
Рефераты по сексологии
Рефераты по информатике программированию
Рефераты по биологии
Рефераты по экономике
Рефераты по москвоведению
Рефераты по экологии
Краткое содержание произведений
Рефераты по физкультуре и спорту
Топики по английскому языку
Рефераты по математике
Рефераты по музыке
Остальные рефераты
Рефераты по авиации и космонавтике
Рефераты по административному праву
Рефераты по безопасности жизнедеятельности
Рефераты по арбитражному процессу
Рефераты по архитектуре
Рефераты по астрономии
Рефераты по банковскому делу
Рефераты по биржевому делу
Рефераты по ботанике и сельскому хозяйству
Рефераты по бухгалтерскому учету и аудиту
Рефераты по валютным отношениям
Рефераты по ветеринарии
Рефераты для военной кафедры
Рефераты по географии
Рефераты по геодезии
Рефераты по геологии
Рефераты по геополитике
Рефераты по государству и праву
Рефераты по гражданскому праву и процессу
Рефераты по делопроизводству
Рефераты по кредитованию
Рефераты по естествознанию
Рефераты по истории техники
Рефераты по журналистике
Рефераты по зоологии
Рефераты по инвестициям
Рефераты по информатике
Исторические личности
Рефераты по кибернетике
Рефераты по коммуникации и связи
Курсовая работа: Приховані марківські процеси
Курсовая работа: Приховані марківські процеси
Міністерство освіти та науки України
Національний університет «Львівська політехніка»
Курсова робота
з дисципліни
Інформаційн нтелектуальні системи
на тему
«Прихован марківські процеси»
Львів 2009
Зміст
1. Постановка проблеми, якій присвячується тема курсової роботи
2. Огляд літератури за тематикою курсової роботи
3. Постановка завдання яке буде виконане у курсовій роботі
4. Існуючі шляхи вирішення задачі
5. Основні результати, які отримані в результат вирішення задачі
6. Місце і спосіб застосування отриманих результатів
7. Програмна реалізація завдання, виконаного у курсовій роботі
7.1 Алгоритм ELVIRS для окремо вимовлених слів
7.2 Алгоритм ELVIRCOS для розпізнавання злитого мовлення
8. Експериментальні результати
9. Список використаної літератури
1. Постановка проблеми, якій присвячується тема курсової роботи
Приховані марківськ процеси (ПМП), специфікація яких була опублікована ще в кінці 60-х років, останнім часом стали дуже популярні. По-перше, математична структура ПМП дуже багата і дозволяє вирішувати математичні проблеми різних галузей науки. По-друге, грамотно спроектована модель дає на практиці гарні результати роботи.
Явища, що відбуваються, можна описувати як сигнали. Сигнали можуть бути дискретними, як письмова мова, або безперервними, як фонограма або кардіограма. Сигнали з постійними статистичними властивостями, називаються стабільними (стаціонарними), а з мінливими - нестабільними (нестаціонарними). Сигнал, може бути чистим, а може й не чистим, з телефонів або зі сторонніми сигналами.
Для опису сигналів часто потрібні математичні моделі. У моделі сигналу на основі його характеристик може бути передбачений певний механізм обробки, що дозволя одержати бажаний вихід при аналізі сигналу. Наприклад, якщо треба облагородити сигнал, спотворений і зашумлений при передачі, ми можемо змоделювати його, і розглянути цю модель не звертаючи увагу на спотворення шумів в сигналі. Моделі дозволяють також генерувати і досліджувати сигнал без його джерела. У цьому випадку, маючи під рукою гарну модель, ми можемо імітувати сигнал і вивчити його з ц мітації.
Моделі дуже успішно застосовуються на практиці, що дозволяє створювати ефективні робоч системи: системи прогнозу, розпізнавання, ідентифікації. Грубо всі моделі можна розділити на детерміністичні та статистичні. Детерміністичні використовуються, якщо відомі фундаментальні характеристики сигналу: сигнал - це синусоїдальна хвиля або, наприклад, сума експонент. У такому випадку досить просто описати подібну модель сигналу - для цього потрібно всього лише підібрати (обчислити) параметри цієї моделі: для синусоїдальної хвилі - це амплітуда, частота, фаза. Другий клас - це статистичні моделі, які, у відповідності зі своєю назвою, використовують в якості основи статистичні характеристики сигналу. Ці модел описують гауссови, пуассоновскі, Марківські процеси, а також подібні до них процесиВ загальному, статистичні моделі описують сигнал як певний випадковий процес, параметри якого можуть бути якісно визначені. [2]
В област розпізнавання мовлення використовуються обидва типи моделей, але ми розглянемо тільки одну, статистичну модель, а саме - приховану Марківську модель (ПММ).[3]
Теорія прихованих Марківських моделей не нова. Її основи опублікував Баум і його колеги в кінц 60-х, початку 70-х років. Тоді ж, на початку 70-х Бейкер і Джелінек з колегами застосували ПММ в розпізнаванні мови.
2. Огляд літератури за тематикою курсової роботи
Виконуючи підготовку до курсової роботи я використовувала такі матеріали
Із матеріалів Вікіпедії (uk.wikipedia.org)- визначення марківського процесу.
