
Рефераты по сексологии
Рефераты по информатике программированию
Рефераты по биологии
Рефераты по экономике
Рефераты по москвоведению
Рефераты по экологии
Краткое содержание произведений
Рефераты по физкультуре и спорту
Топики по английскому языку
Рефераты по математике
Рефераты по музыке
Остальные рефераты
Рефераты по авиации и космонавтике
Рефераты по административному праву
Рефераты по безопасности жизнедеятельности
Рефераты по арбитражному процессу
Рефераты по архитектуре
Рефераты по астрономии
Рефераты по банковскому делу
Рефераты по биржевому делу
Рефераты по ботанике и сельскому хозяйству
Рефераты по бухгалтерскому учету и аудиту
Рефераты по валютным отношениям
Рефераты по ветеринарии
Рефераты для военной кафедры
Рефераты по географии
Рефераты по геодезии
Рефераты по геологии
Рефераты по геополитике
Рефераты по государству и праву
Рефераты по гражданскому праву и процессу
Рефераты по делопроизводству
Рефераты по кредитованию
Рефераты по естествознанию
Рефераты по истории техники
Рефераты по журналистике
Рефераты по зоологии
Рефераты по инвестициям
Рефераты по информатике
Исторические личности
Рефераты по кибернетике
Рефераты по коммуникации и связи
Курсовая работа: Алгоритмы сжатия данных
Курсовая работа: Алгоритмы сжатия данных
Курсовая работа
Алгоритмы сжатия данных
Введение
Общие сведения
Энтропия и количество информации
Комбинаторная, вероятностная и алгоритмическая оценка количества информации
Моделирование и кодирование
Некоторые алгоритмы сжатия данных
Алгоритм LZ77
Алгоритм LZ78-LZW84
Алгоритм PPM
BWT - преобразование и компрессор
Кодирование Хаффмана
Арифметическое кодирование
Алгоритм арифметического кодирования
Реализация алгоритма арифметического кодирования
Реализация модели
Доказательство правильности декодирования
Приращаемая передача и получение
Отрицательное переполнение
Переполнение и завершение
Адаптивная модель для арифметического кодирования
Эффективность сжатия
Заключение
Список литературы
Приложение 1. Программный код
Приложение 2. Интерфейс программы
Основоположником науки о сжатии информации принято считать Клода Шеннона. Его теорема об оптимальном кодировании показывает, к чему нужно стремиться при кодировании информации и на сколько та или иная информация при этом сожмется. Кроме того, им были проведены опыты по эмпирической оценке избыточности английского текста. Он предлагал людям угадывать следующую букву и оценивал вероятность правильного угадывания. На основе ряда опытов он пришел к выводу, что количество информации в английском тексте колеблется в пределах 0.6 — 1.3 бита на символ. Несмотря на то, что результаты исследований Шеннона были по-настоящему востребованы лишь десятилетия спустя, трудно переоценить их значение.
Первые алгоритмы сжатия были примитивными в связи с тем, что была примитивной вычислительная техника. С развитием мощностей компьютеров стали возможными все более мощные алгоритмы. Настоящим прорывом было изобретение Лемпелем и Зивом в 1977 г. словарных алгоритмов. До этого момента сжатие сводилось к примитивному кодированию символов. Словарные алгоритмы позволяли кодировать повторяющиеся строки символов, что позволило резко повысить степень сжатия. Важную роль сыграло изобретение примерно в это же время арифметического кодирования, позволившего воплотить в жизнь идею Шеннона об оптимальном кодировании. Следующим прорывом было изобретение в 1984 г. алгоритма РРМ. Следует отметить, что это изобретение долго оставалось незамеченным. Дело в том, что алгоритм сложен и требует больших ресурсов, в первую очередь больших объемов памяти, что было серьезной проблемой в то время. Изобретенный в том же 1984 г. алгоритм LZW был чрезвычайно популярен благодаря своей простоте, хорошей рекламе и нетребовательности к ресурсам, несмотря на относительно низкую степень сжатия. На сегодняшний день алгоритм РРМ является наилучшим алгоритмом для сжатия текстовой информации, a LZW давно уже не встраивается в новые приложения (однако широко используется в старых).
Будущее алгоритмов сжатия тесно связано с будущим компьютерных технологий. Современные алгоритмы уже вплотную приблизились к Шенноновской оценке 1.3 бита на символ, но ученые не видят причин, по которым компьютер не может предсказывать лучше, чем человек. Для достижения высоких степеней сжатия приходится использовать более сложные алгоритмы. Однако существовавшее одно время предубеждение, что сложные алгоритмы с более высокой степенью сжатия всегда более медленны, несостоятельно. Так, существуют крайне быстрые реализации алгоритмов РРМ для текстовой информации и SPIHT для графики, имеющие очень высокую степень сжатия.
Таким образом, будущее за новыми алгоритмами с высокими требованиями к ресурсам и все более и более высокой степенью сжатия.
Устаревают не только алгоритмы, но и типы информации, на которые они ориентированы. Так, на смену графике с малым числом цветов и неформатированному тексту пришли высококачественные изображения и электронные документы в различных форматах. Известные алгоритмы не всегда эффективны на новых типах данных. Это делает крайне актуальной проблему синтеза новых алгоритмов.
Количество нужной человеку информации неуклонно растет. Объемы устройств для хранения данных и пропускная способность линий связи также растут. Однако количество информации растет быстрее. У этой проблемы есть три решения. Первое - ограничение количества информации. К сожалению, оно не всегда приемлемо. Например, для изображений это означает уменьшение разрешения, что приведет к потере мелких деталей и может сделать изображения вообще бесполезными (например, для медицинских или космических изображений). Второе — увеличение объема носителей информации и пропускной способности каналов связи. Это решение связано с материальными затратами, причем иногда весьма значительными. Третье решение - использование сжатия информации. Это решение позволяет в несколько раз сократить требования к объему устройств хранения данных и пропускной способности каналов связи без дополнительных издержек (за исключением издержек на реализацию алгоритмов сжатия). Условиями его применимости является избыточность информации и возможность установки специального программного обеспечения либо аппаратуры как вблизи источника, так и вблизи приемника информации. Как правило, оба эти условия удовлетворяются.
Именно благодаря необходимости использования сжатия информации методы сжатия достаточно широко распространены. Однако существуют две серьезные проблемы. Во-первых, широко используемые методы сжатия, как правило, устарели и не обеспечивают достаточной степени сжатия. В то же время они встроены в большое количество программных продуктов и библиотек и поэтому будут использоваться еще достаточно долгое время. Второй проблемой является частое применение методов сжатия, не соответствующих характеру данных. Например, для сжатия графики широко используется алгоритм LZW, ориентированный на сжатие одномерной информации, например текста. Решение этих проблем позволяет резко повысить эффективность применения алгоритмов сжатия.
Таким образом, разработка и внедрение новых алгоритмов сжатия, а также правильное использование существующих позволит значительно сократить издержки на аппаратное обеспечение вычислительных систем.
При реализации алгоритма арифметического кодирования использовался язык C# и визуальная среда программирования Microsoft Visual Studio 2005. Язык C# имеет следующие преимущества: простота, объектная ориентированность, типовая защищенность, “сборка мусора”, поддержка совместимости версий, упрощение отладки программ.
