока байтов)
· Блочные (всегда обмениваются блоками информации)
· Файловые (интерпретируют информацию в виде спецификаций ФС)
§ Синхронные (поставляют данные только по команде)
§ Асинхронные (сами в любой момент времени могут осуществить передачу данных)
Коммуникационные и устройства хранения:
- Произвольного доступа
- Последовательного доступа
По доступу:
- Коллективного доступа (запросы без ограничения из многих задач, не имеют истории запросов)
- Исключительного доступа (заранее задан порядок доступа, имеют историю запросов)
- Транзакционного доступа (исключительный доступ по очереди для разных задач)
Внешние Запоминающие Устройства (ВЗУ)
Магнитные ВЗУ
 |
Ферромагнетики имеют кристаллическую структуру
 |
Непосредственно записывать и считывать данные с носителя невозможно, нужно использовать специальное кодирование.
Виды кодирования:
- Амплитудное основано на абсолютном значении параметра;
- Частотное - основано не на значении параметра, а на факте его изменения.
Запись и считывание
Чтение – анализ возникающего при движении головки тока.
Запись – подача тока в головку.
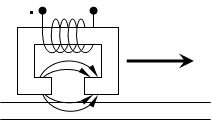 |
Плотность записи (размер пятна) зависит от формы магнита и магнитных свойств материала.
Нечувствительный материал – жутко большое поле, значит, надо повышать площадь, чтобы не затереть соседние записи (пятна).
Чувствительный материал – больше плотность записи, но меньше уровень сигнала.
Оптические ВЗУ
 |
Кодирование тоже частотное: луч на какое-то время уходит с фотоприемника и возникает импульс.
А если надо писать?
Болванка – диск без канавок.
Запись производится тоже лазером, но при повышенной мощности луча – прожигание канавок. Это однократная запись.
Для многократной записи:
1. Фазовые диски (быстоостывающие сплавы, если остывают медленно – становятся аморфными и работаю как зеркало, если быстро – кристаллизуются и рассеивают свет)
2. Пленочные диски (полимерные пленки, которые под воздействием лазера изменяют свои спектральные свойства)
Магнитооптические ВЗУ
 |
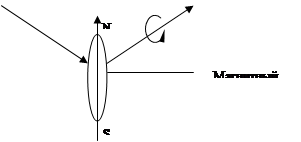 |
Разные излучения, имеющие высокие плотности, взаимодействуют между собой. Отражаясь от магнитного домена, луч получает спиновое
отклонение (поворачивается вектор поляризации). На обычном луче этого не видно, а только на поляризованном.
Луч, попадая на домен, изменяет свой вектор поляризации в зависимости от намагниченности материала (ориентации доменов). Таким образом, луч то проходит через поляризатор фотоприемника, то – нет.
Диаметр пятна в магнитооптических ВЗУ соизмерим с размером луча лазера, т.к. запись происходит в области, нагретой лазером. При нагревании, материал становится более магнитомягким. Магнитная головка может иметь большой размер пятна, но все равно область записи очень мала. Магнитная головка используется только при записи.
Способы кодирования информации
Как закодировать импульсами нули и единицы? Наличие импульса в определенном временном диапазоне означает единицу. Надо закодировать саму информацию и временное окно.
FM (Frequency Modulation) – ФК (Фазовое Кодирование)
 |
Каждое временное окно нужно закодировать. Временные окна делят пополам, следовательно, теряется ровно половина диска. Одно пятно уходит на синхроимпульсы, а второе на импульсы данных.
Плотность записи – 8ms. А исходно – 4ms.
Нужно использовать весь диск под данные и при этом не терять синхронизацию. Надо кодировать так, чтобы при длинных последовательностях нулей не терялась синхронизация.
MFM (МФК)
Применяется на 5-ти и 3-ех дюймовых дисководах.
В нулях нет данных, поэтому будем их использовать для синхронизации. Бит данных располагается в середине временного окна, бит синхронизации – в начале.
В первом нуле синхроимпульс не пишется, чтобы не затереть окно предыдущей единицы.
Недостаток: аппаратура должна чувствовать импульсы с точностью 2ms.
RLL – ГК (Групповое Кодирование)
Задача – преобразовать поток данных так, чтобы в нем отсутствовали длинные последовательности нулей (не более заданного количества).
Разобьем байт на две части по 4 бита.
| 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 1 |
| 0 | 0 | 0 | 1 | 1 | 1 | 0 | 1 | 1 |
| 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 |
| 0 | 0 | 1 | 1 | 1 | 0 | 0 | 1 | 1 |
| 0 | 1 | 0 | 0 | 1 | 1 | 1 | 0 | 1 |
| . . . | . . . | |||||||
В новой последовательности не более двух нулей подряд – не успеем потерять синхронизацию (можно назвать RLL 0.2). Плотность информации на диске уменьшится на 1/5.
Надо, не теряя синхронизацию, более полно использовать возможности носителя, чем исходный поток данных.
Соответствующий метод – RLL. Исходные данные – просто поток битов, а выходные такая последовательность битов, что между двумя единицами идет последовательность нулей, количество которых лежит в заданных пределах. Эти пределы прописаны в названии (например, RLL 2.7 – количество нулей от двух до семи включительно).