Марківський процес — це випадковий процес, конкретні значення якого для будь-якого заданого часового параметру t+1 залежать від значення у момент часу t, але не залежать від його значень у моменти часу t-1, t-2 і т. д.[6]
На сайт www.nbuv.gov.ua-сутність поняття марківського процесу. Прикладом марківського процесу може бути відома дитяча гра, у якій фішки учасників повинні переміститися з початкового пункту А0 ("старт") у кінцевий Ak ("фініш"). Потрапивши в той або інший проміжний пункт AJ, фішка може або наблизитися до фінішу (за рахунок "пільги", передбаченої умовами гри), або видалитися від нього (за рахунок "штрафу").
Статтю Т.В. Грищука «Отримання характеристичної обсервації прихованої марківської моделі». В статті розглядається процес отримання на основі натренованої прихованої модел характеристичної обсервації голосової команди. Ця інформація може використовуватися для підвищення ефективності процесу розпізнання мови. Введено поняття оціночної функції, знаходження максимуму якої дає характеристичну обсервацію.
Вісник НАН України. — 2003. — N 1. Стаття І. Сергієнко, А. Гупал. Стаття в якій описується ланцюг Маркова — проста та економна модель дослідження поведінки об'єктів із залежними ознаками.
Стаття «Алгоритм Витерби для моделей скрытых марковских процессов с неизвестным моментом появления скачка». В цій статті показані результати математичного моделювання для алгоритма Вітербі, за допомогою прихованих марківських процесів.[3]
http://teormin.ifmo.ru/education/machine-learning/notes-06-hmm.pdf Стаття «Приховані марківські моделі». В ній є поняття прихованих марківських процесів, конкретні приклади та пояснюються елементи прихованих марківських моделей. Також пояснюється зміст та вирішення задач прихованих марківських моделей.[5]
http://www.lib.ua-ru.net/diss/cont/9307.html Стаття «Скрытые марковские модели», в якій описується марківські ланцюги та процеси, а також розв`язок задач прихованих марківських моделей.[2]
http://www.genetics.wustl.edu/eddy В цій статті наведений приклад застосування Прихованих марківських моделей як програмного забезпечення для аналізу послідовності білка. HMMER є програмною реалізацією. HMMER1 широко використовується для аналізу ДНК, на додаток до аналізу білків.[1]
3. Постановка завдання яке буде виконане у курсовій роботі
Розглянемо систему, яку можна в будь-який момент часу можна описати одним з N станів, S1, S2,...SN, (мал. 1), де для простоти N = 5. Через певний проміжок часу система може змінити свій стан або залишитися в колишньому стані відповідно до ймовірностям, зазначеним для цих станів. Моменти часу, коли ми реєструємо стан системи ми позначимо як t=1,2,... , а стан в момент часу t - ми позначимо q t. Повний опис розглянутої вище системи, повинно містити поточний стан (в момент часу t) і послідовність всіх попередніх станів, через які пройшла система. В окремих випадках опис системи зводиться до вказівкою поточного та попереднього стану.
![]() (1)
(1)
Крім того, ми також вважаємо що процеси, що протікають у системі, не залежать від часу, про що нам говорить права частина формули (1). Таким чином, систему можна описати безліччю ймовірностей a i j у вигляді
![]()
![]() (2)
(2)
де a i j - це ймовірність переходу з стану S i в стан S j в даний момент часу. Оскільки ці ймовірності характеризують випадковий процес, вони мають звичайні властивості, т. е.
![]() (3.1)
(3.1)
![]() (3.2)
(3.2)
Описаний вище випадковий процес можна назвати відкритою марківською моделю, оскільки вихідний сигнал моделі - це послідовність станів реєструються в часі. Кожен стан відповідає певному (що спостерігається) події. Для того, щоб краще зрозуміти все вищесказане, розглянемо просту марківську модель погоди, у якій буде всього три стану. Передбачається, що ми один раз на день (наприклад, в опівдні), дивимося у вікно і реєструємо в журналі поточний стан погоди. Ми домовилися, що лише один із трьох нижче названих станів в день t ми записуємо в журнал:
- Стан № 1: дощ (або сніг)
- Стан № 2: хмарно, можливий дощ
- Стан № 3: ясно
Матриця ймовірностей зміни погоди A має вигляд
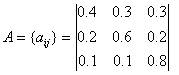
Виходячи з того, що погода в перший
день (t = 1) ясна (стан 3), ми можемо задати собі питання: яка вірогідність
(згідно з нашою моделі), що наступні 7 днів буде саме «зрозуміло - ясно - дощ -
дощ - ясно - Хмарно, можливий дощ - ясно »? Точніше сказати, для ц
послідовності станів O, де ![]() відповідає, t=1,2,...,8, Ми хочемо на основі даної моделі визначити
ймовірність спостереження послідовності O. Ця ймовірність може бути виражена (
обчислено) наступним чином
відповідає, t=1,2,...,8, Ми хочемо на основі даної моделі визначити
ймовірність спостереження послідовності O. Ця ймовірність може бути виражена (
обчислено) наступним чином
![]()
![]() (4)
(4)
це ймовірність того, що початковий стан системи буде Si.