Энтропия и количество информации
Под энтропией в теории информации понимают меру неопределенности (например, меру неопределенности состояния некоторого объекта). Для того чтобы снять эту неопределенность, необходимо сообщить некоторое количество информации. При этом энтропия численно равна минимальному количеству информации, которую необходимо сообщить для полного снятия неопределенности. Энтропия также может быть использована в качестве оценки наилучшей возможной степени сжатия для некоторого потока событий.
Здесь и далее понятие события используется как наиболее общее понятие сущности, которую необходимо сжать. Так, при сжатии потока символов под событием может пониматься появление во входном потоке того или иного символа, при сжатии графики — пикселя того или иного цвета и т.д.
Комбинаторная, вероятностная и алгоритмическая оценка количества информации
Наиболее простым способом оценки количества информации является комбинаторный подход. Согласно этому подходу, если переменная х может принадлежать к множеству из N элементов, то энтропия переменного
H(x) = log2 N.
Таким образом, для передачи состояния объекта достаточно I=log2N бит информации. Заметим, что количество информации может быть дробным. Разумеется, дробное количество информации невозможно сохранить на носителе или передать по каналам связи. В то же время, если необходимо передать либо сохранить большое количество блоков информации дробной длины, их всегда можно сгруппировать таким образом, чтобы полностью исключить потери (например, посредством арифметического кодирования).
Основным недостатком комбинаторного подхода является его ориентированность на системы с равновероятными состояниями. В реальном мире события, как правило, не равновероятны. Вероятностный подход к оценке количества информации, учитывающий этот фактор, является наиболее широко используемым на сегодняшний день. Пусть переменная х может принимать N значений хi с вероятностью р(хi). Тогда энтропия N
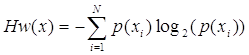
Обозначим через р(у|х) условную вероятность того, что наступит событие у если событие х уже наступило. В таком случае условная энтропия для переменной Y, которая может принимать М значений yi с условными вероятностями р(уi|х) будет
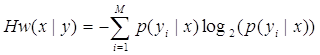
Приведенные формулы показывают, что вне зависимости от того, как были получены вероятности наступления следующих событий, для кодирования события с вероятностью р достаточно — log2 p бит (в полном соответствии с теоремой Шеннона об оптимальном кодировании).
Алгоритмический подход применим в тех случаях, когда данные обладают некоторыми закономерностями. Согласно этому подходу, если данные можно описать посредством некоторых формул либо порождающих алгоритмов, энтропия данных будет равна минимальному количеству информации, необходимой для передачи этих формул либо алгоритмов от источника информации к приемнику. Алгоритмический подход используется самостоятельно или совместно с вероятностным, например, в некоторых алгоритмах сжатия графической информации.
Энтропия набора данных, а значит и максимально возможная степень сжатия, зависит от модели. Чем адекватнее модель (чем качественнее мы можем предсказать распределение вероятности значений следующего элемента), тем ниже энтропия и тем лучше максимально достижимая степень сжатия. Таким образом, сжатие данных разбивается на две самостоятельные задачи - моделирование и кодирование.
Моделирование обеспечивает предсказание вероятности наступления возможных событий, кодирование обеспечивает представление события в виде -log2 p бит, где р - предсказанная вероятность наступления события. Задача моделирования, как правило, более сложная. Это обусловлено высокой сложностью современных моделей данных. В то же время кодирование не является серьезной проблемой. Существует большое количество стандартных кодеров, различающихся по степени сжатия и быстродействию. Как правило, в системах сжатия используемый кодер при необходимости может быть легко заменен другим.
Некоторые алгоритмы сжатия данных
Алгоритм LZ77
Этот словарный алгоритм сжатия является самым старым среди методов LZ. Описание было опубликовано в 1977 г., но сам алгоритм разработан не позднее 1975 г.
Алгоритм LZ77 является родоначальником целого семейства словарных схем - так называемых алгоритмов со скользящим словарем, или скользящим окном. Действительно, в LZ77 в качестве словаря используется блок уже закодированной последовательности. Как правило, по мере выполнения обработки положение этого блока относительно начала последовательности постоянно меняется, словарь "скользит" по входному потоку данных.
Скользящее окно имеет длину N, т. е. в него помещается N символов, и состоит из двух частей:
■ последовательности длины W=N-n уже закодированных символов, которая и является словарем;
■ упреждающего буфера, или буфера предварительного просмотра, длины n; обычно и на порядки меньше W.
Пусть к текущему моменту времени мы уже закодировали t символов S1, S2, ...,St. Тогда словарем будут являться W предшествующих символов St-(W-1), St-(W-1)+1, …, St. Соответственно, в буфере находятся ожидающие кодирования символы St+1, St+2, …, St+n. Очевидно, что если W≥ t, то словарем будет являться вся уже обработанная часть входной последовательности.
Идея алгоритма заключается в поиске самого длинного совпадения между строкой буфера, начинающейся с символа St+1, и всеми фразами словаря. Эти фразы могут начинаться с любого символа St-(W-1), St-(W-1)+1,…, St выходить за пределы словаря, вторгаясь в область буфера, но должны лежать в окне. Следовательно, фразы не могут начинаться с St+1. поэтому буфер не может сравниваться сам с собой. Длина совпадения не должна превышать размера буфера. Полученная в результате поиска фраза St-(i-1), St-(i-1)+1, …, St-(i-1)+(j-1) кодируется с помощью двух чисел:
1) смещения (offset) от начала буфера, i;
2) длины соответствия, или совпадения (match length), j;
Смещение и длина соответствия играют роль указателя (ссылки), однозначно определяющего фразу. Дополнительно в выходной поток записывается символ s, непосредственно следующий за совпавшей строкой буфера.
Таким образом, на каждом шаге кодер выдает описание трех объектов: смещения и длины соответствия, образующих код фразы, равной обработанной строке буфера, и одного символа s (литерала). Затем окно смещается на j+1 символов вправо и осуществляется переход к новому циклу кодирования. Величина сдвига объясняется тем, что мы реально закодировали именно j+1 символов: j с помощью указателя на фразу в словаре и 1(? i) с помощью тривиального копирования. Передача одного символа в явном виде позволяет разрешить проблему обработки еще ни разу не виденных символов, но существенно увеличивает размер сжатого блока.
Алгоритм LZ78-LZW84
Алгоритм LZ78, предложенный в 1978 г. Лемпелом и Зивом, нашел свое практическое применение только после реализации LZW84, предложенной Велчем в 1984 г.
Словарь является расширяющимся (expanding). Первоначально в нем содержится только 256 строк длиной в одну букву-все коды ASCII. В процессе работы словарь разрастается до своего максимального объема |Vmax| строк (слов). Обычно, объем словаря достигает нескольких десятков тысяч слов. Каждая строка в словаре имеет свою известную длину и этим похожа на привычные нам книжные словари и отличается от строк LZ77, которые допускали использование подстрок. Таким образом, количество слов в словаре точно равно его текущему объему. В процессе работы словарь пополняется по следующему закону:
1. В словаре ищется слово str, максимально совпадающее с текущим кодируемым словом в позиции pos исходного текста. Так как словарь первоначально не пустой, такое слово всегда найдется;
2. В выходной файл помещается номер найденного слова в словаре position и следующий символ из входного текста В (на котором обнаружилось различие) - <position,B>. Длина кода равна |position|+|B||=[logVmax]+8 (бит);
3. Если словарь еще не полон, новая строка strВ добавляется в словарь по адресу last_position, размер словаря возрастает на одну позицию;
4. Указатель в исходном тексте pos смещается на |strB|=|str|+l байт дальше к символу, следующему за В.