RLL 2.7
10 ® 1000
11 ® 0100
000 ® 100100
010 ® 001000
011 ® 000100
0010 ® 00001000
0011 ® 00100100
Реально нули на диск не пишутся, только единицы. Т.о. получается логическое сжатие информации. Реальный объем битов, который пишется на диск, уменьшается примерно на 40%.
Формат диска
Весь диск разбивается на одинаковые дорожки. Проблема – как найти начало дорожки?
Это делается чисто механически – на гибких дисках это дырочка, которая ловится оптопарой, а на жестких дисках делается вырез, при прохождении которого рядом с катушкой будет возникать импульс из-за изменения магнитного поля.
Формат дорожки.
 |
Зазор индекса содержит определенное количество синхроимпульсов, по которым определяется величина временного окна.
Сначала определяем величину временных окон, только потом читаем данные. Если не известен размер временных окон, то вообще ничего прочитать не получится.
Формат сектора
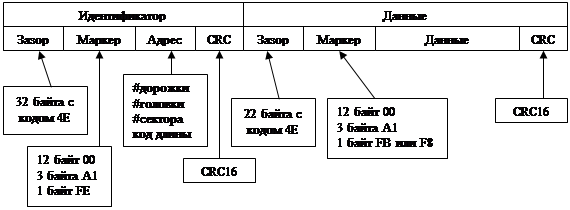
Идентификатор создается при форматировании и больше никогда не изменяется.
Последний байт маркера данных показывает тип сектора:
FB – сектор обычных данных
F8 – сектор стертых данных (не видны команде стандартного чтения)
Перед записью данных всегда производится запись межзонных промежутков.
 |
Малые интерфейсы
Контроллеры Внешних Устройств разные для разных Системных Шин. Нужно, чтобы можно было подключать большое количество устройств к одному контроллеру.
Малые интерфейсы – интерфейсы между контроллером и внешним устройством.
ST412 (Seagate Technology)
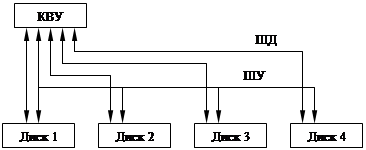 |
Контроллер позволяет подключать до четырех дисков. Есть две шины – шина
управления (одна на всех) и шина данных (по одной на устройство).
Шины данных – аналоговые!
Недостаток – контроллер должен знать характеристики всех дисков, чтобы ими управлять.
Должна быть некая информация, устанавливаемая извне. Для этого использовался CMOS.
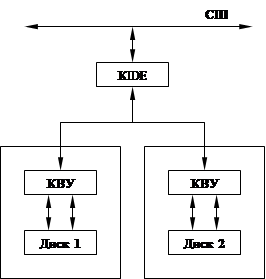 |
IDE
 |
Производитель выполняет диск вместе с контроллером к нему. Контроллер IDE просто коммутирует на шину нужный диск. Одновременная работа с двумя дисками невозможна.
Не нужно знать о характеристиках диска.
Можно ввести понятие физического и логического адресов. Сейчас диску передается уже номер логического сектора (LBN), а контроллер сам знает, где этот сектор физически находится. Еще и можно применять переменное количество секторов на дорожке.
Эта схема хороша для подключения большого числа дисков, но не позволяет работать со всеми дисками одновременно.
Интерфейсы, решающие эту проблему:
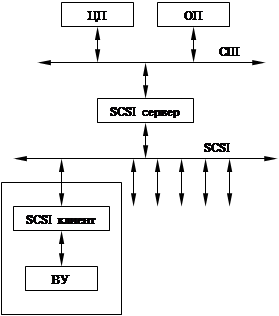
SCSI (Small Computer System Interface)
Был разработан как системный интерфейс, но потом стал использоваться как малый.
Внешнее устройство имеет на выходе SCSI-клиент интерфейс.
Каждое ВУ имеет свой собственный адрес (1, 2, 3, 4, 5, 6, 7).
SCSI-сервер имеет адрес 0.
В принципе, SCSI полноценная шина. Она имеет циклы шина, адреса, набор управляющих команд.
Команды делятся на группы:
1. Обязательные (не зависят от типа устройства)
2. Рекомендуемые (для выполнения операций обмена, зависят от типа устройства)
3. User-defined
Ограничен не сам ресурс, а скорость шины (канала доступа к этим ресурсам). Управление ВУ осуществляется с помощью подачи последовательностей команд по SCSI шине (логическое управление).
Недостаток – высокая стоимость.
Применяется там, где без него вообще нельзя.
RAID (организация дисковых массивов)
RAID0 – ничего, обычный диск.
RAID1 – оптимизация доступа.
RAID2 – резервирование (зеркало), один сектор пишется сразу на два диска, но зато чтение происходит с обоих сразу – при чтении удваивается скорость.
RAID5 – резервирование и “склеивание” дисков, нужно не менее трех. В одном из них хранится XOR всех секторов с таким же номером с других дисков. Повышается скорость из-за “склеивания” и возможность восстановить информацию, если любой из дисков (но только один) грохнется.
Hot Plug интерфейсы – PCMCIA и USB
Основная идея – обеспечить на носимых мобильных компьютерах, где мало слотов для ВУ, возможность динамически (без выключения компьютера) подключать и отключать устройства.