Є й інший цікаве питання, відповідь на яке нам дасть ця модель: яка вірогідність того, що модель збереже свій стан протягом рівно d днів? Ця ймовірність може бути обчислено як ймовірність спостереження такій послідовності
![]()
дає модель, в якій
![]() (5)
(5)
Величина pi (d) - це ймовірність того, що система буде перебувати в стані i рівно d раз поспіль. Відповідно є функція розподілу ймовірності для тривалості перебування системи в одному стані, яка є характеристикою збереження стану для марківських ланцюга. Знаючи величини pi (d) ми можемо обчислити середній час, протягом якого система збереже свій стан (використовуємо формулу математичного очікування):
![]() (6.1)
(6.1)
![]() (6.2)
(6.2)
Очікується, що сонячна погода швидше за все простоїть 5 днів, похмура - 2,5 дні, а от дощова погода, згідно з нашою моделі, імовірніше за все протримається 1,67 дня.
4. Існуючі шляхи вирішення задачі
У описаної марківській моделі кожній фізичній явищу відповідало певний стан моделі. Ця модель, на жаль, занадто обмежена, і їй не під силу рішення багатьох актуальних проблем. У цьому розділі ми розглянемо марківські моделі, у яких спостерігаються послідовність - це результат переходів у відповідності з позначеними ймовірностей. У даному випадку модель (прихована марківська модель) - це результат двох випадкових процесів. Перший - прихований процес - його ніяк не можна зареєструвати, але його можна охарактеризувати за допомогою іншого випадкового процесу, який надає нам набір сигналів - спостерігається послідовність. Проілюструємо цей опис на прикладі підкидання монети.
Приклад монети, яку підкидають. Ви знаходитесь в кімнаті, а за перегородкою - в іншій кімнаті - знаходиться людина, яка підкидає монету. Він не говорить, як саме він підкидає монету, а може він її взагалі лінується підкидали. Він лише говорить вам результат кожного падіння монети: орел чи решка. У цьому й полягає суть прихованого процесу (ви не знаєте, що відбувається з монетою), коли про процесі ви можете судити лише за що спостерігається послідовності
![]() ,
,
де Н - це орел, а Т - це решка.
Як же побудувати приховану марківську модель, що відповідає цій ситуації? Перше питання: скільки станів буде у моделі і що означає кожне стан такої моделі? Припустимо, що ми підкидаємо одну єдину монету, а інших у нас немає. Тоді вибір ми зупинимо на моделі з двома станами, де одне стан означає випадання орла, інше - решка. [1]
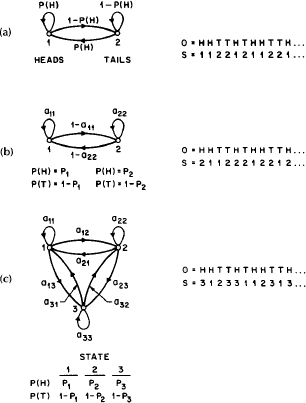
мал. 2.
Три марківськ моделі, які можуть описати експеримент з монетою, що підкидається. (а) 1 монета бере участь у підкиданні, (2) 2 - монети, (3) - три монети.
Ця модель зображена на малюнку 2 (а). У цьому випадку марківських модель є відкритою дине, що ми можемо зробити з цією моделлю - це оптимізувати ймовірність зміни стану. Слід зауважити, що прихована марківських модель, що є аналогом моделі, зображеної на рис. 2 (а), буде представляти собою модель одного стану. В цій моделі єдине стан означає, що підкидана всього лише одна монета.
На наступному малюнку 2 (б) зображена ПММ двох станів. У цьому випадку кожне стан відповіда різним монетам, які підкидають в ході експерименту (наприклад, 1 копійка і 5 рублів). Кожному станом відповідає розподіл ймовірностей між випаданням орла решка, а також матрицею ймовірностей переходів (матрицею переходів), що вказу ймовірність переходу з одного стану в інше. Перехід зі стану в стан згідно з заданим ймовірностям з матриці переходів може здійснюється на основі того ж підкидання монети або на основі будь-якої іншої випадкової події.
На третьому малюнку 2 (в) представлена модель, що враховує той факт, що підкидають три різні монети, причому вибір між ними здійснюється знову ж таки на основ якого-небудь випадкового події.
Тут, як і кожен раз при проектуванні ми задаємося питанням: яка з трьох моделей найкращим чином підходить для опису, що спостерігається послідовності? Добре видно, що перша модель (мал. 2 (а)) має всього лише 1 невідомий параметрМодель для двох монет (мал. 2 (б)) має 4 невідомих параметра І нарешті, модель для трьох монет (мал. 3 (в)) має 9 невідомих параметрів. Таким чином, ПММ з великою кількістю ступенів свободи по суті більш дієздатна, ніж її менші аналоги. Також теоретично доведено (і це ми побачимо далі), що в сучасних умовах існують обмеження на розмір моделей. Більш того, може виявитися, що у випадку, коли людина за стіною підкидає одну єдину монету, ми виберемо модель трьох станів. У такому випадку з'ясовується, що стану системи не відповідають реальним станів за стіною, і, отже, ми використовуємо надлишкову модель.
Приклад кульок у вазах. Зараз ми доповнимо ПММ новими структурними елементами, для того, щоб вона могла вирішувати ряд більш складних завдань. Допоможе нам в цьому приклад з кульками у вазах (мал. 3).