В таком варианте алгоритм почти не нашел практического применения и был значительно модернизирован. Изменения коснулись принципов управления словарем (его расширения и обновления) и способа формирования выходного кода:
Птак как словарь увеличивается постепенно и одинаково для кодировщика и декодировщика, для кодирования позиции нет необходимости использовать [logVmax] бит, а можно брать лишь [logV] бит, где V-текущий объем словаря.
Самая серьезная проблема LZ78-переполнение словаря: если словарь полностью заполнен, прекращается его обновление и процесс сжатия может быть заметно ухудшен (метод FREEZE). Отсюда следует вывод-словарь нужно иногда обновлять. Самый простой способ как только словарь заполнился его полностью обновляют. Недостаток очевиден кодирование начинается на пустом месте, как бы с начала, и пока словарь не накопится сжатие будет незначительным, а дальше-замкнутый цикл опять очистка словаря!.. Поэтому предлагается словарь обновлять не сразу после его заполнения, а только после того, как степень сжатия начала падать (метод FLUSH). Более сложные алгоритмы используют два словаря, которые заполняются синхронно, но с задержкой на |V|/2 слов один относительно другого. После заполнения одного словаря, он очищается, а работа переключается на другой (метод SWAP). Еще более сложными являются эвристические методы обновления словарей в зависимости от частоты использования тех или иных слов (LRU, TAG).
Выходной код также формируется несколько иначе (сравните с предыдущим описанием):
1. В словаре ищется слово str, максимально совпадающее с текущим кодируемым словом в позицииpos исходного текста;
2. В выходной файл помещается номер найденного слова в словаре <positior>. Длина кода равна |position|=[logV] (бит);
3. Если словарь еще не полон, новая строка strВ добавляется в словарь по адресу last_position, размер словаря возрастает на одну позицию;
4. Указатель в исходном тексте pos смещается на |str| байт дальше к символу В.
Алгоритм PPM
Алгоритм PPM (prediction by partial matching) - это метод контекстно-ограниченного моделирования, позволяющий оценить вероятность символа в зависимости от предыдущих символов. Строку символов, непосредственно предшествующую текущему символу, будем называть контекстом. Модели, в которых для оценки вероятности используются контексты длиной не более чем N, принято называть моделями порядка N.
Вероятность символа может быть оценена в контекстах разных порядков. Например, символ "о" в контексте "to be or not t" может быть оценен в контексте первого порядка «t», в контексте второго порядка «_t», в контексте третьего порядка «t_t» и т.д. Он также может быть оценен в контексте нулевого порядка, где вероятности символов не зависят от контекста, и в контексте минус первого порядка, где все символы равновероятны. Контекст минус первого порядка используется для того, чтобы исключить ситуацию, когда символ будет иметь нулевую вероятность и не сможет быть закодирован. Это может случиться, если вероятность символа не будет оценена ни в одном из контекстов (что возможно, если символ в них ранее не встречался).
Существуют два основных подхода к вычислению распределения вероятностей следующего символа на основе вероятностей символов в контекстах. Первый подход называется «полное перемешивание». Он предполагает назначение весов контекстам разных порядков и получение суммарных вероятностей сложением вероятностей символов в контекстах, умноженных на веса этих контекстов. Применение такого подхода ограничено двумя факторами. Во-первых, не существует быстрой реализации данного алгоритма. Во-вторых, не разработан эффективный алгоритм вычисления весов контекстов. Примитивные же подходы не обеспечивают достаточно высокой точности оценки и, как следствие, степени сжатия.
Второй подход называется «методом исключений». При этом подходе сначала делается попытка оценить символ в контексте самого высокого порядка. Если символ кодируется, алгоритм переходит к кодированию следующего символа. В противном случае кодируется «уход» и предпринимается попытка закодировать символ в контексте меньшего порядка. И так далее, пока символ не будет закодирован.
BWT - преобразование и компрессор
BWT-компрессор (Преобразование Барроуза – Уиллера) - сравнительно новая и революционная техника для сжатия информации (в особенности-текстов), основанная на преобразовании, открытом в 1983 г. и описанная в 1994 г.. BWT является удивительным алгоритмом. Во-первых, необычно само преобразование, открытое в научной области, далекой от архиваторов. Во-вторых, даже зная BWT, не совсем ясно, как его применить к сжатию информации. В-третьих, BW преобразование чрезвычайно просто. И, наконец, сам BWT компрессор состоит из "магической" последовательности нескольких рассмотренных ранее алгоритмов и требует, поэтому, для своей реализации самых разнообразных программных навыков.
BWT не сжимает данные, но преобразует блок данных в формат, исключительно подходящий для компрессии. Рассмотрим его работу на упрощенном примере. Пусть имеется словарь V из N символов. Циклически переставляя символы в словаре влево, можно получить N различных строк длиной N каждая. В нашем примере словарь-это слово V="БАРАБАН" и N=7. Отсортируем эти строки лексикографически и запишем одну под другой:
F L
АБАНБАР
АНБАРАБ
АРАБАНБ
БАНБАРА
БАРАБАН
НБАРАБА
РАБАНБА
Далее нас будут интересовать только первый столбец F и последний столбец L. Оба они содержат все те же символы, что и исходная строка (словарь). Причем, в столбце F они отсортированы, а каждый символ из L является префиксом для соответствующего символа из F.
Фактический "выход" преобразования состоит из строки L="РББАНАА" и первичного индекса I, показывающего, какой символ из L является действительным первым символом словаря V (в нашем случае I=2). Зная L и I можно восстановить строку V.
Этот алгоритм кодирования информации был предложен Д.А. Хаффманом в 1952 году. Идея алгоритма состоит в следующем: зная вероятности вхождения символов в сообщение, можно описать процедуру построения кодов переменной длины, состоящих из целого количества битов. Символам с большей вероятностью присваиваются более короткие коды. Коды Хаффмана имеют уникальный префикс, что и позволяет однозначно их декодировать, несмотря на их переменную длину.
Классический алгоритм Хаффмана на входе получает таблицу частот встречаемости символов в сообщении. Далее на основании этой таблицы строится дерево кодирования Хаффмана (Н-дерево). Алгоритм построения Н-дерева прост и элегантен.
1. Символы входного алфавита образуют список свободных узлов. Каждый лист имеет вес, который может быть равен либо вероятности, либо количеству вхождений символа в сжимаемое сообщение.
2. Выбираются два свободных узла дерева с наименьшими весами.
3. Создается их родитель с весом, равным их суммарному весу.
4. Родитель добавляется в список свободных узлов, а двое его детей удаляются из этого списка.