У них специальные физический и электрический интерфейсы.
PCMCIA Box – контроллер, управляющий слотами, в которые вставляются ВУ. Он работает совместно с сервисами типа Plug’n’Play.
 |
Особенности конструкций ВЗУ
 |
Ключевая проблема – надо довести магнитное поле до магнитного покрытия.
Чем дальше головка от носителя, тем больше пятно. Чтобы более полно использовать носитель, надо уменьшить магнитное пятно. Лучше всего, когда расстояние до покрытия – нулевое. Но тогда возникает контакт (так называемые контактные магнитные носители).
Носителю не нужна вертикальная жесткость – ленту можно прижать к головке. По этой технологии разработаны магнитные ленты и гибкие диски.
Недостаток – стирается магнитное покрытие при увеличении скорости и в результате разогрева.
Надо отодвинуть головку от носителя, для увеличения скорости, но не сильно (на микроны).
Пример – магнитный цилиндр.
Из-за тепловой деформации и при резком торможении нельзя сделать достаточно малый зазор.
Еще путь: динамически заставлять головку адаптироваться под изменение формы носителя.
 |
Тут нужен диск.
Скорость воздуха вблизи диска выше из-за вязкости и трения воздуха о диск.
Головка из-за своей формы приобретает некоторые аэродинамические

свойства: при вращении диска на головку действует подъемная сила, и она отрывается от диска.
С другой стороны пружина прижимает головку к диску.
 |
Итак, головка находится в устойчивом равновесии. Она будет поддерживать некоторый зазор. Технически можно обеспечить зазор в несколько микрон.
Проблема: когда зазор станет соизмерим с размером пылинок, пыль, которая засасывается под головку, приводит к разогреву и износу.
Выход: технология “винчестера” – диск помещается в герметичный корпус (герметичный от пыли, но пропускающий воздух с помощью мембран, чтобы выравнивать давление).
Привод головок
Подошли к пределу плотности записи для материала. Как еще повысить плотность?
Надо позиционировать головку как можно точнее, чтобы приблизиться к пределу продольной плотности записи.
Сначала для привода головок использовался шаговый двигатель.
Подается ток противоположной направленности – система в равновесии. Если поменять направление тока – планка сдвинется ровно на один зуб. Еще переключим – еще
на зуб. Поэтому этот шаговый двигатель – линейный.
Есть еще круговой.
 |
Применяется для гибких дисков. Зуб нельзя сделать меньше определенного размера.
Тогда: асинхронный двигатель с обратной связью.
Несколько дисков, последний слой покрытия называется “серво”. На эту серво-поверхность записывается аналоговый сигнал. Серво-головка только читает.
Головке дают сигнал “вперед” на время, равное времени, чтобы пройти половину периода (см. серво-поверхность).
Серво-головка служит обратной связью: ловит минимум на серво-поверхности, и останавливает головки. Головки все время подрагивают, т.к. двигатель постоянно работает.
Связные ПУ (Устройства связи)
Служат для передачи информации между компьютерами.
ВЗУ – аналоговые.
В случае Связных ПУ можно передавать прямо цифровую информацию, т.к. и источник и приемник – компьютеры.
Классификация связных ПУ.
По способу кодирования:
- Амплитудные
- Частотные
По способу формирования сигнала:
- Модулированные
- Немодулированные
По механизму синхронизации:
- Синхронные
- Асинхронные
По средам передачи информации (все носят электромагнитную природу):
- Проводные линии связи
- Оптические
- Радио
Проводные передача по металлическому проводу
 |
Но не все так просто – окружающая среда воздействует на передаваемый сигнал.
Медный провод – наименьшее удельное сопротивление.
При увеличении длины растет сопротивление провода и, следовательно, падает уровень сигнала. Как сделать, чтобы не было зависимости от длины?
Надо использовать “Токовую Петлю”.
При работе на больших расстояниях надо использовать источники тока – блок питания, который поддерживает в цепи одинаковую силу тока, меняя свое напряжение.
Передача информации напряжением – механизм, использующий напряжение.
Передача информации током – механизм, использующий ток.
Активное сопротивление влияет на амплитуду сигнала. А индуктивность и паразитная емкость проводов влияют на фазу сигнала – намного хуже.
Чем выше частота сигнала, тем больше его искажают по фазе индуктивность и емкость – будут завалены фронты у меандра.
По Фурье: можно разложить любой периодический сигнал на сумму синусоид, а затем собрать обратно.
Оптоволокно
Еще луч имеет толщину, и даже у лазера луч немного конический.
Происходит искажение длин – вот и сдвиг по фазе. Еще и вибрация вызывает жуткие помехи. Так что проблем не меньше, чем при передаче по проводу, только природа другая.
Радио
У радиосигнала поглощение пропорционально квадрату расстояния, а не линейно, как у провода.
Невозможно реализовать дуплексные соединения.
Мертвая зона: при мощности, свыше определенной, приемник слепнет”. Если мы излучаем 10 Вт, а придет сигнал 0.2 Вт, мы его не поймем.
Выход – разделение частотных диапазонов. Еще – применение направленных
 |
антенн (излучают не по сфере, а пучком). Тогда возможно координатное разделение. Если этого нет – остается только временное разделение.