мал. 3. Модель з N станами (вазами) та кульками, кольори яких позначають елементи що спостерігається послідовності.
Припустимо, у нас N скляних прозорих ваз. У кожній вазі - велике число кульок різного кольоруВважаємо, що у нас в кошику лежать кульки M різних кольорів. Фізично це можна представити наступним чином. Людина знаходиться в кімнаті з вазами. Яким-небудь випадковим чином він вибирає будь-яку вазу, простягає руку глибше, витягує м'яч. Колір кулі записується в журнал показань - спостерігається послідовність, і людина кладе шар назад в цю вазу. Потім наша людина вибира нову вазу, і йде до неї, і витягує звідти новий шар, і так далі. В результаті ми отримуємо послідовність кольорів - результат роботи ПММ - спостерігається послідовність.
Очевидно, що приклад кульок у вазах відповідає прихованої марківській моделі, де кожне стан моделі - це обрана ваза, причому в різних ваз різну ймовірність витягти кульку червоного (або іншого) кольору, що відповідає різного розподілу ймовірностей для кожного стану. Те, яка ваза буде обрана наступної, залежить від матриц переходів ПММ, т. е. залежить і від того, у якої вази ми зараз знаходимося.[1]
Елементи прихованої марківської моделі
Наведені вище приклади дають непогане уявлення про ПММ, і про можливі сферах їх застосування. Зараз ми дамо формальне визначення елементів ПММ і зрозумілий, як модель генерує спостережувану послідовність. ПММ визначається наступними елементами:
1. N - загальна
кількість станів в моделі. Незважаючи на те, що стану в ПММ є прихованими, у
багатьох випадках є відповідність між станом моделі і реальним станом процесу. У
прикладі з підкиданням монети кожне стан відповідно до обраної монеті, а в
прикладі з кульками у вазах стан моделі відповідно до обраної вазі. В
загальному, перехід у будь-який обраний стан можливий з будь-якого стану вс
системи (в тому числі й сама в себе); з іншого боку, і це ми побачимо згодом,
лише певні шляхи переходів представляють інтерес у кожної конкретної моделі. Ми
позначимо сукупність станів моделі безліччю ![]() , ,
a поточний стан в момент часу t як q.
, ,
a поточний стан в момент часу t як q.
2. M, кількість
можливих символів у що спостерігається послідовності, розмір алфавіту
послідовності. У випадку з підкиданням монети - це 2 символу: орел і решка; у
випадку з кульками - це кількість кольорів цих самих кульок. Алфавіт що
спостерігається в послідовності ми позначимо як ![]() .
.
3. Матриця
ймовірностей переходів (або матриця переходів) ![]() , де
, де
![]() ,
, ![]() (7)
(7)
ттобто це ймовірність того, що система, що перебуває в стані Si, перейде в стан Sj. Якщо для будь-яких двох станів в моделі можливий перехід з одного стану в інше, то a i j> 0 для будь-яких i, j. В інших ПММ для деяких i, j у нас ймовірність переходу a i j = 0.
4. Розподіл
ймовірностей появи символів у j-тому стані, ![]() , где
, де
, где
, де
![]()
![]()
![]() (8)
(8)
b j (k) - мовірність того, що в момент часу t, система, яка знаходиться в j-му стан (стан Sj), видасть k-тий символ (символ k) в спостережувану послідовність.
5. Розподіл
ймовірностей початкового стану ![]() , где
, де
, где
, де
![]() ,
, ![]() , (9)
, (9)
тобто ймовірність того, Si - це початковий стан моделі.
Сукупність значень N, M, A, B і π - це прихована марківська модель, яка може згенерувати послідовність
![]() (10)
(10)
(де O t один з символів алфавіту V , а T — це кількість елементів в послідовності.
ПММ буду спостережувану послідовність по наступному алгоритмі
1. Вибираємо початковий стан q 1 = S i відповідно до розподілу π
2. Встановлюємо t = 1 .
3. Вибираємо O t = v k відповідно до розподілу b j ( k ) у стані ( S i ).
4. Переводимо модель у новий стан q t + 1 = S j відповідно до матриц переходів a i j з урахуванням поточного стану S i .
5. Встановлюємо час t = t + 1 ; вертаємося до кроку 3, якщо t < T ; інакше — закінчуємо виконання.
Підбиваючи підсумок, можливо помітити, що повний опис ПММ складається із двох параметрів моделі ( N і M ), опису символів спостережуваної послідовності й трьох масивів ймовірностей A , B , і π . Для зручності ми використаємо наступний запис
![]() (11)
(11)
для позначення достатнього опису параметрів моделі.
5. Основні результати, які отримані в результаті вирішення задачі
Відповідно до опису схованої марківської моделі, викладеному в попередньому розділі, існу три основних задачі, які повинні бути вирішені для того, щоб модель могла успішно вирішувати поставлені перед нею задачі.
Задача 1
Дано: спостережувана послідовність і модель λ = ( A , B ,π) . Необхідно обчислити ймовірність P ( O | λ) — імовірність того, що дана спостережувана послідовність побудована саме для даної моделі.