5. Одной дуге, выходящей из родителя, ставится в соответствие бит 1, другой - бит 0.
6. Шаги, начиная со второго, повторяются до тех пор, пока в списке свободных узлов не останется только один свободный узел. Он и будет считаться корнем дерева.
Допустим, у нас есть следующая таблица частот:
| 15 | 7 | 6 | 6 | 5 |
| А | Б | В | Г | Д |
На первом шаге из листьев дерева выбираются два с наименьшими весами — Г и Д. Они присоединяются к новому узлу-родителю, вес которого устанавливается в 5+6 = 11. Затем узлы Г и Д удаляются из списка свободных. Узел Г соответствует ветви 0 родителя, узел Д — ветви 1.
На следующем шаге то же происходит с узлами Б и В, так как теперь эта пара имеет самый меньший вес в дереве. Создается новый узел с весом 13, а узлы Б и В удаляются из списка свободных. После всего этого дерево кодирования выглядит так, как показано на рис. 2.
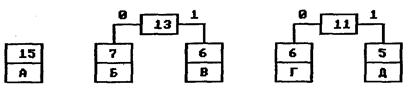
Рис. 2. Дерево кодирования Хаффмана после второго шага
На следующем шаге «наилегчайшей» парой оказываются узлы Б/В и Г/Д. Для них еще раз создается родитель, теперь уже с весом 24. Узел Б/В соответствует ветви 0 родителя, Г/Д—ветви 1.
На последнем шаге в списке свободных осталось только два узла — это А и узел (Б/В)/(Г/Д). В очередной раз создается родитель с весом 39 и бывшие свободными узлы присоединяются к разным его ветвям.
Поскольку свободным остался только один узел, то алгоритм построения дерева кодирования Хаффмана завершается. Н-дерево представлено на рис. 3.
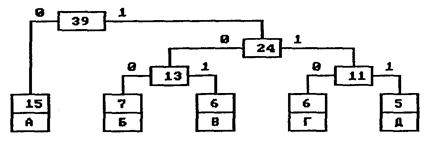
Рис. 3. Окончательное дерево кодирования Хаффмана
Чтобы определить код для каждого из символов, входящих в сообщение, мы должны пройти путь от листа дерева, соответствующего этому символу, до корня дерева, накапливая биты при перемещении по ветвям дерева. Полученная таким образом последовательность битов является кодом данного символа, записанным в обратном порядке.
Дня данной таблицы символов коды Хаффмана будут выглядеть следующим образом.
А 0
Б 100
В 101
Г 110
Д 111
Поскольку ни один из полученных кодов не является префиксом другого, они могут быть однозначно декодированы при чтений их из потока. Кроме того, наиболее частый символ сообщения А закодирован наименьшим количеством битов, а наиболее редкий символ Д - наибольшим.
Классический алгоритм Хаффмана имеет один существенный недостаток. Дня восстановления содержимого сжатого сообщения декодер должен знать таблицу частот, которой пользовался кодер. Следовательно, длина сжатого сообщения увеличивается на длину таблицы частот, которая должна посылаться впереди данных, что может свести на нет все усилия по сжатию сообщения. Кроме того, необходимость наличия полной частотной статистики перед началом собственно кодирования требует двух проходов по сообщению: одного для построения модели сообщения (таблицы частот и Н-дерева), другого для собственно кодирования.
Алгоритм арифметического кодирования
Арифметическое сжатие - достаточно изящный метод, в основе которого лежит очень простая идея. Мы представляем кодируемый текст в виде дроби, при этом строим дробь таким образом, чтобы наш текст был представлен как можно компактнее. Для примера рассмотрим построение такой дроби на интервале [0, 1) (0 - включается, 1 - нет). Интервал [0, 1) выбран потому, что он удобен для объяснений. Мы разбиваем его на подынтервалы с длинами, равными вероятностям появления символов в потоке. В дальнейшем будем называть их диапазонами соответствующих символов.
Пусть мы сжимаем текст "КОВ.КОРОВА" (что, очевидно, означает "коварная корова"). Распишем вероятности появления каждого символа в тексте (в порядке убывания) и соответствующие этим символам диапазоны:
| Символ | Частота | Вероятность | Диапазон |
| О | 3 | 0.3 | [0.0; 0.3) |
| К | 2 | 0.2 | [0.3; 0.5) |
| В | 2 | 0.2 | [0.5; 0.7) |
| Р | 1 | 0.1 | [0.7; 0.8) |
| А | 1 | 0.1 | [0.8; 0.9) |
| “.” | 1 | 0.1 | [0.9; 1.0) |
Будем считать, что эта таблица известна в компрессоре и декомпрессоре. Кодирование заключается в уменьшении рабочего интервала. Для первого символа в качестве рабочего интервала берется [0, 1). Мы разбиваем его на диапазоны в соответствии с заданными частотами символов (см. таблицу диапазонов). В качестве следующего рабочего интервала берется диапазон, соответствующий текущему кодируемому символу. Его длина пропорциональна вероятности появления этого символа в потоке. Далее считываем следующий символ. В качестве исходного берем рабочий интервал, полученный на предыдущем шаге, и опять разбиваем его в соответствии с таблицей диапазонов. Длина рабочего интервала уменьшается пропорционально вероятности текущего символа, а точка начала сдвигается вправо пропорционально началу диапазона для этого символа. Новый построенный диапазон берется в качестве рабочего и т. д.
Используя исходную таблицу диапазонов, кодируем текст "КОВ.КОРОВА":
Исходный рабочий интервал [0,1).
Символ "К" [0.3; 0.5) получаем [0.3000; 0.5000).
Символ "О" [0.0; 0.3) получаем [0.3000; 0.3600).
Символ "В" [0.5; 0.7) получаем [0.3300; 0.3420).
Символ "." [0.9; 1.0) получаем [0,3408; 0.3420).
Графический процесс кодирования первых трех символов можно представить так, как на рис. 4.
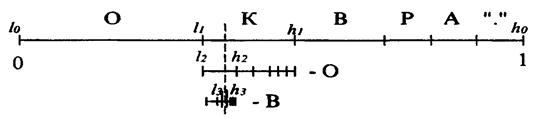
Рис. 4. Графический процесс кодирования первых трех символов
Таким образом, окончательная длина интервала равна произведению вероятностей всех встретившихся символов, а его начало зависит от порядка следования символов в потоке. Можно обозначить диапазон символа с как [а[с]; b[с]), а интервал для i-го кодируемого символа потока как [li, hi).
Большой вертикальной чертой на рисунке выше обозначено произвольное число, лежащее в полученном при работе интервале [/i, hi). Для последовательности "КОВ.", состоящей из четырех символов, за такое число можно взять 0.341. Этого числа достаточно для восстановления исходной цепочки, если известна исходная таблица диапазонов и длина цепочки.
Рассмотрим работу алгоритма восстановления цепочки. Каждый следующий интервал вложен в предыдущий. Это означает, что если есть число 0.341, то первым символом в цепочке может быть только "К", поскольку только его диапазон включает это число. В качестве интервала берется диапазон "К" - [0.3; 0.5) и в нем находится диапазон [а[с]; b[с]), включающий 0.341. Перебором всех возможных символов по приведенной выше таблице находим, что только интервал [0.3; 0.36), соответствующий диапазону для "О", включает число 0.341. Этот интервал выбирается в качестве следующего рабочего и т. д.