Спутниковая связь
Тут два варианта – спутники с высокой орбитой и спутники с низкой орбитой.
 |
Наши используют спутники с высокой орбитой. Общение только через спутник-посредник.
 |
А американцы используют низкие орбиты
Недостатки:
1. Сложный центр управления спутниками
2. Спутники задевают верхние слои атмосферы, постепенно снижаются, затем падают на Землю. Живут один-два года.
Зато такие спутники дешевые и легкие.
Подсистемы ввода/вывода
Файловые устройства
Цель любой программы – обработка данных, т.е. надо грамотно построить структуры данных и написать алгоритмы их обработки.
Структуры данных, которыми оперирует язык:
- Array[] A
- String B
- Struct C
Можем прочитать откуда-то эти структуры:
read( #канала, A, B, C )
Отсюда исходят следующие действия:
read( #канала, Address, Len )
О длинах структур данных и куда их помещать знает только компилятор, следовательно, он и вычисляет Address и Len.
Файл может быть последовательного или произвольного доступа. В файле последовательного доступа есть так называемая текущая позиция.
Чтобы выполнить операции доступа к файлу, нужна начальная инициализация:
#канала = open( имя_файла, тип_доступа )
При открытии файла происходит следующее:
- контролируются права доступа для данного пользователя с данным типом доступа
- формируется структура FCB (File Control Block)
- файловый процессор заполняет ее поля.
RMS (Record Management System)
По-русски – Система Управления Записями (СУЗ).
Она имеет FCB и буфера ввода/вывода, через которые и происходит реальный обмен данными.
RMS рассматривает любой файл как набор кластеров. Каждый кластер на уровне файла называется VBN (Virtual Block Number).

При закрытии файла ( close ) все буфера сбрасываются на диск. По команде Flush все буфера просто сбрасываются на диск без закрытия файла.
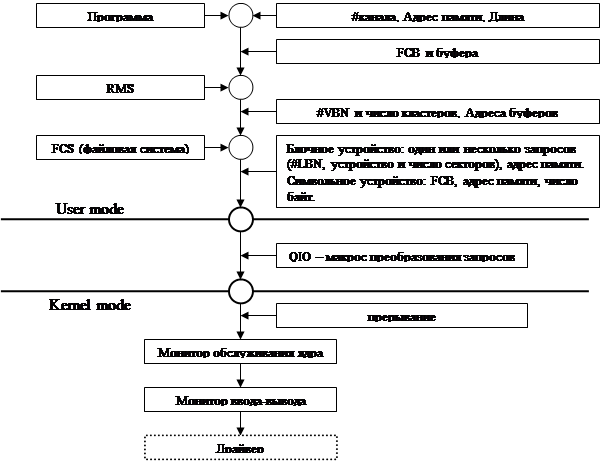 При необходимости обмена с диском RMS взаимодействует с файловым процессором.
При необходимости обмена с диском RMS взаимодействует с файловым процессором.
Конкретное блочное устройство рассматривается как плоский массив блоков фиксированного размера.

Для символьных устройств нет буферов, но есть FCB, где содержатся параметры устройства.
При запросе ОС должна проверить указатели на корректность, т.е. указатель должен быть в области user’а и под ним должна быть отображена физическая память. Еще надо проверить, весь ли буфер попал в отображенную память.
Пока идет обработка на уровне ядра, передиспетчеризация процессов запрещена. Нужно где-то сохранять параметры ввода/вывода, для этих целей у ОС есть pool (кусок памяти для размещения динамических данных ОС).
Запросы ввода/вывода оформляются как IORP (Input/Output Request Packet). Поскольку к моменту выполнения запроса произойдет передиспетчеризация, то необходимо отобразить буфера ввода/вывода в ядро. Для этого производится двойное преобразование адреса:
1. Преобразование линейного адреса буфера процесса в физический адрес.
2. Отобразить в область ОС полученную область физической памяти.
Еще нужно запретить перемещение физических страниц памяти.
Монитор ввода/вывода должен по базе данных драйверов найти нужный драйвер, создать IORP в невыгружаемом пуле, поставить его в очередь к драйверу.
Для выбора драйвера используется база данных внешних устройств, сложность которой определяется:
- сложностью ОС
- сложностью конфигурации железа.
Драйвер – программа, которая делает ОС независимую от железа.
Внешнее устройство – разделяемый ресурс, доступ к которому осуществляет драйвер.
Идеология BIOS часть аппаратных функций, реализованных разработчиком, являются системно-независимыми.
База данных ввода/вывода
1. Устройства, которые отображаются в прикладные программы, называются Device.
2. Устройства, которые не отображаются в прикладные программы, называются Bus.
3. Потоковые драйверы/фильтры.
База данных – списки блоков управления CB (Control Block), которые отражают физическую структуру системы.
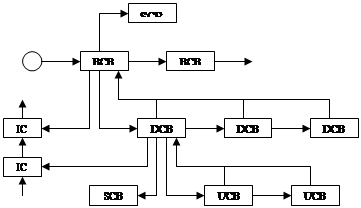 |
BCB |
Bus Control Block |
| DCB | Device Control Block |
| UCB | Unit Control Block |
| ICB | Interrupt Control Block |
| SCB | Synchronization Control Block ? |
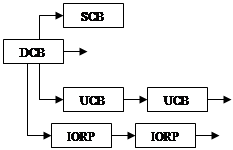
IORP можно передать самому драйверу или поместить в очередь, прицепленную к DCB.