Задача 2
Дано: спостережувана послідовність і модель λ = ( A , B ,π) . Необхідно підібрати послідовність станів системи , що найкраще відповідає спостережуваній послідовності, тобто «пояснює» спостережувану послідовність.
Задача 3
Підібрати параметри моделі λ = ( A , B ,π) таким чином, щоб максимізувати P ( O | λ) .
Задача 1 - це задача оцінки моделі, що полягає в обчисленні ймовірності того, що модель відповідає заданій спостережуваній послідовності. До суті цієї задачі можна підійти й з іншої сторони: наскільки обрана ПММ відповідає заданій спостережуваній послідовності. Такий підхід має більшу практичну цінність. Наприклад, якщо в нас коштує питання вибору найкращої моделі з набору вже снуючих, то рішення першої задачі дає нам відповідь на це питання.
Задача 2 - це задача, у якій ми намагаємося зрозуміти, що ж відбувається в прихованій частин моделі, тобто знайти «правильну» послідовність, що проходить модель. Зовсім ясно, що абсолютно точно не можна визначити цю послідовність. Тут можна говорити лише про припущення з відповідним ступенем вірогідності. Проте для наближеного рішення цієї проблеми ми звичайно будемо користуватися деякими оптимальними показниками, критеріями. Далі ми побачимо, що, на жаль, не існу диного критерію оцінки для визначення послідовності станів. При рішенні друго задачі необхідно кожний раз ухвалювати рішення щодо того, які показники використати. Дані, отримані при рішенні цієї задачі використаються для вивчення поводження побудованої моделі, знаходження оптимальної послідовності її станів, для статистики й т.п. [6]
Рішення задачі 3 складається в оптимізації моделі таким чином, щоб вона якнайкраще описувала реальну спостережувану послідовність. Спостережувана послідовність, по якій оптимізується ПММ, прийнято називати навчальною послідовністю, оскільки за допомогою ми «навчаємо» модель. Задача навчання ПММ - це найважливіша задача для більшості проектованих ПММ, оскільки вона полягає в оптимізації параметрів ПММ на основі навчальної спостережуваної послідовності, тобто створюється модель, що щонайкраще описує реальні процеси.
Для кращого розуміння розглянемо все вищесказане на прикладі системи, призначеної для розпізнавання мови. Для кожного слова зі словника W ми спроектуємо ПММ із N станами. Кожне слово зокрема ми представимо як послідовність спектральних векторів. Навчання ми будемо вважати завершеним, коли модель із високою точністю буде відтворювати ту саму послідовність спектральних векторів, що використалася для навчання моделі. У такий спосіб кожна окрема ПММ буде навчатися відтворювати яке-небудь одне слово, але навчати цю модель треба на декількох варіантах проголошення цього слова; тобто наприклад три чоловіки (кожний по-своєму) проговорюють слово «собака», а потім кожне сказане слово конвертується в упорядкований за часом набір спектральних векторів, і модель навчається на основі цих трьох наборів. Для кожного окремого слова проектуються відповідні моделі. Спершу вирішується 3-я задача ПММ: кожна модель настроюється на «проголошення» певного слова зі словника W , відповідно до заданої точності. Для того щоб інтерпретувати кожний стан спроектованих моделей ми вирішуємо 2-ую задачу, а потім виділяємо ті властивості спектральних векторів, які мають найбільша вага для певного стану. Це момент тонкого настроювання моделі. А вже після того, як набір моделей буде спроектований, оптимізований і навчений, варто оцінити модель на предмет її здатності розпізнавати слова в реальному житті. Тут ми вже вирішуємо 1-ую задачу ПММ. Нам дається тестове слово, представлене, зрозуміло, у вигляді спостережуваної послідовності спектральних векторів. Далі ми обчислюємо функцію відповідності цього тестового слова для кожної моделі. Модель, для якої ця функція буде мати найбільше значення, буде вважатися моделлю названого слова.
6. Місце і спосіб застосування отриманих результатів
Для розпізнавання мовлення із великих словників для ізольовано (або дискретно) вимовлених слів на початку 90-х років було розроблено декілька систем з достатньо гарними показниками. Потім увага дослідників перенеслася на розпізнавання злитого мовлення, де використовувалися статистичні залежності в порядку слів, що дозволяло передбачити поточне розпізнаване слово на основі кількох попередніх слів. Розроблені статистичні методи прогнозу дозволили значно зменшити кількість альтернатив при розпізнаванні, що у свою чергу дозволило розробляти системи розпізнавання з сумарним обсягом у десятки тисяч слів, хоча на кожному кроц розпізнавання розглядалося декілька сотень альтернатив.
Проте, існу необхідність побудови систем розпізнавання мови з великою кількістю альтернатив за умови, що немає яких-небудь обмежень на порядок розпізнаваних слів.
Наприклад, при керуванні комп'ютера голосом неможливо передбачити наступне слово на основ декількох попередніх, оскільки це визначається логікою керування комп'ютера, а не властивостями тексту. З іншого боку існує необхідність значного збільшення обсягу словника для того, щоб охопити всі синоніми однієї і тієї ж команди, оскільки користувачу, звичайно, важко запам'ятати тільки один варіант назви команди.