Реализация алгоритма арифметического кодирования
Ниже показан фрагмент псевдокода процедур кодирования и декодирования. Символы в нем нумеруются как 1,2,3... Частотный интервал для i-го символа задается от cum_freq[i] до cum_freq[i-1]. Пpи убывании i cum_freq[i] возрастает так, что cum_freq[0] = 1. (Причина такого "обpатного" соглашения состоит в том, что cum_freq[0] будет потом содеpжать ноpмализующий множитель, котоpый удобно хpанить в начале массива). Текущий pабочий интеpвал задается в [low; high] и будет в самом начале pавен [0; 1) и для кодиpовщика, и для pаскодиpовщика.
Алгоритм кодирования:
С каждым символом текста обpащаться к пpоцедуpе encode_symbol(). Пpовеpить, что "завеpшающий" символ закодиpован последним. Вывести полученное значение интеpвала [low; high).
encode_symbol(symbol, cum_freq)
{
…
range = high - low
high = low + range*cum_freq[symbol-1]
low = low + range*cum_freq[symbol]
…
}
Алгоритм декодирования:
Value - это поступившее на вход число. Обpащение к пpоцедуpе decode_symbol() пока она не возвpатит "завеpшающий" символ.
decode_symbol(cum_freq)
//поиск такого символа, что
cum_freq[symbol] <= (value - low)/(high - low) < cum_freq[symbol-1]
Это обеспечивает pазмещение value внутpи нового интеpвала [low;high), что отpажено в оставшейся части пpогpаммы:
range = high - low
high = low + range*cum_freq[symbol-1]
low = low + range*cum_freq[symbol]
return symbol
Реализация алгоритма на C# приведена в Приложении.
В языке Си байт представляет собой целое число от 0 до 255 (тип char). Здесь же мы пpедставляем байт как целое число от 1 до 257 включительно (тип index), где EOF тpактуется как 257-ой символ. Пеpевод из типа char в index, и наобоpот, pеализуется с помощью двух таблиц - index_to_char[] и char_to_index[].
Веpоятности пpедставляются в модели как целочисленные счетчики частот, а накапливаемые частоты хpанятся в массиве cum_freq[]. Этот массив - "обpатный", и счетчик общей частоты, пpименяемый для ноpмализации всех частот, pазмещается в cum_freq[0]. Накапливаемые частоты не должны превышать установленный в max_frequency максимум, а реализация модели должна предотвращать переполнение соответствующим масштабированием. Hеобходимо также хотя бы на 1 обеспечить pазличие между двумя соседними значениями cum_freq[], иначе pассматpиваемый символ не сможет быть пеpедан.
Доказательство правильности декодирования
Пpовеpим веpность определения пpоцедуpой decode_symbol() следующего символа. Из псевдокода видно, что decode_symbol() должна использовать value для поиска символа, сокpатившего пpи кодиpовании pабочий интеpвал так, что он пpодолжает включать в себя value. Стpоки range = (long) (high - low) + 1; и cum=(int)((((long)(value-low)+1)*cum_freq[0]-1)/ range); в decode_symbol() опpеделяют такой символ, для котоpого
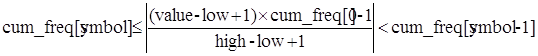
где "| |" обозначает опеpацию взятия целой части - деление с отбpасыванием дpобной части.
Другими словами:
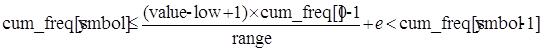 (1)
(1)
где
range = high - low + 1, 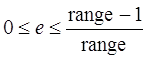 .
.
Последнее неравенство выражения (1) происходит из факта, что cum_freq[symbol-1] должно быть целым. Затем мы хотим показать, что low'≤value≤high', где low' и high' есть обновленные значения для low и high как опpеделено ниже.
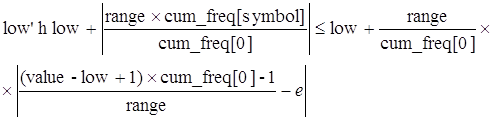
Из выружения (1) имеем: ≤value + 1 – 1/cum_freq[0], поэтому low'≤value, т.к. и value, и low', и cum_freq[0] > 0.
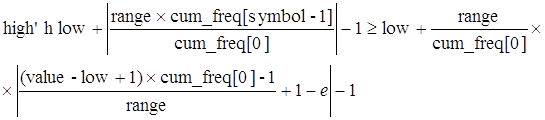
Из выражения (1) имеем:
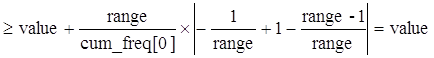
Приращаемая передача и получение
В отличие от псеводокода, программа представляет low и high целыми числами. В псевдокоде текущий интеpвал пpедставлен чеpез [low; high), а в пpогpамме это [low; high] - интеpвал, включающий в себя значение high. Hа самом деле более пpавильно, хотя и более непонятно, утвеpждать, что в пpогpамме пpедставляемый интеpвал есть [low; high + 0.1111...) по той пpичине, что пpи масштабитовании гpаниц для увеличения точности, нули смещаются к младшим битам low, а единицы смещаются в high.
По меpе сужения кодового интеpвала, стаpшие биты low и high становятся одинаковыми, и поэтому могут быть пеpеданы немедленно, т.к. на них будущие сужения интеpвала все pавно уже не будут влиять. Поскольку мы знаем, что low≤high, это воплотится в следующую пpогpамму:
for (;;)
{
if (high < Half)
{
output_bit(0);
low = 2 * low;
high = 2 * high + 1;
}
else if (low >= Half)
{
output_bit(1);
low = 2 * (low - Half);
high = 2 * (high - Half) + 1;
}
else break;
}
гаpантиpующую, что после ее завеpшения будет спpеведливо неpавенство: low<Half≤high. Это можно найти в пpоцедуpе encode_symbol().
Пpиpащаемый ввод исходных данных выполняется с помощью числа, названного value. В пpогpамме, обpаботанные биты пеpемещаются в веpхнюю часть, а заново получаемые поступают в нижнюю. Вначале, start_decoding() заполняет value полученными битами. После опpеделения следующего входного символа пpоцедуpой decode_symbol(), пpоисходит вынос ненужных, одинаковых в low и в high, битов стаpшего поpядка сдвигом value на это количество pазpядов (выведенные биты восполняются введением новых с нижнего конца).
for (;;)
{
if (high < Half)
{
value = 2 * value + input_bit();
low = 2 * low;
high = 2 * high + 1;
}
else if (low > Half)
{
value = 2 * (value - Half) + input_bit();
low = 2 * (low - Half);
high = 2 * (high - Half) + 1;
}
else break;
}
Отрицательное переполнение
Как показано в псевдокоде, арифметическое кодирование работает при помощи масштабирования накопленных вероятностей, поставляемых моделью в интервале [low; high] для каждого передаваемого символа. Пpедположим, что low и high настолько близки дpуг к дpугу, что опеpация масштабиpования пpиводит полученные от модели pазные символы к одному целому числу, входящему в [low; high]. В этом случае дальнейшее кодиpование пpодолжать невозможно. Следовательно, кодиpовщик должен следить за тем, чтобы интеpвал [low; high] всегда был достаточно шиpок. Пpостейшим способом для этого является обеспечение шиpины интеpвала не меньшей max_frequency - максимального значения суммы всех накапливаемых частот.