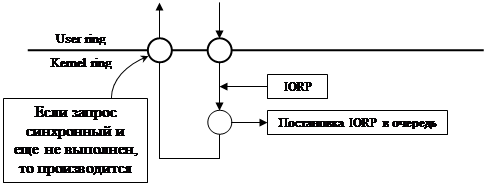 |

Преобразование ALBA ® FA ® KLBA может быть невозможно, т.к. страницы могут быть не выделены.
Стратегии организации последовательности IORP:
- возлагается на ОС
- драйвер сам решает, куда вставить IORP.
Если у драйвера очередь не пуста, то остается надеяться на обслуживание драйвером.
Вернуть управление программе, только если запрос был успешно обслужен (если запрос синхронный). Номер флага, который ожидает программа, помещается в IORP. Как только запрос выполняется флаг сбрасывается и возобновляется программа, ожидавшая на этом флаге.
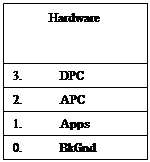 |
| RPC | Remote Procedure Call |
| LPC | Local Procedure Call |
| APC | Asynchronous Procedure Call |
| DPC | отложенный |
На DPC запрещена передиспетчеризация, на APC запрещена обработка асинхронных запросов, на Apps все разрешено.
Если очередь запросов пуста, то драйвер надо разбудить.
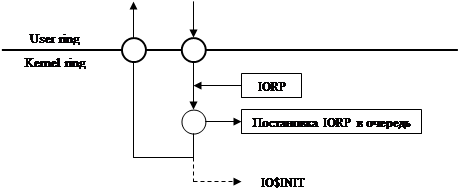 |
Проблема: из прерывания нельзя непосредственно вызвать IO$END, поскольку можем не находиться в режиме ядра.
Выход – механизм отложенных прерываний.
Механизм отложенных прерываний
Необходимо перевести систему в состояния ядра так, чтобы данный фрагмент кода обладал исключительными правами на этот контекст, и при этом передать управление в заданную точку.
Ядро не повторновходимо. Если мы владеем контекстом ядра, никто другой не может им владеть.
Единственное место, в котором начинается и заканчивается транзакция обращения к ядру – место переключения из UserMode в KernelMode. Только в этой точке передаются права на контекст ядра.

Ловушка отложенных прерываний
Для реализации используется XCHG AX,[BX], это семафор, реализованный на процессоре.
mov AX,1
xchg AX,[BX]
Если в результате в AX будет 0, то значит, семафор был свободен, и мы его заняли, а если 1 значит был занят и надо еще подождать.
ОС вынимает из ловушки первый адрес и по call передает туда управление, когда управление вернется, ОС продолжает просмотр ловушки.
Мы можем завершить запрос ввода/вывода (выполнить соответствующие действия). Потом делаем jmp, как будто бы ОС заставила драйвер обработать новый запрос. Все будет так же, как и в первый раз, но после команды старт попадем опять на границу U/S.
Есть соблазн запихнуть в режим ядра как можно больше всего: работу с окнами, графикой, файловый процессор и т.д. для повышения быстродействия. Но тогда время обработки запросов приложений в режиме ядра будет слишком большим, а то и вообще система перестанет работать. Выход идеология микроядра.
Идеология микроядра

Все сервисы работают в изолированных адресных пространствах. Если им что-нибудь надо, то они обращаются к микроядру.

Интерфейс заключается в пересечении границы. Одна граница один интерфейс.
Если ЦП поддерживает всего два кольца защиты, то Супервизор тоже запихивают в Kernel Ring.
Итак, есть два интерфейса: Kernel|Supervisor и Supervisor|User. В супервизоре все процессы работают в своих адресных пространствах. Все проверки безопасности – на уровне супервизора.
В Windows2000 это сделано так.
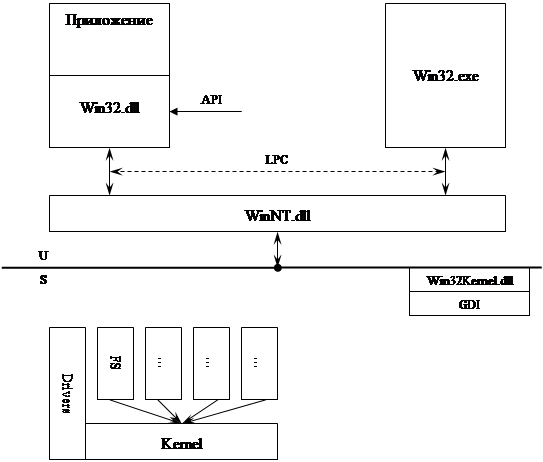 |
Каждый модуль (FS, менеджер управления память, менеджер управления объектами и т.д.) запущен как отдельный поток со своим контекстом.
Драйвер может сам генерировать потоки, но его базовый поток поток ядра.
GDI находится в супервизоре только с Win2000, раньше он был в Win32.exe. Без Win32.exe ни одно Win32-приложение работать не будет.