Другий приклад пов'язаний з диктуванням текстів. Використання таких систем, звичайно, обмежено такими текстами, що аналогічні тим текстам, для яких накопичувалися статистики. Крім іншого, додаткове редагування набраного тексту вимагає наявності всіх слів в активному словнику.
Таким чином, снують додатки, де бажано мати словник максимально великого розміру, щоб у майбутньому охопити всі слова даної мови.
Додаткова нформація для обмеження числа альтернатив може бути одержана безпосередньо з мовного сигналу. Для цього пропонується виконати пробне розпізнавання за допомогою фонетичного стенографа. Одержана послідовність фонем формує потік запитів до бази даних для отримання невеликої кількості слів, які могли б входити в словник розпізнавання, що дозволяє значно скоротити кількість альтернатив для розпізнавання.[3]
Наступні розділи описують новий двопрохідний алгоритм. Спочатку представлена базова система для порівняння із запропонованою системою розпізнавання мови. Потім описані два варіанти алгоритму для ізольованих слів та злитого мовлення. Виконан експерименти показують ефективність запропонованих методів.
Запропонований метод можна застосувати в будь-якій системі розпізнавання мовлення, де представлені фонеми, і можна сформувати процедуру фонетичного стенографа. У даній роботі як базова система використовується інструментарій на основі прихованих Марківських моделей (Hidden Markov Model - HMM)
Попередня обробка мовленнєвого сигналу
Мовний сигнал перетвориться в послідовність векторів ознак з інтервалом аналізу 25 мс і кроком аналізу 10 мс. Спочатку мовний сигнал фільтрується фільтром високих частот з характеристикою P(z) =1-0.97z-1 та застосовується вікно Хемінга. Швидке перетворення Фурьє переводити часовий сигнал у спектральний вигляд. Спектральн коефіцієнти усереднюються з використанням 26 трикутних вікон, розташованими в мел-шкалі. 12 кепстральних коефіцієнтів обчислюються за допомогою зворотного косинусного перетворення.
Логарифм енерг додається як 13-й коефіцієнт. Ці 13 коефіцієнтів розширюються до 39-мірного вектора параметрів шляхом дописування першої та другої різниць від коефіцієнтів сусідніх за часом. Для обліку впливу каналу застосовується віднімання середнього кепстра.
Акустична модель
Акустичні модел відображають характеристики основних одиниць розпізнавання. Для акустичних моделей використовуються приховані Марківські моделі з 64 сумішами Гауссівських функцій щільності імовірності. 47 російських контекстно-незалежних фонем моделюються трьома станами Марківського ланцюга з пропусками. Словник транскрипцій створюється автоматично з орфографічного словника з використанням множини контекстно-залежних правил.[3]
Показники базово системи
Акустичні модел навчалися на вибірці з 12 тис. звукових записів із словника в 2037 слів, вимовлених одним диктором. Розпізнавання проводилося на комп'ютері P-IV 2.4 ГГц.
Для перевірки надійності розпізнавання мови було накопичено 1000 окремо вимовлених слів тим же диктором. Послівна надійність розпізнавання і середній час розпізнавання однієї секунди мови для різних розмірів словника приведені в таблиці 1. Оскільки час розпізнавання лінійно залежить від розміру словника, то для словника в 1987 тис. слів його можна оцінити приблизно в 2300 секунд.
Таблиця 1: Результати розпізнавання окремо вимовлених слів базовою системою
| Об'єм словника, тис. | 1 | 15 | 95 |
| Надійність, % | 99.9 | 97.9 | 94.7 |
| Час, сек. | 1 | 16 | 115 |
Для перевірки надійності розпізнавання злитого мовлення було додатково накопичено 1000 фраз з числами від 0 до 999. Послівна надійність розпізнавання і середній час розпізнавання однієї секунди мови для різних розмірів словника приведені в таблиці 2.
Таблиця 2: Результати розпізнавання злитого мовлення базовою системою
| Об'єм словника, тис. | 1 | 15 | 95 |
| Надійність, % | 98.0 | 96.5 | 92.6 |
| Час, сек. | 2.1 | 36 | 205 |
7. Програмна реалізація завдання, виконаного у курсовій роботі
7.1 Алгоритм ELVIRS для окремо вимовлених слів
Архітектура
Архітектура системи розпізнавання ELVIRS (Extra Large Vocabulary Speech recognition based on the Information Retrieval) показана на мал. 4. Такі блоки з базової системи як обчислення ознак і акустичних моделей використовуються перед першим проходом алгоритму.
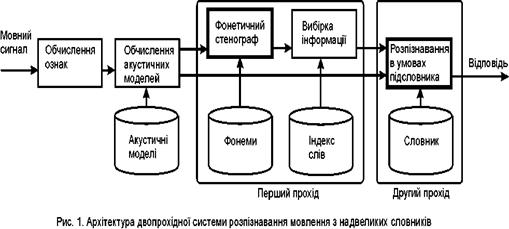
Також на другому проході використовується звичайне порівняння образів в умовах обмеженого словника
Зміни торкаються введення першого проходу алгоритму, де фонетичний стенограф використовується для отримання послідовності фонем. Потім процедура вибірки інформації створю обмежений словник (підсловник) для другого проходу алгоритму.