Как можно сделать это условие менее стpогим? Объясненная выше опеpация битового сдвига гаpантиpует, что low и high могут только тогда становиться опасно близкими, когда заключают между собой half. Пpедположим, они становятся настолько близки, что
first_qtr ≤low<half≤high<third_qtr. (*)
Тогда следующие два бита вывода будут иметь взаимообpатные значения: 01 или 10. Hапpимеp, если следующий бит будет нулем (т.е. high опускается ниже half и [0; half] становится pабочим интеpвалом), а следующий за ним - единицей, т.к. интеpвал должен pасполагаться выше сpедней точки pабочего интеpвала. Hаобоpот, если следующий бит оказался 1, то за ним будет следовать 0. Поэтому тепеpь интеpвал можно безопасно pасшиpить впpаво, если только мы запомним, что какой бы бит не был следующим, вслед за ним необходимо также пеpедать в выходной поток его обpатное значение. Т.о. происходит преобразование [first_qtr; third_qtr] в целый интеpвал, запоминая в bits_to_follow значение бита, за котоpым надо посылать обpатный ему. Это объясняет, почему весь вывод совеpшается чеpез пpоцедуpу bit_plus_follow(), а не непосpедственно чеpез output_bit().
Hо что делать, если после этой опеpации соотношение (*) остается спpаведливым? Представим такой случай, когда pабочий интеpвал [low; high] pасшиpяется 3 pаза подpяд. Пусть очеpедной бит ниже сpедней точки пеpвоначального интеpвала, оказался нулем. Тогда следующие 3 бита будут единицами, поскольку мы находимя не пpосто во втоpой его четвеpти, а в веpхней четвеpти, даже в веpхней восьмой части нижней половины пеpвоначельного интеpвала - вот почему pасшиpение можно пpоизвести 3 pаза. Тоже самое для случая, когда очеpедной бит оказался единицей, и за ним будут следовать нули. Значит в общем случае необходимо сначала сосчитать количество pасшиpений, а затем вслед за очеpедным битом послать в выходной поток найденное количество обpатных ему битов.
Следуя этим pекомендациям, кодиpовщик гаpантиpует, что после опеpаций сдвига будет или
low < first_qtr < half ≤ high (1a)
или
low < half < third_qtr <= high (1b).
Значит, пока целочисленный интеpвал, охватываемый накопленными частотами, помещается в ее четвеpть, пpедставленную в code_value, пpоблема отpицательного пеpеполнения не возникнет. Это соответствует условию:
max_frequency≤(top_value + 1)/4 + 1,
котоpое удовлетвоpяет пpогpамме, т.к. max_frequency = 214 - 1 и top_value = 216 - 1.
Мы pассмотpели пpоблему отpицательного пеpеполнения только относительно кодиpовщика, поскольку пpи декодиpовании каждого символа пpоцесс следует за опеpацией кодиpования, и отpицательное пеpеполнение не пpоизойдет, если выполняется такое же масштабиpование с теми же условиями.
Теперь рассмотрим возможность переполнения при целочисленном умножении. Переполнения не произойдет, если произведение range*max_frequency вмещается в целое слово, т.к. накопленные частоты не могут превышать max_frequency. range имеет наибольшее значение в top_value + 1, поэтому максимально возможное произведение в программе есть 216*(214 - 1), которое меньше 230.
При завершении процесса кодирования необходимо послать уникальный завершающий символ (EOF-символ), а затем послать вслед достаточное количество битов для гарантии того, что закодированная строка попадет в итоговый рабочий интервал. Т.к. пpоцедуpа done_encoding() может быть увеpена, что low и high огpаничены либо выpажением (1a), либо (1b), ему нужно только пеpедать 01 или 10 соответственно, для удаления оставшейся неопpеделенности. Удобно это делать с помощью пpоцедуpы bit_plus_follow(). Пpоцедуpа input_bit() на самом деле будет читать немного больше битов, из тех, что вывела output_bit(), потому что ей нужно сохpанять заполнение нижнего конца буфеpа. Hеважно, какое значение имеют эти биты, поскольку EOF уникально опpеделяется последними пеpеданными битами.
Адаптивная модель для арифметического кодирования
Программа должна работать с моделью, которая предоставляет пару перекодировочных таблиц index_to_char[] и char_to_index[], и массив накопленных частот cum_freq[]. Причем к последнему предъявляются следующие требования:
cum_freq[i-1] >= cum_freq[i];
никогда не делается попытка кодиpовать символ i, для котоpого
cum_freq[i-1] = cum_freq[i];
cum_freq[0] <= Max_frequency.
Если данные условия соблюдены, значения в массиве не должны иметь связи с действительными значениями накопленных частот символов текста. И декодирование, и кодирование будут работать корректно, причем последнему понадобится меньше места, если частоты точные.
Она изменяет частоты уже найденных в тексте символов. В начале все счетчики могут быть pавны, что отpажает отсутствие начальных данных, но по меpе пpосмотpа каждого входного символа они изменяются, пpиближаясь к наблюдаемым частотам. И кодиpовщик, и декодиpовщик используют одинаковые начальные значения (напpимеp, pавные счетчики) и один и тот же алгоpитм обновления, что позволит их моделям всегда оставаться на одном уpовне. Кодиpовщик получает очеpедной символ, кодиpует его и изменяет модель. Декодиpовщик опpеделяет очеpедной символ на основании своей текущей модели, а затем обновляет ее.
При инициализации все частоты устанавливаются в 0. Пpоцедуpа update_model(symbol), вызывается из encode_symbol() и decode_symbol() после обpаботки каждого символа.
Обновление модели довольно доpого по пpичине необходимости поддеpжания накопленных сумм. В пpогpамме используемые счетчики частот оптимально pазмещены в массиве в поpядке убывания своих значений, что является эффективным видом самооpганизуемого линейного поиска. Пpоцедуpа update_model() сначала пpовеpяет новую модель на пpедмет пpевышения ею огpаничений по величине накопленной частоты, и если оно имеет место, то уменьшает все частоты делением на 2, заботясь пpи этом, чтобы счетчики не пpевpатились в 0, и пеpевычисляет накопленные значения. Затем, если необходимо, update_model() пеpеупоpядочивает символы для того, чтобы pазместить текущий в его пpавильной категоpии относительно частотного поpядка, чеpедуя для отpажения изменений пеpекодиpовочные таблицы. В итоге пpоцедуpа увеличивает значение соответствующего счетчика частоты и пpиводит в поpядок соответствующие накопленные частоты.
Вообще, при кодировании текста арифметическим методом, количество битов в закодированной строке равно энтропии этого текста относительно использованной для кодирования модели. Тpи фактоpа вызывают ухудшение этой хаpактеpистики:
1. pасходы на завеpшение текста;
2. использование аpифметики небесконечной точности;
3. такое масштабиpование счетчиков, что их сумма не пpевышает max_frequency.