Синхронизация запросов ввода/вывода в ядре
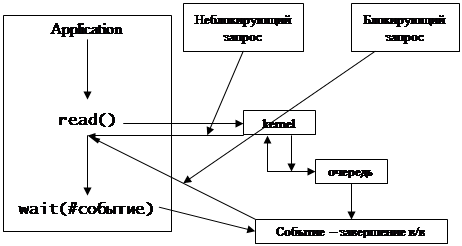
У любого объекта Windows есть заголовок синхронизации, их можно ставить в очередь событий.
Процесс блокируется в ожидании некоторого события, которое ставится в очередь событий.
Теперь, выполнив запрос, драйвер говорит, что событие произошло и процесс продолжает работу. Иногда, выдав запрос, нужно параллельно с его обработкой выполнять другие действия.
Запросы делятся на:
- блокирующие
- неблокирующие
В системах, поддерживающих неблокирующие запросы ввода/вывода, есть модификатор команд:
IO$READ + NoWait
Теперь возникает другая проблема – неблокирующий запрос выполнен, а как узнать, успешно ли он завершен? Это знает только драйвер.
Решение – в контексте задачи создается буфер IOSB (Input Output Status Block), в который драйвер помещает результаты выполнения операции. Это же происходит и при блокирующий запросах, но все это делается неявно.
Итак, для выполнения операции нужно следующее:
1. Запрос (код операции, параметры)
2. Координаты запроса (FCB, #LBN, длина)
3. Адрес буфера
4. IOSB
5. Объект синхронизации.
Буферизованный и небуферизованный обмен
IORP – структура для хранения параметров запроса ввода-вывода. ОС копирует в этот пакет параметры из запроса QIO, которые хранятся в системе. Т.е. параметры в системном пуле и не […..]. Этими параметрами можно пользоваться. Если параметры типа указатель, то они имеют смысл только в контексте задачи. Если на процессоре наша задача, то в CR3 нужное страничное преобразование. Если на CR3 адрес ТСП другого приложения, то указатель будет неправильным. Поэтому драйвер не сможет выполнить обмен с буфером. Надо драйверу передать корректный указатель. Указатель должен существовать в контексте драйвера. Нужно получить новый логический адрес – в контексте драйвера. Нужно выяснить физический адрес буфера, полностью преобразовать его в логический адрес в контексте драйвера.
У драйвера контекст является контекстом, который совпадает с физической памятью. Т.е. там физический адрес совпадает с линейным. И этот адрес кладем в IORP. Поэтому нужно запретить перемещение и выгрузку – зафиксировать страницу. Также нужно запретить свопинг задач (выгрузка задачи полностью на диск).
Если таких задач много (зафиксировавшихся), то система начинает тормозить, и, в конце концов, падает.
Поэтому обмен между драйвером и буфером нужно делать через специальную область памяти – неперемещаемую.
Буферизованный обмен – это обмен через специальную область памяти – неперемещаемую. На самом деле при таком обмене существуют 2 буфера один в неперемещаемой области памяти, второй в области приложения.
Запись: ОС заводит системный буфер, копирует туда буфер задачи, драйвер читает из буфера.
Чтение: ОС заводит буфер, драйвер пишет туда, ОС копирует из системного буфера в буфер приложения.
Это позволяет не ограничивать функции задачи.
Проблемы здесь в размерах. Например, по кластерам 128кБ на кластер.
Буферизованный обмен – для медленных, с небольшими буферами [устройств].
Небуферизованный – для быстрых и с большими буферами.
Запланированный ввод/вывод
Ничего нет.
Настройка ОС
На примере MS-DOS (система с начальной настройкой)
PnP – аппаратный интерфейс, служащий для динамической конфигурации и реконфигурации системы.
Этот механизм предполагает:
1. сигнализацию о вставлении/удалении устройства
2. идентификацию устройств.
PnP не может осуществлять динамическую реконфигурацию самой ОС, а только внешних устройств.
Драйверы
Драйверы надо писать если:
- данный ресурс будет разделяемым
- данным устройством можно управлять только из контекста ядра.
Второе условие означает, что прикладная программа может не успевать обрабатывать данные.
Синхронные запросы: полученные с их помощью данные потерять нельзя. Такими устройствами можно управлять из прикладной задачи (это обычно специализированные устройства). Драйвер писать неэффективно.
Драйверы устройств, не поддерживающих прерывания
Если устройство не генерирует прерывание, то точка входа драйвера по прерыванию цепляется к таймеру (для опроса) – polling.
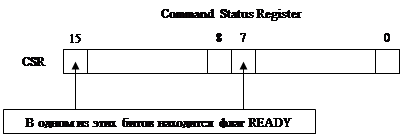
Если READY = 1, то операция, запрошенная у ВУ завершена. Этот бит постоянно опрашивается (программно).
Если работаем в ВУ на прикладном уровне, то придется самим опрашивать регистры ВУ. В серьезных ОС прерывания на прикладном уровне недопустимы.
Файлы и файловые системы
Файловая система – это набор правил хранения и обработки информации.
Файловый процессор – программа, которая выполняет эти правила.