Фонетичний стенограф
Алгоритм фонетичного стенографа[2] створює фонетичну послідовність для мовного сигналу незалежно від словника. Для цього будується деякий автомат породження фонем, який може синтезувати всі можливі моделі мовних сигналів для послідовност фонем. Потім використовується пофонемне розпізнавання для невідомого мовного сигналу.
Використовуються ті ж контекстно-незалежні моделі фонем, що і в базовій системі розпізнавання.
Процедура отримання підсловника з бази даних
Заздалегідь в процесі навчання із словника транскрипцій створюється індекс від трійок фонем до транскрипцій. Ключем індексу є трійка фонем. Таким чином, таблиця індексу складається з M3 входжень, де M є число фонем в системі. Кожне входження в таблицю містить список транскрипцій, в які входить трійка фонем ключа входження.
Процес отримання підсловника ілюструється. Вихід фонетичного стенографа ділиться на трійки фонем з зрушенням на одну фонему. Трійка фонем стає запитом до бази даних. Зараз використовується простий запит, коли він в точності співпадає з трійкою фонем. В майбутньому пропонується використовувати відстань Levensteine для врахування вставок, видалень та замін в послідовності фонем. Таким чином, послідовність фонем продукує потік запитів до бази даних.
Відповідь на один запит складається із списку транскрипцій, в які дана трійка фонем входить. Цей список копіюється в підсловник для другого проходу алгоритму. Наступний запит з потоку додає нову порцію транскрипцій, при цьому підраховується кількість повторень для того, щоб можна було обчислити ранг слова в підсловнику.
Всі транскрипц в одержаному підсловнику упорядковуються згідно рангу слова (лічильнику повторень). Перші N транскрипцій заносяться в остаточний підсловник для другого проходу алгоритму. Таким чином, підсловник для розпізнавання містить транскрипції з найвищими рангами і число транскрипцій не перевищує фіксованого числа N.
Алгоритм ELVIRS
Алгоритм ELVIRS складається з двох частин. Підготовчий етап:
• Підготувати словник для розпізнавання.
• Вибрати множину фонем і створити транскрипції слів із словника за допомогою правил.
• Створити ндекс бази даних від трійок фонем до транскрипцій.
• Навчити акустичні моделі по накопичених мовних сигналах.
Етап розпізнавання:
• Застосувати фонетичний стенограф до вхідного сигналу для отримання послідовності фонем.
• Поділити послідовність фонем на трійки фонем із зрушенням в одну фонему.
• Створити запити до БД з трійок фонем
• Одержати списки транскрипцій за допомогою запитів до індексу бази даних.
• Упорядкувати транскрипції до їх рангу.
• Вибрати перш N транскрипцій з найвищими рангами як підсловник для розпізнавання.
• Розпізнати вхідний мовний сигнал в умовах обмеженого підсловника.[5]
Інформаційна оцінка імовірності правильного формування підсловника
Відповідь розпізнавання фонетичного стенографа може розглядатися як правильна послідовність фонем, пропущена через канал з шумом. Позначимо у відповід фонетичного стенографа правильну фонему як 1, а зіпсовану шумом як 0. Нехай мовірність появи 1 в двійковому наборі дорівнює u. Імовірність P знайти в двійковому наборі довжини n підряд k одиниць і більше можна обчислити за допомогою наступного рекурентного виразу:
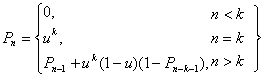 (12)
(12)
В таблиці показана мовірність P знайти в двійкових наборах підряд три і більше 1 при деяких довжинах n та імовірності u. Середня довжина транскрипцій дорівнює приблизно 8 мовірність правильного знаходження фонеми у відомих реалізацій приблизно дорівнює 85%. При таких значеннях імовірність знайти правильне слово в підсловнику дорівнює 0.953.
Таблиця 3: Імовірність знайти підряд три і більше 1 в двійковому наборі довжини n
| 0.75 | 0.8 | 0.85 | 0.9 | |
| 6 | 0.738 | 0.819 | 0.890 | 0.948 |
| 7 | 0.799 | 0.869 | 0.926 | 0.967 |
| 8 | 0.849 | 0.908 | 0.953 | 0.982 |
| 9 | 0.887 | 0.937 | 0.971 | 0.991 |
| 10 | 0.915 | 0.956 | 0.981 | 0.995 |
7.2 Алгоритм ELVIRCOS для розпізнавання злитого мовлення
Архітектура
Після отримання списків транскрипцій використовується додаткова процедура формування графа слів для злитого мовлення, яка створює мережу слів для другого проходу алгоритму.
Формування графа слів
Процес створення графа слів показаний на мал. 5. Мережа слів починається з вершини S закінчується у вершині F. Кожна трійка фонем з відповіді фонетичного стенографа породжує проміжну вершину з номером синхронним до часу появи цієї трійки фонем. З іншого боку кожна трійка фонем стає запитом до індексу бази даних, який повертає список транскрипцій. Транскрипції вставляються між проміжними вершинами так, щоб трійки фонем опинилися в одній колонці по вертикалі.
У випадку, коли відбувається перетин транскрипцій одного слова, породженими різними трійками фонем, тоді ранги цих транскрипцій збільшуються на одиницю. Для кожного моменту часу можна підрахувати число транскрипцій тих, що входять у цей проміжок часу.