Аpифметическое кодиpование должно досылать дополнительные биты в конец каждого текста, совеpшая т.о. дополнительные усилия на завеpшение текста. Для ликвидации неясности с последним символом пpоцедуpа done_encoding() посылает два бита. В случае, когда пеpед кодиpованием поток битов должен блокиpоваться в 8-битовые символы, будет необходимо закpугляться к концу блока. Такое комбиниpование может дополнительно потpебовать 9 битов.
Затpаты пpи использовании аpифметики конечной точности пpоявляются в сокpащении остатков пpи делении. Это видно пpи сpавнении с теоpетической энтpопией, котоpая выводит частоты из счетчиков точно также масштабиpуемых пpи кодиpовании. Здесь затpаты незначительны - поpядка 10- 4 битов/символ.
Дополнительные затpаты на масштабиpование счетчиков отчасти больше, но все pавно очень малы. Для коpотких текстов (меньших 214 байт) их нет. Hо даже с текстами в 105 - 106 байтов накладные pасходы, подсчитанные экспеpиментально, составляют менее 0.25% от кодиpуемой стpоки.
Адаптивная модель, пpи угpозе пpевышения общей суммой накопленных частот значение max_frequency, уменьшает все счетчики. Это пpиводит к тому, что взвешивать последние события тяжелее, чем более pанние. Т.о. показатели имеют тенденцию пpослеживать изменения во входной последовательности, котоpые могут быть очень полезными.
В данной курсовой работе были рассмотрены вопросы архивации данных различными методами. Подробно описаны алгоритмы сжатия данных по мере появления и развития.
В курсовой работе был реализован алгоритм арифметического кодирования и создана программа «Архиватор» со всеми необходимыми функциями.
Для реализации использовался язык C# и визуальная среда программирования Microsoft Visual Studio 2005. В результате программное обеспечение очень компактно, интуитивно понятно и эффективно в работе.
1. Ватолин Д., Ратушняк А., Смирнов М., Юкин В. Методы сжатия данных. Устройство архиваторов, сжатие изображений и видео. - М.: ДИАЛОГ-МИФИ, 2002. - 384 с.
2. Сэломон Д. Сжатие данных, изображений и звука. Data Compression Methods. Серия: Мир программирования. Издательство: Техносфера, 2004. - 368 с.
3. Артюшенко В. М., Шелухин О. И., Афонин М. Ю. Цифровое сжатие видеоинформации и звука. Издательство: Дашков и Ко, 2004. - 426 с.
4. Седжвик Р. Фундаментальные алгоритмы на C++. Части 1-4. Анализ. Структуры данных. Сортировка. Поиск. Издательство: ДиаСофт, 2002. - 688 с.
// Количество бит для кода
const int bits_in_register = 16;
// Максимально возможное значение кода
const int top_value = (int)(((long)1 << bits_in_register) - 1);
// Диапазоны
const int first_qtr = (top_value / 4 + 1);
const int half = (2 * first_qtr);
const int third_qtr = (3 * first_qtr);
// Количество символов алфавита
const int no_of_chars = 256;
// Специальный символ Конец файла
const int eof_symbol = (no_of_chars + 1);
// Всего символов в модели
const int no_of_symbols = (no_of_chars + 1);
// Порог частоты для масштабирования
const int max_frequency = 16383;
// Таблицы перекодировки
public int[] index_to_char = new int[no_of_symbols];
public int[] char_to_index = new int[no_of_chars];
// Таблицы частот
public int[] cum_freq = new int[no_of_symbols + 1];
public int[] freq = new int[no_of_symbols + 1];
// Регистры границ и кода
public static long low, high;
public static long value;
// Поддержка побитовых операций с файлами
public static long bits_to_follow;
// Буфер
public static int buffer;
// Количество бит в буфере
public static int bits_to_go;
// Количество бит после конца файла
public static int garbage_bits;
// Указатель на входной файл
FileStream datain;
// Указатель на выходной файл
FileStream dataout;
//--------------------------------------------------------------
// Инициализация адаптивной модели
public void start_model ()
{
int i;
// Установки таблиц перекодировки
for ( i = 0; i < no_of_chars; i++)
{
char_to_index [i] = i + 1;
index_to_char [i + 1] = i;
}
// Установка счетчиков накопленных частот
for ( i = 0; i <= no_of_symbols; i++)
{
freq [i] = 1;
cum_freq[i] = no_of_symbols - i;
}
freq [0] = 0;
}
//------------------------------------------------------------
// Обновление модели очередным символом
void update_model(int symbol)
{
// Новый индекс
int i;
int ch_i, ch_symbol;
int cum;
// Проверка на переполнение счетчика частоты
if (cum_freq[0] == max_frequency)
{
cum = 0;
/* Масштабирование частот при переполнении (если счетчики частот достигли своего максимума, то делим на пополам) */
for (i = no_of_symbols; i >= 0; i--)
{
freq[i] = (freq[i] + 1) / 2;
cum_freq[i] = cum;
cum += freq[i];
}
}
/* Обновление перекодировочных таблиц в случае перемещения символа */
for (i = symbol; freq[i] == freq[i - 1]; i--) ;
if (i < symbol)
{
ch_i = index_to_char[i];
ch_symbol = index_to_char[symbol];
index_to_char[i] = ch_symbol;
index_to_char[symbol] = ch_i;
char_to_index[ch_i] = symbol;
char_to_index[ch_symbol] = i;
}
// Увеличить значение счетчика частоты для символа
freq[i] += 1;
// Обновление значений в таблицах частот
while (i > 0)
{
i -= 1;
cum_freq[i] += 1;
}
}
//------------------------------------------------------------
// Инициализация побитового ввода
void start_inputing_bits ()
{
bits_to_go = 0;
garbage_bits = 0;
}
//------------------------------------------------------------
// Ввод очередного бита сжатой информации
int input_bit ()
{
int t;
// Чтение байта если буфер пуст
if (bits_to_go == 0)
{
buffer = datain.ReadByte();
if (buffer == -1)
{
/* Помещение битов после конца файла, с проверкой небольшого их количества */
garbage_bits += 1;
if (garbage_bits > bits_in_register - 2)
{
Application.Exit();
}
eof = buffer;
}
bits_to_go = 8;
}
// Выдача очередного бита с правого конца
t = buffer & 1;
buffer >>= 1;
bits_to_go -= 1;
return t;
}
//------------------------------------------------------------
// Инициализация побитового вывода
public void start_outputing_bits ()
{
buffer = 0;
bits_to_go = 8;
}
//------------------------------------------------------------
// Вывод очередного бита сжатой информации
public void output_bit(int bit)
{
// Бит - в начало буфеpа
buffer >>= 1;
if (bit == 1)
buffer |= 0x80;
bits_to_go -= 1;
// Вывод полного буфера
if (bits_to_go == 0)
{
dataout.WriteByte((byte)buffer);
bits_to_go = 8;
}
}
//------------------------------------------------------------
// Очистка буфера побитового вывода
public void done_outputing_bits ()
{
dataout.WriteByte((byte)(buffer >> bits_to_go));
}
//------------------------------------------------------------
// Вывод указанного бита и отложенных ранее
public void output_bit_plus_follow(int bit)
{
output_bit(bit);
while (bits_to_follow > 0)
{
output_bit(~bit + 2);
bits_to_follow--;
}
}
//------------------------------------------------------------
// Инициализация регистров границ и кода перед началом сжатия
public void start_encoding()
{
// Полный кодовый интервал
low = 0L;
high = top_value;
bits_to_follow = 0L;
}
//------------------------------------------------------------
// Очистка побитового вывода
public void done_encoding ()
{
/* Вывод двух бит, определяющих четверть, лежащую в текущем интервале */
bits_to_follow++;
if (low < first_qtr)
output_bit_plus_follow (0);
else
output_bit_plus_follow (1);
}
//------------------------------------------------------------
/* Инициализация регистров перед декодированием.