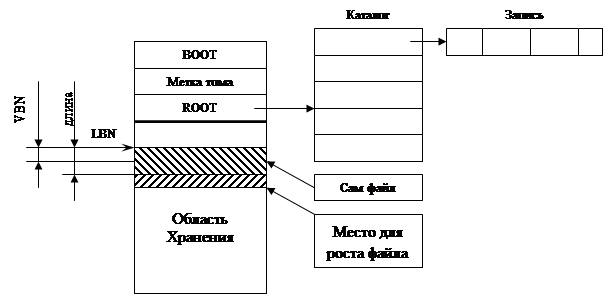 |
В правилах есть постоянные и переменные параметры. Переменные параметры должны быть определены в метке тома. Ее положение – жестко заданная константа в любой ФС. Том – накопитель ФС.
Задачи ФС:
1. Оптимально разместить данные на носителе
2. Найти потом эти данные.
Необходимо присвоить каждому набору данных имя и дать возможность:
1. автору определить это имя
2. по имени найти набор данных
Сегментная ФС (на примере RT-11)
Файлы хранятся непрерывными сегментами, следовательно, каждый файл характеризуют два числа – номер начального сектора и длина. Так как файлы непрерывны, то для последующего увеличения их размера резервируется несколько секторов.
Каталог – массив записей фиксированного размера. Сам каталог имеет фиксированную, заранее определенную длину. Эта константа хранится в метке тома. Формат записей заранее определен. Это набор полей, одно из которых – имя, а остальные – сведения, необходимые для нахождения файла на диске.
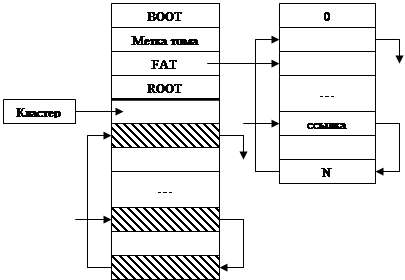
Файловые системы с глобальным индексом (FAT) решают проблему непрерывного хранения файлов. Теперь они могут располагаться кусками по всему носителю. Вся область хранения файлов разбивается на кластеры. Для нахождения файла, по-прежнему нужно знать только два числа – номер начального кластера и длину файла. Последовательность кластеров описывается списком – таблицей размещения файлов (FAT), которая состоит из записей, содержащих только номер следующего кластера (и записи соответственно). Каждый кластер соответствует определенной записи в таблице и наоборот. Если в записи 0, то значит кластер – свободен, если –1 – последний в цепочке.
Размер записи определяется количеством кластеров, так, чтобы можно было описать кластер с наибольшим номером.
UFS
Вместо индексного файла теперь индексные узлы – inode, размером в один сектор. Место выделяется блоками, их описание хранится в индексном файле. Метка тома теперь называется Суперблок. Создается связанный список свободных блоков. Нельзя сделать undelete, т.к. список портится.
S5FS
Введены множественные битовые карты.
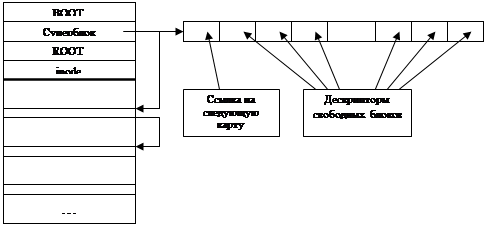 |
Если произойдет сбой во время модификации суперблока (там лежит ссылка на первую карту свободных блоков), то диск почти не восстановим.
FFS (Fast File System) – файловая система BSD
Выделение логическими блоками. Идеологически – почти HPFS.
Индекс файла строится следующим образом:
По мере роста размера файла, сначала применяется непосредственные ссылки на блоки, далее одноуровневые, затем двухуровневые, а потом и трехуровневые ссылки на подындексы.
Но остается основная проблема – надо сделать индексный файл переменной длинны, следовательно, он теряет свойство непрерывности. Это означает, что он должен быть файлом и где-то надо хранить информацию о нем.
С появлением сетей, единицей учета становится уже группа файлов, а не один файл.
NTFS
Нельзя ставить на диски меньше 100 МБ. Эффективно работает с дисками в несколько ГБ.
Вся информация, в т.ч. и для файлового процессора, становится файлом. Пропадает служебная информация.

MFT2 – копия MFT сразу после форматирования.
Индекс уже описывает не файл, а некий набор данных, причем набор данных является множеством атрибутов. Каждый атрибут имеет имя и содержимое.
В одном индексе может описываться не один файл, а набор файлов. Файлы называются потоками – name : stream, где name – имя набора, stream – имя файла в наборе.
Например, все файлы БД можно поместить в один набор.
Раз атрибуты имеют свои имена, то можно вводить свои атрибуты (сейчас набор атрибутов фиксирован). Для этого заводится файл атрибутов, содержащий список атрибутов.
Access Control List (Список Управления Доступом) теперь можно хранить в индексе. Это массив ACEntry – структуры, которая описывает пользователя и группу и их права доступа.
Если произойдет сбой при изменении MFT, то все упадет.
NTFS – транзакционная файловая система. Любые операции по изменению ФС рассматриваются как транзакции.
log – файл журнала транзакций (всегда > 5 МБ). Это кольцевой буфер. Запись закрывается в момент закрытия транзакции. Если произошел сбой, то находятся все незакрытые записи и производится обратный откат.