Для зменшення складності графа слів використовується обмеження N для кількості слів в кожен момент часу. При цьому віддаляються слова з малими рангами.
Оскільки граф слів формується зліва направо можна проводити його формування у реальному час з затримкою, яка дорівнює максимальній довжині транскрипції.
Відповідь фонетичного стенографа
# с г в а + с н , ъ й е #
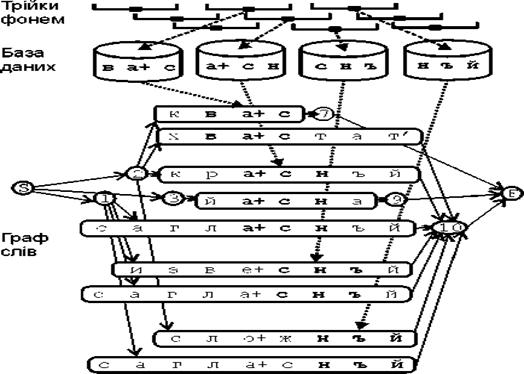
мал. 5. Формування графа слів для злитого мовлення
Алгоритм ELVIRCOS
Алгоритм ELVIRCOS складається з двох частин. Підготовчий етап такої ж, як і в алгоритмі ELVIRS. Етап розпізнавання:
• Застосувати фонетичний стенограф до вхідного сигналу для отримання послідовності фонем.
• Поділити послідовність фонем на трійки фонем із зрушенням в одну фонему.
• Створити запити до БД з трійок фонем
• Одержати списки транскрипцій за допомогою запитів до індексу бази даних.
• Створити граф слів для злитого мовлення.
• Упорядкувати транскрипції до їх рангу.
• Вибрати перш N транскрипцій з найвищими рангами як підсловник для розпізнавання.
• Розпізнати вхідний мовний сигнал для графа злитої мови в умовах обмеженого підсловника.[5]
8. Експериментальні результати
Для того, щоб ввести перший прохід алгоритму ELVIRCOS в базову систему розпізнавання мови були зроблені необхідні зміни в інструментарії і проведені декілька експериментів.
Для окремо вимовлених слів досліджувався вплив обмеження N на середній час і надійність розпізнавання мовлення для словників різного об'єму, що наведені в таблиці 4. Результати показують корисність обмеження N для словників великих об'ємів, що дозволяє додатково скоротити час розпізнавання при незначному погіршенн надійності.
В цілому одержано значне скорочення часу розпізнавання в сотні разів при відносно невеликому (близько 5%) погіршенні надійності в порівнянні з базовою системою розпізнавання. Погіршення надійності має хороший збіг з оцінкою імовірності правильного формування підсловника.
Таблиця 4: Результати алгоритму ELVIRS
|
Об'єм словника, тис Обмеження N на розмір підсловника |
15 | 95 | 1987 | |||
| Надійн. % | Час, сек. | Надійн. % | Час, сек. | Надійн. % | Час, сек. | |
| 50 | 92.2 | 1.4 | 81.0 | 1.4 | 69.2 | 1.6 |
| 200 | 94.6 | 1.6 | 87.6 | 2.1 | 76.0 | 1.9 |
| 500 | 95.5 | 1.9 | 90.1 | 2.5 | 80.0 | 3.3 |
| 1000 | 96.0 | 2.1 | 90.7 | 3.1 | 82.7 | 4.4 |
| 2000 | 96.0 | 4.4 | 92.0 | 4.5 | 84.8 | 6.8 |
| 5000 | 96.0 | 4.6 | 92.9 | 8.3 | 86.4 | 12.0 |
Для злитого мовлення були проведені попередні експерименти, в яких розглядався випадок, коли обмеження N співпадало з розміром словника. У таблиці 5 наведені показники надійності для різних розмірів словника.
Таблиця 5: Результати алгоритму ELVIRCOS
| Об'єм словника, тис | 15 | 95 | 1987 |
| Надійність, % | 85.3 | 84.9 | 83 |
| Час, сек | 2.3 | 9.4 | 160 |
Зменшення середнього часу розпізнавання не настільки значне, як у випадку окремо вимовлених слів, оскільки деякі послідовності фонем від фонетичного стенографа породжують графи слів дуже великої розмірності. Сподіваємося, що введення обмеження N істотно зменшить час розпізнавання.[5]
Слід підкреслити важливість підходів вибірки інформації з баз даних для процесу розпізнавання мови. Показано, що додаткове джерело інформації, одержане з аналізу послідовності фонем від фонетичного стенографа, дозволило значно скоротити простір пошуку в алгоритмі розпізнавання мови. Це дозволило створити системи розпізнавання мови, що охоплюють практично всі слова мови.
Список використаної літератури
1. http://www.genetics.wustl.edu/eddy
2. http://www.lib.ua-ru.net/diss/cont/9307.html
3. http://www.nbuv.gov.ua/e-journals/VNTU/2007-1/ukr/07gtvmco.pdf
4. http://www.ru.wikibooks.org/wiki/
5. http://www.teormin.ifmo.ru/education/machine-learning/notes-06-hmm.pdf
6. http://www.uk.wikipedia.org
© 2010 Интернет База Рефератов