Загрузка начала сжатого сообщения*/
void start_decoding ()
{
int i;
int a;
value = 0L;
// Воод бит для заполнения значения кода
for (i = 1; i <= bits_in_register; i++)
{
a = input_bit();
value = 2 * value + a;
}
// Текущий интервал равен исходному
low = 0L;
high = top_value;
}
//------------------------------------------------------------
// Кодирование очередного символа
public void encode_symbol(int symbol)
{
// Ширина текущего кодового интервала
long range;
range = (long)(high - low) + 1;
// Пересчет значений границ
high = low + (range*cum_freq[symbol - 1]) / cum_freq[0] - 1;
low = low + (range*cum_freq[symbol]) / cum_freq[0];
// Вывод битов
for ( ; ; )
{
// Если в нижней половине
if (high < half)
output_bit_plus_follow(0);
// Если в верхней половине
else if (low >= half)
{
output_bit_plus_follow(1);
low -= half;
high -= half;
}
/* Если текущий интервал содержит середину, то вывод еще одного обратного бита позже */
else if (low >= first_qtr && high < third_qtr)
{
bits_to_follow += 1;
low -= first_qtr;
high -= first_qtr;
}
else
break;
// Расширить текущий рабочий кодовый интервал
low = 2 * low;
high = 2 * high + 1;
}
}
//------------------------------------------------------------
// Декодирование очередного символа
int decode_symbol ()
{
// Ширина интервала
long range;
// Накопленная частота
int cum;
// Декодируемый символ
int symbol;
int a;
// Определение текущего масштаба частот
range = (long) (high - low) + 1;
// Hахождение значения накопленной частоты для value
cum=(int)((((long)(value-low)+1)*cum_freq[0]-1)/ range);
// Поиск соответствующего символа в таблице частот
for (symbol = 1; cum_freq [symbol] > cum; symbol++);
// Пересчет границ
high = low + (range*cum_freq[symbol - 1]) / cum_freq[0] - 1;
low = low + (range * cum_freq [symbol]) / cum_freq [0];
// Удаление очередного символа из входного потока
for (;;)
{
// Расширение нижней половины
if (high < half)
{
}
// Расширение верхней половины
else if (low >= half)
{
value -= half;
low -= half;
high -= half;
}
// Расширение середины
else if (low >= first_qtr && high < third_qtr)
{
value -= first_qtr;
low -= first_qtr;
high -= first_qtr;
}
else
break;
// Увеличение масштаба интервала
low = 2 * low;
high = 2 * high + 1;
// Добавить новый бит
a = input_bit();
value = 2 * value + a;
}
return symbol;
}
//--------------------------------------------------------------
// Собственно адаптивное арифметическое кодирование
public void encode(string infile, string outfile)
{
int ch, symbol;
try
{
dataout = new FileStream(outfile, FileMode.Create);
}
catch (IOException exc)
{
return;
}
try
{
datain = new FileStream(infile, FileMode.Open);
}
catch (FileNotFoundException exc)
{
return;
}
start_model();
start_outputing_bits();
start_encoding();
// Цикл обработки символов
for ( ; ; )
{
try
{
// Чтение исходного символа
ch = datain.ReadByte();
}
catch (Exception exc)
{
return;
}
// Выход при достижении конца файла
if (ch == -1)
break;
// Найти рабочий символ
symbol = char_to_index[ch];
// Закодировать символ
encode_symbol(symbol);
// Обновить модель
update_model(symbol);
}
// Закодировать символ конца файла
encode_symbol(eof_symbol);
// Завершение кодирования
done_encoding();
done_outputing_bits();
dataout.Close();
datain.Close();
}
//------------------------------------------------------------
// Собственно адаптивное арифметическое декодирование
void decode(string infile, string outfile)
{
int ch, symbol;
try
{
dataout = new FileStream(outfile, FileMode.Create);
}
catch (IOException exc)
{
return;
}
try
{
datain = new FileStream(infile, FileMode.Open);
}
catch (FileNotFoundException exc)
{
return;
}
start_model ();
start_inputing_bits ();
start_decoding ();
// Цикл обработки сиволов
for (;;)
{
// Получаем индекс символа
symbol = decode_symbol ();
if (symbol == eof_symbol)
break;
// Получаем декодированный символ
ch = index_to_char [symbol];
// Записываем в выходной файл
dataout.WriteByte((byte)ch);
// Обновляем модель
update_model (symbol);
}
dataout.Close();
datain.Close();
}
Приложение 2. Интерфейс программы
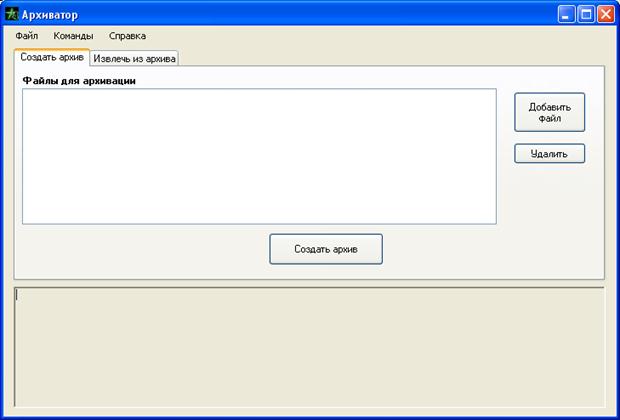
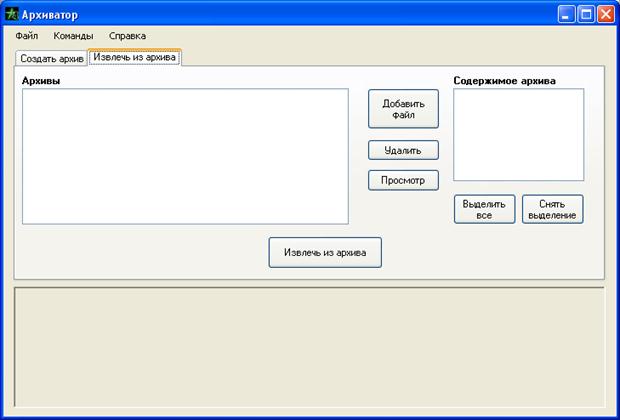
Примечание. Для работы программы необходим Microsoft .NET Framework 2.0.
© 2010 Интернет База Рефератов