В NTFS все атрибуты, и файлы тоже.
Если файл маленький, то он записывается прямо в индекс.
Операция монтирования файлового устройства
Как выяснить, какая ФС находится на данном диске? Механизмов для этого нет.
Чтобы ОС могла определять тип ФС можно загрузить в ОС набор ФП и пытаться определить тип ФС. Но все это выполняется вручную или в полуавтоматическом режиме.
Монтирование – связывание ФП с диском (то же самое, что и открытие файла).
А в сетях?
На локальных машинах может стоять локальная ФС, которая при экспортировании преобразуется в виртуальную.
Сетевые файловые системы
Локальная ФС – ФС, находящаяся на то же компьютере, что и ФП.
Структура локальных файловых систем.

Модуль кэша ввода/вывода кэширует в первую очередь информацию каталогов, части индексных файлов и другую информацию ФП. Драйвер ФС имеет признак – локальная это ФС или удаленная.
Структура сетевых файловых систем.
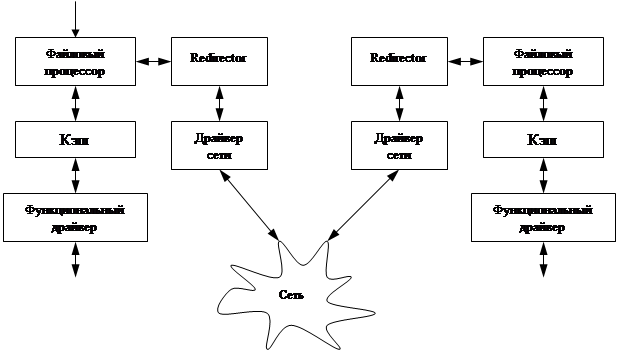
Используются протоколы SAMBA (для локальных сетей) и ICFS (расширение SAMBA, поддерживающее маршрутизацию через Internet).
Недостаток таких систем – нельзя обеспечить большую емкость на каждой машине. А сейчас задача – хранение сверхбольших объемов данных. Два пути решения:
1. сделать сверхбольшие объемы дисков
2. подключать к локальной ФС удаленные ФС.
ASM – Application Storage Manager
Реализуется локальная, но виртуальная ФС (похожа на виртуальную память).
На диске создается большой индексный файл – на полдиска, а на вторую половину загружаются файлы с ленты, по мере необходимости. Файлы, к которым долго не было обращений, выкидываются на ленту.
NFS – Network File System
 |
К каждому компьютеру подключается несколько дисков. Все это рассматривается как единая ФС.
NFS позволяет в любой каталог ФС локальной машины подключать любой фрагмент любой удаленной ФС.

Путь запроса O ® A ® B ® A ® O
Недостатки:
1. много передач между компьютерами
2. можно не найти файл, если администратор компьютера A перетащит подключение B в другой каталог.
NAS – Network Attached Storage
Хранилище, подключенное к сети.
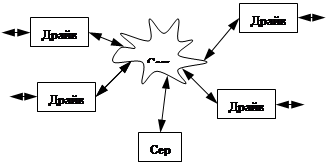 |
Добавляется сервер ФС, на котором хранится структура всей сети и все локальные каталоги. Любой запрос на чтение/запись сначала направляется на сервер, а потом перенаправляется туда, где действительно находятся данные.
Путь запроса O ® B ® O
Недостаток: сложно реализовать сервер ФС.
SAN – Storage Area Network
Fibre Channel интерфейс, позволяющий подключать больше устройств, чем SCSI.
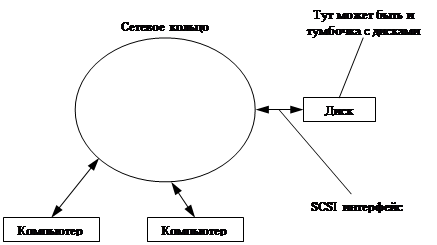
Идея:
Эта штука создает впечатление, что работа происходит с локальным SCSI устройством.
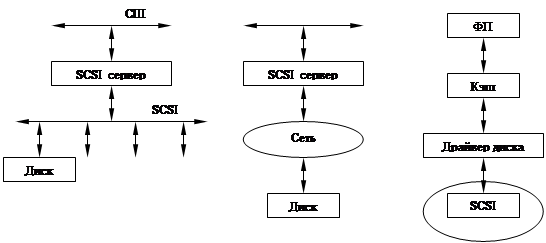
Fibre Channel использует оптоволоконные кабели, но это очень дорого.
Преимущества:
1. Скорость (около 1 Гб/с)
2. Поддержка SCSI.
iSCSI
Это протокол, поддерживающий SCSI интерфейс, но работающий с TCP/IP.
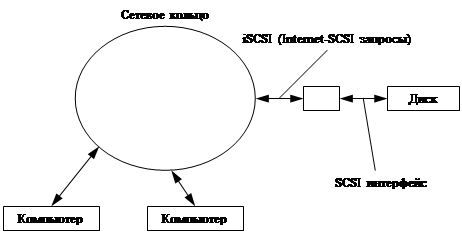
© 2010 Интернет База Рефератов